




 本文介绍了如何使用Python从皮皮虾等短视频平台下载无水印视频,通过解析分享的H5链接获取JSON数据,从而得到视频的下载地址。请注意,该方法适用于头条系视频,但不建议频繁使用。
本文介绍了如何使用Python从皮皮虾等短视频平台下载无水印视频,通过解析分享的H5链接获取JSON数据,从而得到视频的下载地址。请注意,该方法适用于头条系视频,但不建议频繁使用。
背景
浏览短视频的时候,看到自己喜欢的视频,喜欢保存下来,但是会携带短视频的水印,于是开始思索怎么下载无水印的版本。通过分享的h5链接发现了无水印的版本也在响应中。
以皮皮虾为例
基本流程:
- 打开分享的h5链接
- 自动重定向一个新的页面
- 根据视频的id会去请求一个地址,并且返回json。视频下载地址就在这个json中
直接看代码(简单代码)
# 原理:
# 1. 根据分享的h5 链接 https://h5.pipix.com/s/JepPPqf/
# 2. 302重定向到某个地址,需要先获取location地址
import json
import os
from contextlib import closing
import requests
def download_pipixia(file_path, h5_url):
if not os.path.exists(file_path):
os.mkdir(file_path)
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'}
# link = 'https://h5.pipix.com/s/JepPPqf/'
url = requests.get(h5_url, headers=headers, allow_redirects=False).headers['Location']
print('重定向地址:', url)
# https://h5.pipix.com/item/6825834042638752008?xxxxxxx
# 3. 提取里面到视频id
video_id = url[url.rindex('/') + 1:url.index('?')]
print('提取视频id:', video_id)
# 访问地址 https://h5.pipix.com/bds/webapi/item/detail/?item_id=6825834042638752008&source=share 获取json
json_url = 'https://h5.pipix.com/bds/webapi/item/detail/?item_id=' + video_id + '&source=share'
print('下载地址解析:', json_url)
ele_json = json.loads(requests.get(json_url, headers=headers).text)
real_url = ele_json['data']['item']['video']['video_high']['url_list'][0]['url']
print('获取下载地址:', real_url)
# 4. 下载视频/Users/xxx/Downloads/pipixia
file_name = file_path + '/' + ele_json['data']['item']['content'] + '.mp4'
print('视频名称:', file_name)
with closing(requests.get(real_url, headers=headers, stream=True)) as response:
chunk_size = 5120
content_size = int(response.headers['content-length'])
data_count = 0
with open(file_name, "wb") as video_file:
for data in response.iter_content(chunk_size=chunk_size):
video_file.write(data)
data_count = data_count + len(data)
now_jd = (data_count / content_size) * 100
print("\r 下载进度:%d%%(%d/%d) - %s" % (now_jd, data_count, content_size, file_name), end=" ")
print("下载完成")
if __name__ == '__main__':
file_path = '/Users/xxx/Downloads/pipixia'
h5_url = 'https://h5.pipix.com/s/JesSVDD/'
download_pipixia(file_path, h5_url)
运行效果
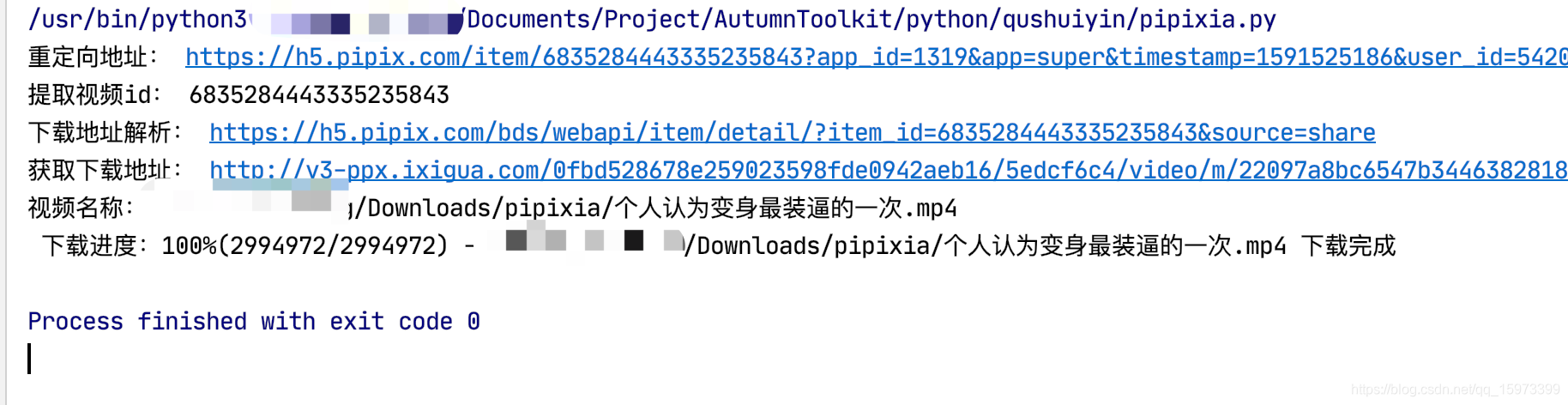
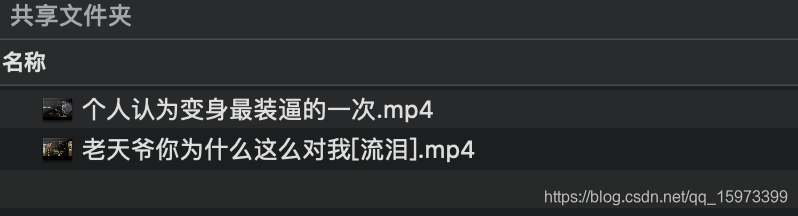
完成下载了。
最后:不要频繁使用!
总结
头条系的视频均可以按照这个方法来。目前可行!


















 2355
2355





 到【灌水乐园】发言
到【灌水乐园】发言







