






 本文深入解析Windows环境下宽字符与窄字符的概念,详细介绍了Unicode与ASCII字符的底层处理方式,以及如何使用MultiByteToWideChar和WideCharToMultiByte函数进行字符串转换。通过实例演示了窄字符到宽字符的转换过程。
本文深入解析Windows环境下宽字符与窄字符的概念,详细介绍了Unicode与ASCII字符的底层处理方式,以及如何使用MultiByteToWideChar和WideCharToMultiByte函数进行字符串转换。通过实例演示了窄字符到宽字符的转换过程。
目录
基本概念
宽字符:Unicode字符,双字节
窄字符:ASCII字符,单字节
Windows中所有的底层函数都是Unicode编码
COM组件必须使用Unicode编码(COM组件可以理解为DLL,主要是用于代码重用);
比如在Windows API中:
FindWindowW和FindWindowA
W的意思为wide(宽)
A的意思为ASCII
在Windows.h中有一个UNICODE宏
底层调用宽字节版本
窄字节版本仅作编码转换
下面是2个字符串转换的函数:
MultiByteToWideChar
UINT uCodePage //代码页
DWORD dwFlags //保留为0
PCSTR pMultibyteStr //待转换字符
int cchMultiByte //字符串长度(-1获取待转换字符串长度)
PWSTR pWideCharStr //转换后存储的缓存区
int cchWideChar //缓冲大小WideCharToMultiByte
UINT uCodePage //代码页号
DWORD dwFlags //保留为0
PCSTR pWidebyteStr //待转换字符串
int cchWideByte //字符串长度(-1获取待转换字符串长度)
int cchMultiChar //缓冲区大小
PCSTR pDefaultChar //转换失败备用字符
PBOOL pfUsedDefaultChar //转换是否成功
这里顺便提一下,在Windows.h中有很多微软自定义的宏
比如
BOOL,他实际上是typedef int BOOL
HANDLE,他实际上是typedef void *HANDLE
演示
下面举个窄字符转成宽字符的例子!
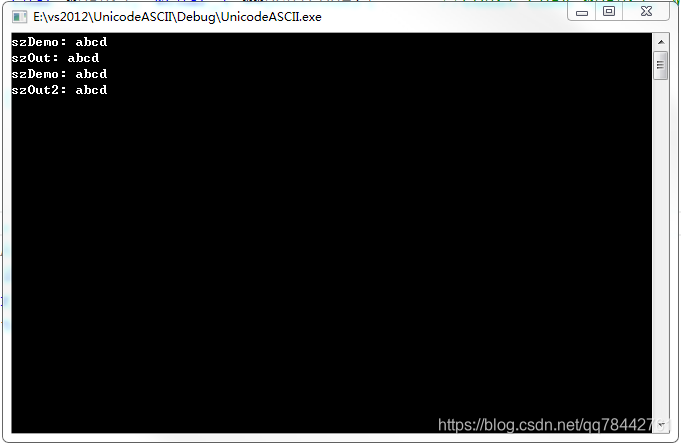
程序运行截图如下:
#include <stdio.h>
#include <Windows.h>
bool UnicodeToAnsi(const char *pAnsi, wchar_t **pUnicode){ //const CHAR *pAnsi, WCHAR *pUnicode
BOOL a;
HANDLE b;
if(nullptr == pAnsi){
return false;
}
//如果有一个size变量,那么会让人知道这是一个size
int nSize = sizeof(pAnsi);
size_t szAnsi = MultiByteToWideChar(CP_ACP, 0, pAnsi, -1, nullptr, 0);
*pUnicode = new wchar_t[szAnsi];
if(szAnsi == MultiByteToWideChar(CP_ACP, 0, pAnsi, szAnsi, *pUnicode, szAnsi)){
return true;
}
return false;
}
int main(int *argc, int *argv[]){
char *szDemo = "abcd"; //单字节 窄字节 ASCII字节
wchar_t *wszDemo = L"abcd"; //双字节 宽字节 Unicode字节
wchar_t szOut[MAXBYTE] = {0}; //这种写法有一定的危险,溢出攻击
//窄字符转宽字符
MultiByteToWideChar(CP_ACP, 0, szDemo, strlen(szDemo), szOut, strlen(szDemo));
printf("szDemo: %s\n", szDemo); //窄字符 区别字符串为 \0
printf("szOut: %ws\n", szOut); //宽字符 区分字符串为 0000
//可以先获取长度在进行分配,现在来封装一下
wchar_t *szOut2 = nullptr;
UnicodeToAnsi(szDemo, &szOut2);
printf("szDemo: %s\n", szDemo);
printf("szOut2: %ws\n", szOut2);
delete szOut2;
getchar();
return 0;
}程序运行截图如下:
项目打包下载地址:
https://github.com/fengfanchen/CAndCPP/tree/master/UnicodeAndASCII


















 3054
3054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











