




 Apache Flink是用于处理有界和无界数据的分布式处理引擎,强调状态计算。有界流有明确的开始和结束,而无界流无限持续。有状态流式处理允许在计算过程中积累和维护状态,以处理如时间窗口等场景。Flink通过全局一致的checkpoint实现实时容错,并支持Event-Time处理,利用watermarks处理乱序事件。此外,Flink还提供灵活的部署选项和多层级API,方便开发者进行流处理应用开发。
Apache Flink是用于处理有界和无界数据的分布式处理引擎,强调状态计算。有界流有明确的开始和结束,而无界流无限持续。有状态流式处理允许在计算过程中积累和维护状态,以处理如时间窗口等场景。Flink通过全局一致的checkpoint实现实时容错,并支持Event-Time处理,利用watermarks处理乱序事件。此外,Flink还提供灵活的部署选项和多层级API,方便开发者进行流处理应用开发。
文章目录
1.什么是Flink?
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams.
Apache Flink是一个分布式处理引擎的框架,用对“有界数据“ 和“无界数据”流进行状态计算
1.1有界流和无界流怎么理解?
- Unbounded streams :have a start but no defined end.
- Bounded :streams have a defined start and end.
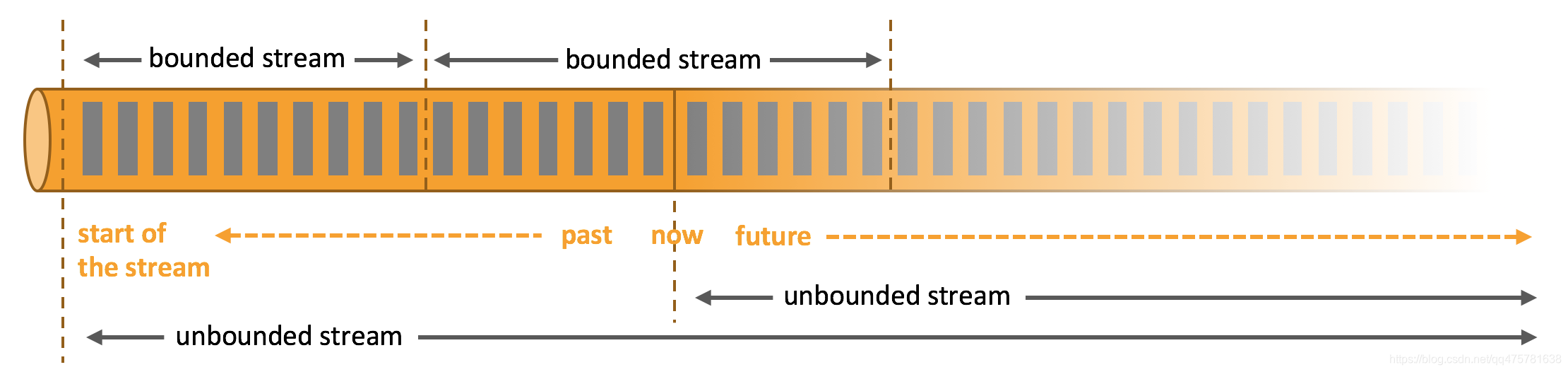
简单的来说,无界流就是有开始,没有结束。有界流就是有开始,也有结束
1.2 有状态流式处理怎么理解?
传统流计算处理方式:
以时间划分,划分成一个一个批次,用批次运算引擎spark或mr去处理。但是举个例子:
- a. 要实现每一个小时事件A->事件B conversion出现的次数
- b. 而且假设A发生在3点59分,B发生在4点01分
- c .先接受到B,在接收到A
那么上述的情况如何处理呢?
上述情况下就需要有一个中间状态保存中间计算结果,而且累积的状态会影响结果的产出。这就是我所理解的状态计算。
综上总结下状态流计算的特点:
- a.有办法累积和维护大量的状态
- b.有办法依据时间决定所有的数据都接收完毕才产生结果,可以
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









