




 本文围绕Zookeeper和Dubbo展开。介绍了Zookeeper选举机制,即半数同意产生新leader;阐述了集群读写请求处理方式,leader处理写请求,follower和observer处理读请求。还说明了基于Zookeeper的分布式锁实现。此外,讲解了Dubbo架构及接口不兼容升级的处理方法。
本文围绕Zookeeper和Dubbo展开。介绍了Zookeeper选举机制,即半数同意产生新leader;阐述了集群读写请求处理方式,leader处理写请求,follower和observer处理读请求。还说明了基于Zookeeper的分布式锁实现。此外,讲解了Dubbo架构及接口不兼容升级的处理方法。
1、简单介绍下zk的选举机制。
- 发生时机:整个集群群龙无首的时候(1.服务启动 2.leader宕机之后)
- 选举机制:集群中,半数zkServer同意,则产生新的leader(搭建集群时,一般都是奇数个) 三台服务器,多允许一台宕机,四台服务器,也是多允许一台宕机
- 选举算法: 对比(myid,zxid),先对比zxid,zxid大者(大表示数据越新)胜出,成为leader,如果zxid一致,则myid 大者成为leader
以一个简单的例子来说明整个选举的过程.
假设有五台服务器组成的zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的.假设这些服务器依序启动,来看看会发生什么.
- 服务器1启动,此时只有它一台服务器启动了,它发出去的报没有任何响应,所以它的选举状态一直是LOOKING状态
- 服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以id值较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1,2还是继续保持LOOKING状态.
- 服务器3启动,根据前面的理论分析,服务器3成为服务器1,2,3中的老大,而与上面不同的是,此时有三台服务器选举了它,所以它成为了这次选举的leader.
- 服务器4启动,根据前面的分析,理论上服务器4应该是服务器1,2,3,4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它只能接收当小弟的命了.
- 服务器5启动,同4一样,当小弟.
2、zk集群是如何处理读写请求的?
- leader:作为整个zk集群写请求的唯一处理者,并负责进行投票的发起和决议,更新系统的状态。
- follower:接收客户端请求,处理读请求,并向客户端返回结果;将写请求转给 Leader;在选举 Leader过程 中参与投票。
- observer:可以理解为无选举投票权的 Flollower,其主要是为了协助 Follower 处理更多的读请求。如果 Zookeeper 集群的读请求负载很高,或者客户端非常非常多,多到跨机房,则可以设置一些 Observer 服务 器,以提高读取的吞吐量。
3、分布式原理及如何实现?
1、实现原理:
基于zookeeper瞬时有序节点实现的分布式锁,其主要逻辑如下(该图来自于IBM网站)。大致思想即为:每个客户端对某个功能加锁时,在zookeeper上的与该功能对应的指定节点的目录下,生成一个唯一的瞬时有序节点。判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。
2、优点
锁安全性高,zk可持久化
3、缺点
性能开销比较高。因为其需要动态产生、销毁瞬时节点来实现锁功能。
4、实现
可以直接采用zookeeper第三方库curator即可方便地实现分布式锁
4、dubbo的架构是怎样的?
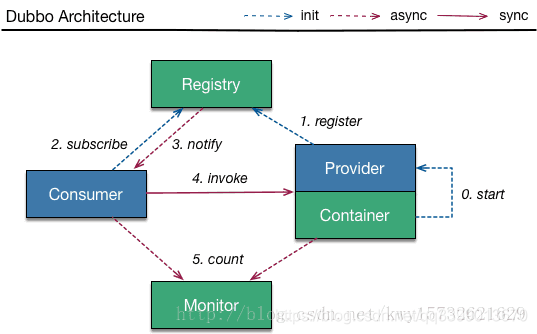
0.容器启动,加载war包;
1.provider启动时,会把所有接口注册到注册中心
2.consumer启动时,订阅providers
3.订阅内容变更时,会推送订阅的信息
4.启动时,建立长连接,然后进行数据通信,consumer启动时,异步连到provide,用netty来发送. 具体调用哪一个provide,是基于软负载均衡算法的,选其中一台,若调用失败,就会选另一台了
5.consumer,provider启动后,后台会启动定时器,发送统计数据给monitor
服务的提供方就是生产者,服务的调用方就是消费者。
当别人需要调用我们的服务(方法)的时候,我们在服务方的提供方Provider写一个来提供该服务;当我们需要调用其他服务时,需要在Consumer来调用一个服务。
5、dubbo接口不兼容升级怎么处理?
- 当一个接口实现,出现不兼容升级时,可以用版本号过渡,版本号不同的服务相互间不引用。
- 可以按照以下的步骤进行版本迁移 在低压力时间段,先升级一半提供者为新版本 ,再将所有消费者升级为新版本 然后将剩下的一半提供者升级为新版本
一旦服务提供者指定了版本,那么所有的服务消费者也是需要去指定相应的版本 - 建议:暴露服务的时候,好都指定下服务的版本,方便后续接口的不兼容升级

















 559
559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









