



 本文详细介绍了如何使用Spark处理复杂嵌套的Json数据,包括使用explode函数展开数组,解决提取嵌套字段时的常见错误,并展示了get_json_object函数的有效应用。
本文详细介绍了如何使用Spark处理复杂嵌套的Json数据,包括使用explode函数展开数组,解决提取嵌套字段时的常见错误,并展示了get_json_object函数的有效应用。
Spark 读取嵌套Json文件的方法
写此问题,我参考了很多现有的帖子说明,综合了各方的方法,我以我的实际操作过程,来说明使用哪种方法最为合适:
附参考网页
Stack Overflow:
How to read the multi nested JSON data in Spark [duplicate]
https://stackoverflow.com/questions/48663448/how-to-read-the-multi-nested-json-data-in-spark
BIG DATUMS
http://bigdatums.net/2016/02/12/how-to-extract-nested-json-data-in-spark/
砖厂 databricks
Complex and Nested Data
https://docs.databricks.com/spark/latest/dataframes-datasets/complex-nested-data.html

如下是我的探索过程:
给出一条嵌套json文件(关键信息,以模糊化处理,请理解),请关注读取过程
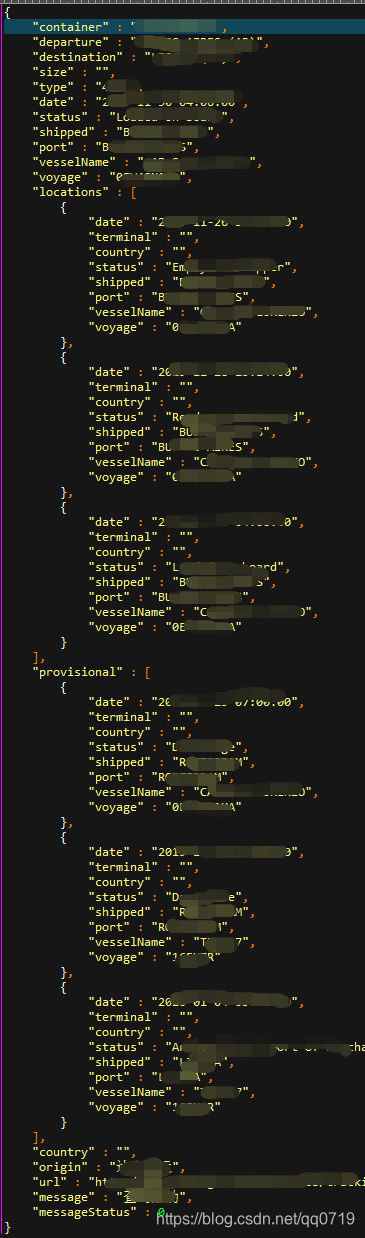
下面给出关键代码:
select(
trim($"container").alias("container_id"),
trim($"type").alias("type"),
trim($"destination").alias("destination"),
//利用explode函数,把locations数组数据进行展开
explode($"locations").alias("locations")
)结果如下

再读取locations内的嵌套数据,参考给出的方法 使用诸如 "locations.date" 或者 col("locations.date") 。Spark均提示有报错,提示
Can't extract value from locations#29
下面给出探索过程的代码截屏
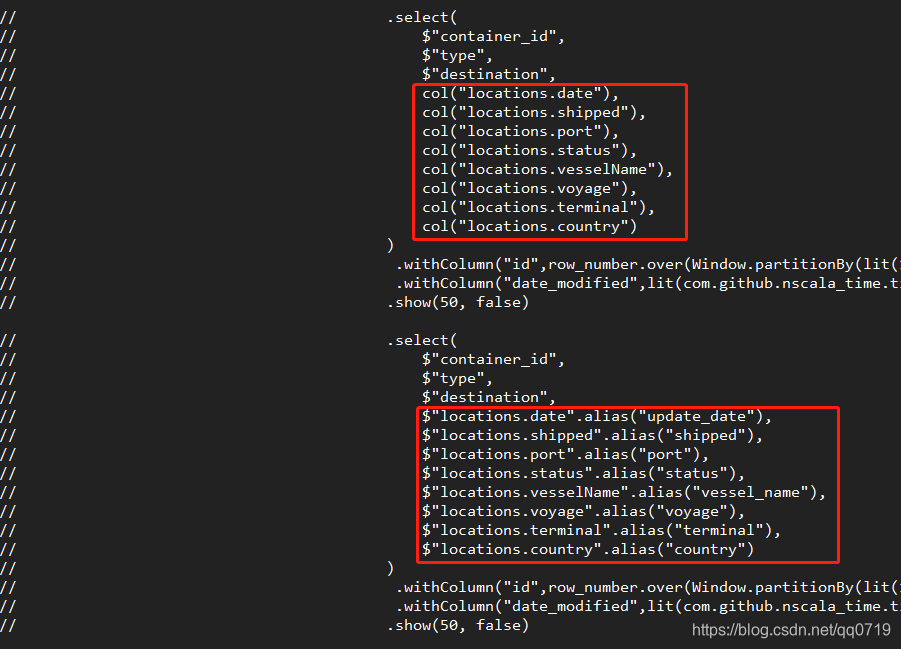
提示报错
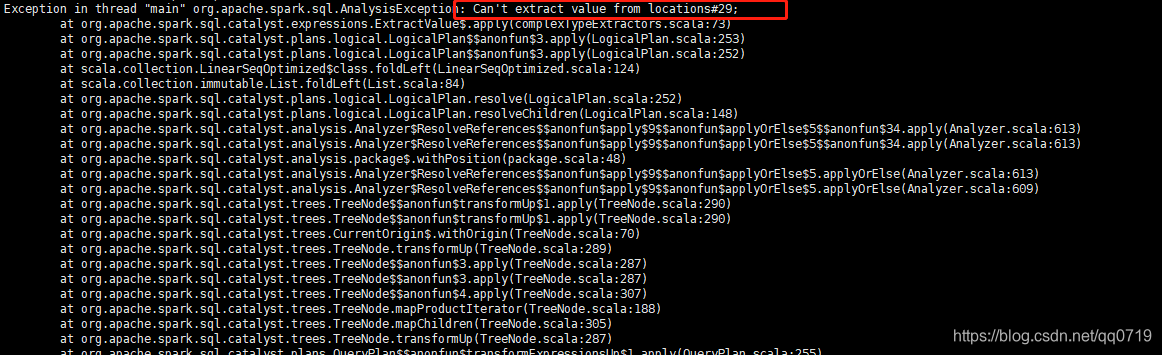
综合砖厂给出的方法,使用 get_json_object() 函数,成功提取locations的数据
给出关键代码
.select(
$"container_id",
$"type",
$"destination",
get_json_object($"locations", "$.date").alias("update_date"),
get_json_object($"locations", "$.shipped").alias("shipped"),
get_json_object($"locations", "$.port").alias("port"),
get_json_object($"locations", "$.status").alias("status"),
get_json_object($"locations", "$.vesselName").alias("vessel_name"),
get_json_object($"locations", "$.voyage").alias("voyage"),
get_json_object($"locations", "$.terminal").alias("terminal"),
get_json_object($"locations", "$.country").alias("country")
)
.withColumn("id",row_number.over(Window.partitionBy(lit(1)).orderBy(lit(1))).cast(LongType) )
.withColumn("date_modified",lit(com.github.nscala_time.time.Imports.LocalDate.today.toDateTimeAtCurrentTime().toString()).cast("timestamp"))得出的数据如下

所以,参考砖厂的官方文档最好。
https://docs.databricks.com/spark/latest/dataframes-datasets/complex-nested-data.html
此贴来自汇总贴的子问题,只是为了方便查询。
总贴请看置顶帖:
pyspark及Spark报错问题汇总及某些函数用法。
https://blog.youkuaiyun.com/qq0719/article/details/86003435

















 1993
1993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









