







 本文介绍了使用Scrapy框架创建爬虫的过程,包括理解Scrapy的架构,创建首个爬虫工程,编写工程文件,解析网页数据,并展示了如何处理翻页和数据存储。文章还提及了辅助工具Chrome插件的使用,以及Scrapy中的item、pipeline和settings配置。
本文介绍了使用Scrapy框架创建爬虫的过程,包括理解Scrapy的架构,创建首个爬虫工程,编写工程文件,解析网页数据,并展示了如何处理翻页和数据存储。文章还提及了辅助工具Chrome插件的使用,以及Scrapy中的item、pipeline和settings配置。
前言
本期文章正式开始我们的爬虫开发之旅吧,在这个资本主义的时代我们还是要随大流。Scrapy框架作为爬虫领域的一大宠儿,今天就熟悉它的开发模式并用它编写我们第一个爬虫
1. Scrapy工厂之美
在开始爬虫编写之前按照基本的礼仪,来!将镜头给我们的主角!看看官方的架构图
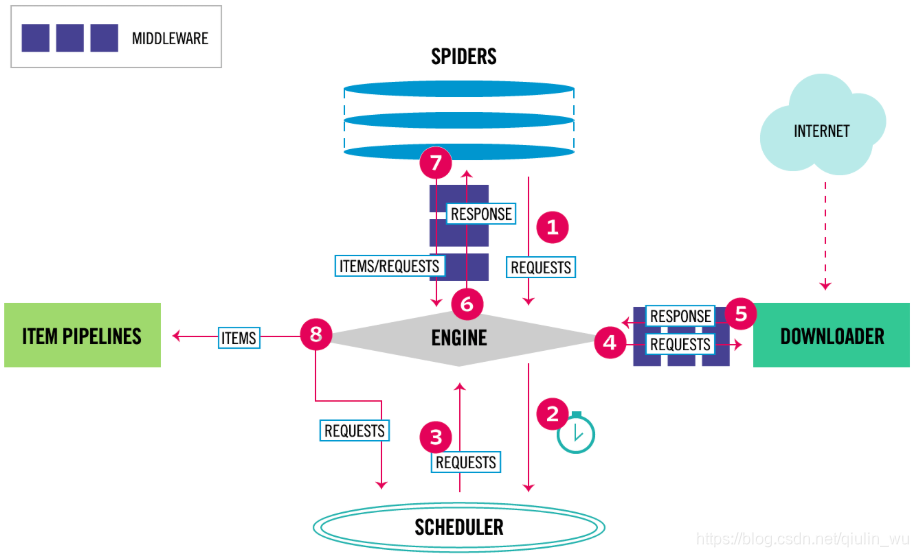
说到爬虫就不得不提起它了,因为它能够提升爬虫的开发效率,从而让我们更好的实现爬虫。大家都知道工厂里面的流水线生产就好比Scrapy框架的工作流程。
它是一个为了采集网页数据、抽取结构化数据而基于Pythony编写的应用框架,框架封装并且包含:Request异步调度处理、Downloader多线程下载器、Selector解析器的Xpath提取功能、Twisted框架的异步处理。对于网站爬取的速度还是非常快的
说到这里可能会有一些小伙伴会问:既然已

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











