







 本文详细介绍Python爬虫的三个核心步骤:使用Requests获取网页内容,利用XPath解析数据,以及通过Pandas将数据存入MySQL数据库。此外,还介绍了三款主流的网页数据采集工具:火车采集器、八爪鱼和集搜课,以及数据运维的日志采集和前端埋点统计方法。
本文详细介绍Python爬虫的三个核心步骤:使用Requests获取网页内容,利用XPath解析数据,以及通过Pandas将数据存入MySQL数据库。此外,还介绍了三款主流的网页数据采集工具:火车采集器、八爪鱼和集搜课,以及数据运维的日志采集和前端埋点统计方法。
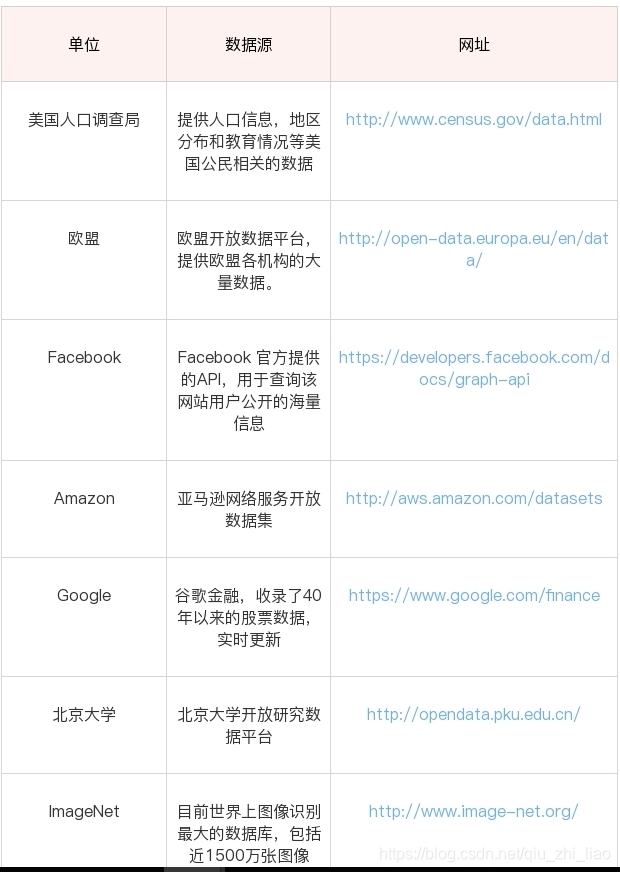
python爬虫会经历三个过程:
1,使用Requests爬取内容。
2,使用xpath解析内容
3,使用pandas保存数据,将数据存储在mysql数据库中
常用的软件爬虫:
1,火车采集器,使用绝大多数网页,网页中能看到的内容都可以采集
2,八爪鱼,免费的采集模板适合电商,生活服务,社交媒体,论坛;云采集,配置好采集任务,就可以交给八爪鱼云端进行采集---八爪鱼一共5000台服务器,采集速度远超过本地采集。还可以自动切换ip。
3,集搜课,完全可视化操作,缺点就是没云服务器,速度慢!
日志采集:
1,数据运维人员需要做的。
埋点:
统计代码可以自己写,也可以找第三方;比如友盟,Goole Analysis,Talkingdata--前端埋点


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









