




下面是学习了莫烦大佬 sklearn 教程的笔记,是供我自己查阅的,不是很详细,介意的勿看~ 莫烦大佬的教程链接在最后一点学习资料里面。
这是目录
一、下载与安装
使用命令:pip install -U scikit-learn 或者 conda install scikit-learn
二、选择合适的机器学习方法
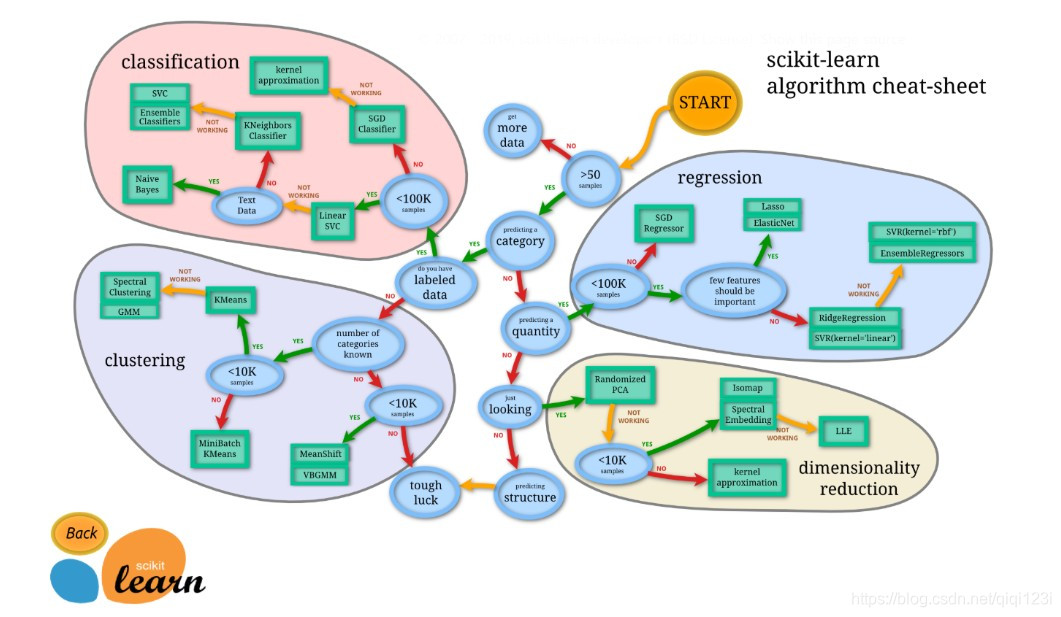
三、通用的学习模式
得到数据集,划分数据集,对训练集进行训练,对测试集进行预测;
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
iris = datasets.load_iris() #加载数据集
iris_X = iris.data #得到数据集的数据部分
iris_y = iris.target #得到数据集的标签部分
print("数据集前2行:\n",iris_X[:2]) #打印前两行数据
print("标签前2行:\n",iris_y[:2]) #打印前两行数据
X_train,X_test,y_train,y_test = train_test_split(iris_X,iris_y,test_size=0.3,random_state=2020) #划分数据集和标签为训练集和测试集,测试集比例为0.3,random_state表示固定划分结果
knn = KNeighborsClassifier() #KNN分类器
knn.fit(X_train,y_train) #进行训练
print("预测结果:\n",knn.predict(X_test)) #得到预测结果
print("实际结果:\n",y_test)
得到结果:

四、sklearn 的 datasets 数据库
使用 datasets 里面的函数都会返回一个字典一样的对象,里面至少包括两项:
- 第一项:key = data,value = 形状为n_samples * n_features 的数据集
- 第二项:key = target,value = 长度为n_samples的numpy数组,包含目标值
使用 datasets 库可以:
1、引入已有的数据集,包括玩具数据集、大的真实数据集
scikit-learn 内置有一些小型标准数据集(7 个),不需要从某个外部网址下载任何文件,比如常用的鸢尾花数据集 load_iris()、波士顿房价数据集 load_boston(),都是以 load 开头的函数。scikit-learn 提供加载较⼤数据集的⼯具,并在必要时下载这些数据集,这些函数都以fetch开头的函数。
from sklearn import datasets
loaded_data = datasets.load_boston()
data_X = loaded_data.data #如上解释,第一项得到数据集
data_y = loaded_data.target #如上解释,第二项得到目标值
print(data_X.shape) #(506,13)
2、利用 dataset 库自己创建数据集,可以按照自己的想法,去随机生成想要的数据集,比如可以用于回归的数据集,可以用于分类的数据集,可以用于聚类的数据集。
X,y = datasets.make_regression(n_samples=100,n_features=1,
n_targets=1,noise=10,random_state=2020) #n_samples表示样本数量,n_features表示特征数量,n_targets表示目标的数量,noise表示噪音大小
plt.scatter(X,y)#X和y
plt.show()
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 963
963

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









