






 数据湖的数据摄取层是核心,负责处理多样化的数据流和结构。Apache Flink作为开源流处理框架,以其高吞吐、低延迟、精确一次性处理等特性在数据处理中脱颖而出,尤其适合需要高效实时分析的场景。
数据湖的数据摄取层是核心,负责处理多样化的数据流和结构。Apache Flink作为开源流处理框架,以其高吞吐、低延迟、精确一次性处理等特性在数据处理中脱颖而出,尤其适合需要高效实时分析的场景。
一、数据湖背景中的数据摄取层
数据摄取层是数据湖的一个核心功能层,如果需要处理来自不同应用的流式和批量数据,则该层至关重要。
1、数据摄取层
数据摄取指的是获取或导入数据用于中间处理或存储到数据库的过程。
数据摄取层的一些特性:
- 能以简单、快捷的方式处理输入的数据
- 能处理多种不同的数据流
- 能够处理多种数据结构
- 集成了多种持久化存储机制
- 支持多种传输协议
- 能与多种不同的系统或技术连接
2、数据摄取层技术路线
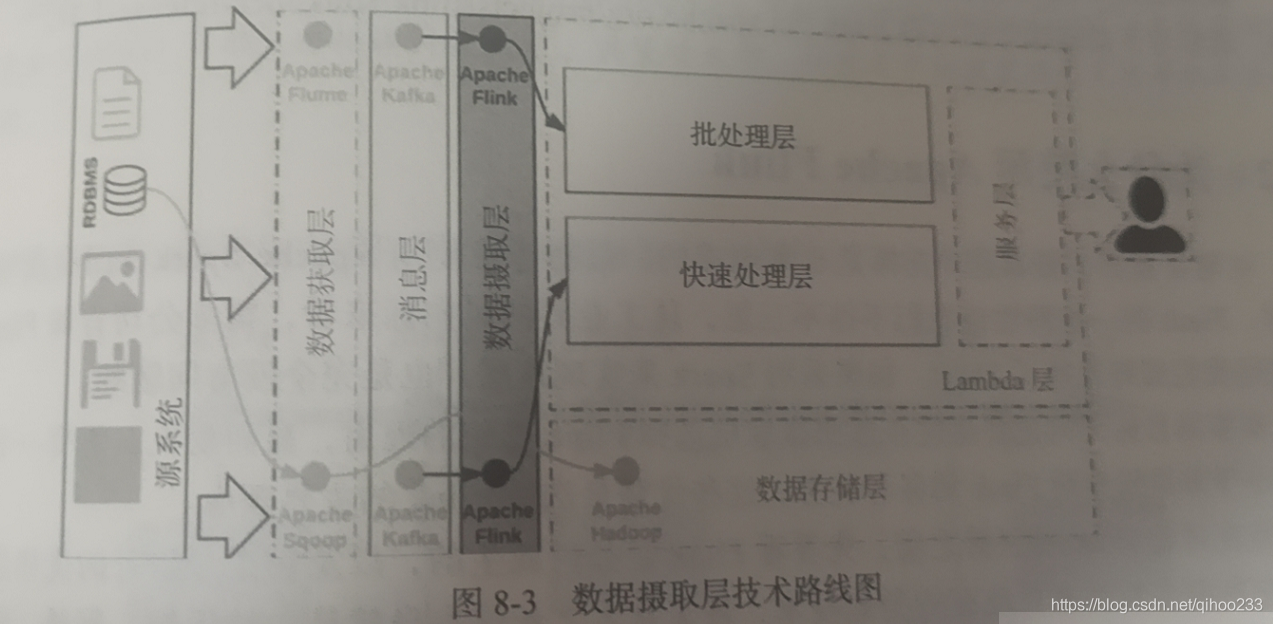
3、什么是apache Flink
apache Flink 是一个开源的分布式流式处理框架,能够满足各类应用的高吞吐、高可用、精确的数据处理要求。
二、为什么使用apache Flink
当然Spark也可以满足该需求,但是Flink相较于spark还是有很多优势的:
- 抽象层次较高且简单易用的api
- 依靠flink的多项内置特性进行快速的轻量级数据处理
- 能够接入每个流式数据,并在其之上执行所需分析
- 低延迟的数据处理
- 支持精准的一次性处理
- 高吞吐
- 容错
- 易于配置
- 开源
- 对延迟抵达或乱序数据流提供精确的处理结果
- 天然有状态

















 1334
1334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









