






收藏:
模型建立:http://blog.youkuaiyun.com/happyer88/article/details/45936107
变量求解:http://blog.youkuaiyun.com/happyer88/article/details/46405399/
变分推断:http://blog.youkuaiyun.com/happyer88/article/details/46438111/
模型参数:http://blog.youkuaiyun.com/happyer88/article/details/46723941
Gaussian LDA: http://blog.youkuaiyun.com/u011414416/article/details/51168242
LDA的rethink,对变分一直理解不能,对推断也知道的不多,现在自己要把盘子图推出来,难上加难,只好重新复习一遍。
引用:http://blog.youkuaiyun.com/happyer88/article/details/45936107
LDA的过程不赘述。引入隐变量z和θ,此处引入隐变量z是为了后面使用EM算法求解模型参数
α,β 时能简化计算,而引入隐变量θ 则是在主题分布(是一个多项分布)之上加一层Dirichlet分布(与多项分布共轭),可以保证一篇文档有多个主题。此处选择Dirichlet分布是因为主题zn 服从多项分布,而Dirichlet分布和多项分布是共轭分布,在以后的计算中会带来很多便利。所谓共轭,指的就是先验分布和后验分布的形式相同:
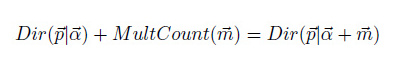
给定α,β,根据文档生成的过程,可以得到,主题分布的参数θ,N个主题的集合z,N个单词的集合w,的联合分布:
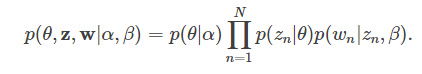
要消掉式中的隐变量θ,z,需对连续型变量θ 求积分,对离散型变量z 求和,得到文档w 的边缘分布:
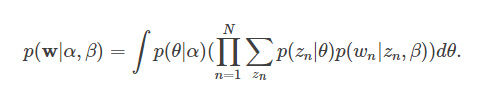
那么就可以通过求乘积进一步得到文档集D的边缘分布
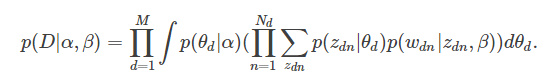
模型的参数是α,β,我们还引入了两个隐变量θ,z,接下来要做的就是消掉隐变量,求解参数,确定LDA模型。

















 229
229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









