



 为应对数据量和请求激增,滴滴自研Fusion-NewSQL存储系统,基于分布式KV存储,兼容MySQL协议,支持二级索引,实现高吞吐、低延迟的大规模数据存储与读写。解决了分库分表带来的Schema变更难题,保障业务灵活性。
为应对数据量和请求激增,滴滴自研Fusion-NewSQL存储系统,基于分布式KV存储,兼容MySQL协议,支持二级索引,实现高吞吐、低延迟的大规模数据存储与读写。解决了分库分表带来的Schema变更难题,保障业务灵活性。
Fusion-NewSQL 是由滴滴自研的在分布式 KV 存储基础上构建的 NewSQL 存储系统。Fusion-NewSQL 兼容了 MySQL 协议,支持二级索引功能,提供超大规模数据持久化存储和高性能读写。
一. 遇到的问题
滴滴的业务快速持续发展,数据量和请求量急剧增长,对存储系统等压力与日俱增。虽然分库分表在一定程度上可以解决数据量和请求增加的需求,但是由于滴滴多条业务线(快车,专车,两轮车等)的业务快速变化,数据库加字段加索引的需求非常频繁,分库分表方案对于频繁的 Schema 变更操作并不友好,会导致 DBA 任务繁重,变更周期长,并且对巨大的表操作还会对线上有一定影响。同时,分库分表方案对二级索引支持不友好或者根本不支持。
鉴于上述情况,NewSQL 数据库方案就成为我们解决业务问题的一个方向。
二. 开源产品调研
最开始,我们调研了开源的分布式 NewSQL 方案:TiDB。虽然 TiDB 是非常优秀的 NewSQL 产品,但是对于我们的业务场景来说,TiDB 并不是非常适合,原因如下:
我们需要一款高吞吐,低延迟的数据库解决方案,但是 TiDB 由于要满足事务,2pc 方案天然无法满足低延迟(100ms 以内的 99rt,甚至 50ms 内的 99rt)
我们的多数业务,并不真正需要分布式事务,或者说可以通过其他补偿机制,绕过分布式事务。这是由于业务场景决定的。
TiDB 三副本的存储空间成本相对比较高。
我们内部一些离线数据导入在线系统的场景,不能直接和 TiDB 打通。
基于以上原因,我们开启了自研符合自己业务需求的 NewSQL 之路。
三. 我们的基础
我们并没有打算从 0 开发一个完备的 NewSQL 系统,而是在自研的分布式 KV 存储 Fusion 的基础上构建一个能满足我们业务场景的 NewSQL。Fusion 是采用了 Codis 架构,兼容 Redis 协议和数据结构,使用 RocksDB 作为存储引擎的 NoSQL 数据库。Fusion 在滴滴内部已经有几百个业务在使用,是滴滴主要的在线存储之一。
Fusion 的架构图如下: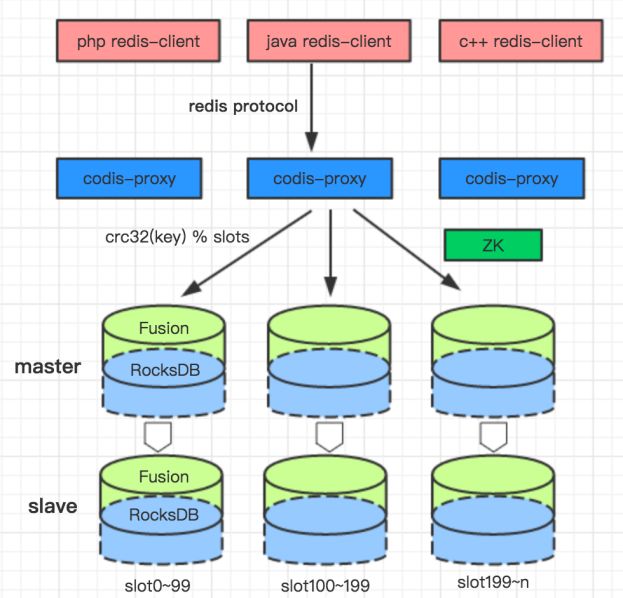
有了一个高并发,低延迟,大容量的存储层后,我们要做的就是在之上构建 MySQL 协议以及二级索引。
需求

综合考虑大多数用户对需求,我们整理了我们的 NewSQL 需要提供的几个核心能力:
高吞吐,低延迟,大容量
兼容 MySQL 协议及下游生态
支持主键查询和二级索引查询
Schema 变更灵活,不影响线上服务稳定性。
架构设计
Fusion-NewSQL 由下面几个部分组成:
1. 解析 MySQL 协议的 DiseServer
架构图如下: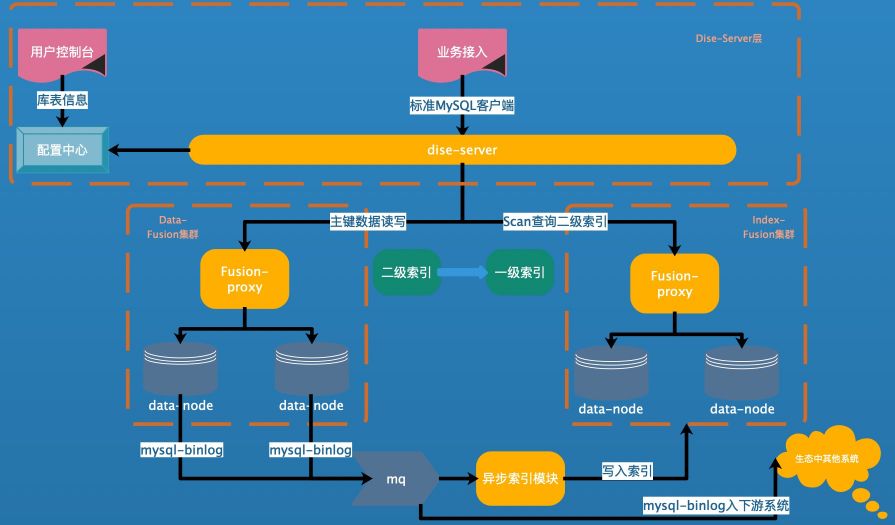
技术挑战及方案
1.SQL 表转 Hashmap
MySQL 的表结构数据如何转成 Redis 的数据结构是我们面临的第一个问题。
如下图:
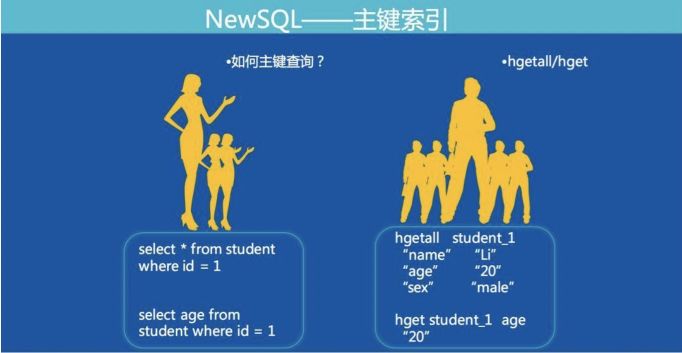
1. 唯一索引:
Key: table_indexname_indexColumnsValue Value: Rowkey
2. 非唯一索引:
Key: table_indexname_indexColumnsValue_Rowkey Value:null

2. 数据和索引一致性
因为数据和索引分别存储在不同 Fusion 集群,数据和索引的一致性保证就成了 Fusion-New 系统面临的一个关键点,在没有分布式事务的情况下,我们当前选择了保证数据索引的最终一致性。用户写入数据在数据集群中开启 RocksDB 的单机事物,同时按链接保序,这样数据流入 MQ 的时候就是有序的。异步模块从 MQ 中消费出来再批量写入到索引集群,整个流程就保证的索引数据的构建与数据集群真实的顺序一致。当然,这中间存在一个时间窗口的数据不一致,这个时间取决于 MQ 的吞吐能力。
3. 二级索引查询
下面是一个使用二级索引查询数据的案例:
如下图: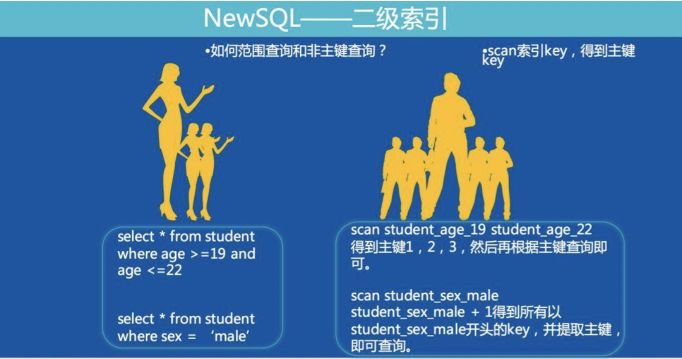
根据上面索引数据的格式可以看到,scan 范围的时候,前缀必须固定,映射到 SQL 语句到时候,意味着 where 到条件中,范围查询只能有一个字段,而不能多个字段。
比如:
架构图如下: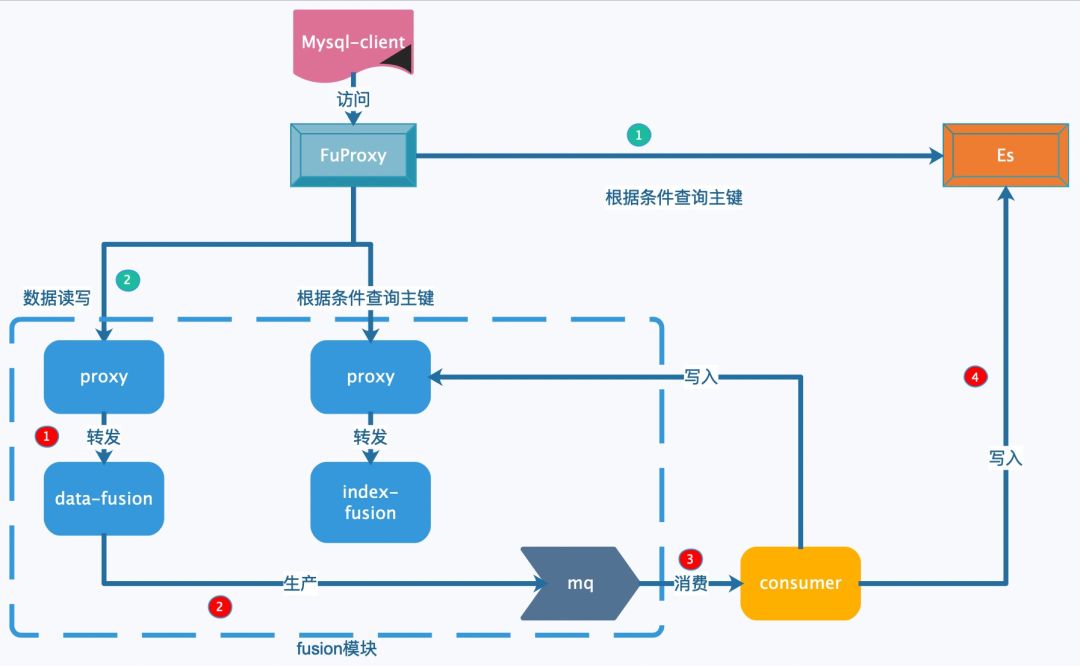
4. 生态构建
一个单独的存储产品解决所有问题的时代早已经过去,数据孤岛是没有办法很好服务业务的,如何与滴滴现有个各个数据系统打通数据,成了我们必须面对的问题。下面分数据流出到其他系统和从其他系统导入两个方面来阐述 Fusion-NewSQL 的数据流动方案。
4.1. Fusion-NewSQL 到其他存储系统
Fusion-NewSQL 是一个新系统,没办法短时间让各个数据系统为我们做适配。既然 Fusion-NewSQL 已经有了 Schema 信息,那么通过兼容 MySQL 的 Binlog 格式,将 Fusion-NewSQL 在数据链路中伪装成 MySQL,就可以直接使用 Mysql 的下游数据流动链路。这样的方式用最小的工作量最大程度做到了兼容。
4.2.Hive 到 Fusion-NewSQL
Fusion-NewSQL 还支持将离线的 Hive 表中的数据通过 Fusion-NewSQL 提供的 FastLoad(DTS)工具,将 Hive 表数据转入到 Fusion-NewSQL,满足离线数据到在线的数据流动。
如果用户自己完成数据流转,一般会扫描 Hive 表,然后构建 MySQL 的写入语句,一条条将数据写入到 Fusion-NewSQL,
流程如下面这样: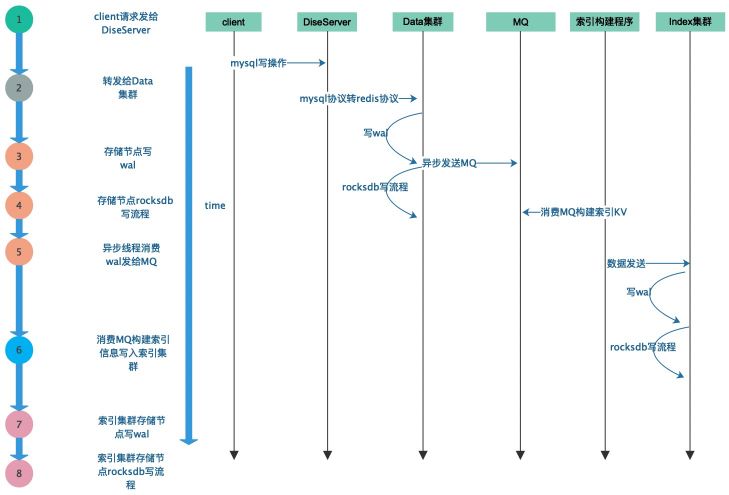
1. 每条 Hive 数据都要经过较长链路,数据导入耗时较长。
2. 离线平台的数据量大,吞吐高,数据导入直接大幅提升在线系统的 QPS,对在线系统的稳定性有较大影响。
从上面的痛点可以看出来,主要的问题是离线数据导入使用了在线系统复杂的 IO 链路。所以如何绕过在线的长 IO 链路,做批量导入就成了解决这个问题的关键。我们设计了 Fastload 数据导入平台,绕过在线 IO 路径
流程如下: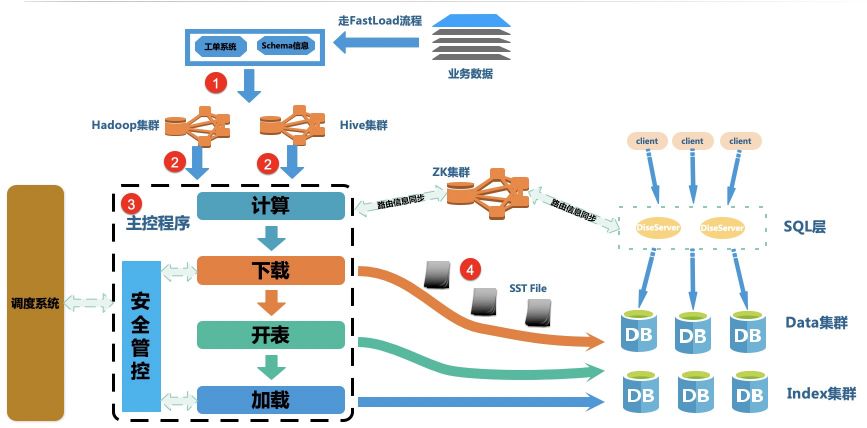
总结
通过解决上面的技术点,我们用了较小的代价,构建了一个基于 KV 存储的 NewSQL 系统,并且快速将 Fusion-NewSQL 系统接入到滴滴整体的数据链路中。虽然这不是一个完备的 NewSQL 系统,但已经可以满足大多数业务场景的需要,切实实现了 20% 工作量满足 80% 功能的需求。当前 Fusion-NewSQL 已经接入订单、预估、账单、用户中心、交易引擎等核心业务,总的数据如下图:

后续工作
有限制的事物支持,比如让业务规划落在一个节点的数据可以支持单机跨行事务;
实时索引替代异步索引,满足即写即读。目前已经有一个写穿 + 补偿机制的方案,在没有分布式事务的前提下满足正常状态的实时索引,异常情况下保证数据索引最终一致的方案;
更多的 SQL 协议和功能支持。

















 2303
2303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









