



本文从互联网收集并整理了推荐系统的架构,其中包括一些大公司的推荐系统框架(数据流存储、计算、模型应用),可以参考这些资料,取长补短,最后根据自己的业务需求,技术选型来设计相应的框架。后续持续更新并收集。。。
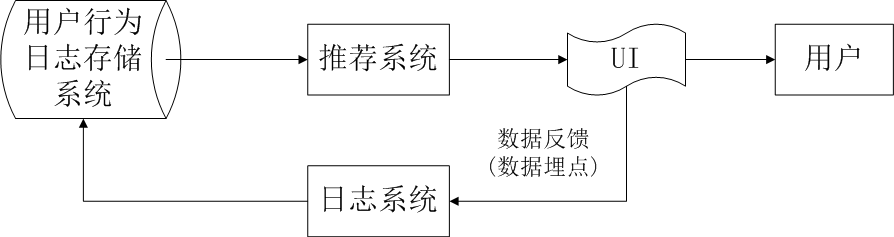
图1
界面UI那一块包含3块东西:1) 通过一定方式展示推荐物品(物品标题、缩略图、简介等);2) 给的推荐理由;3) 数据反馈改进个性化推荐;
关于用户数据的存放地方:1)数据库/缓存用来实时取数据;2) hdfs文件上面;
抽象出来的三种推荐方式:
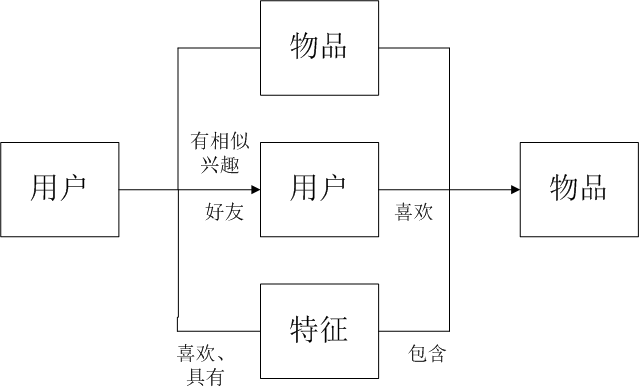
图2
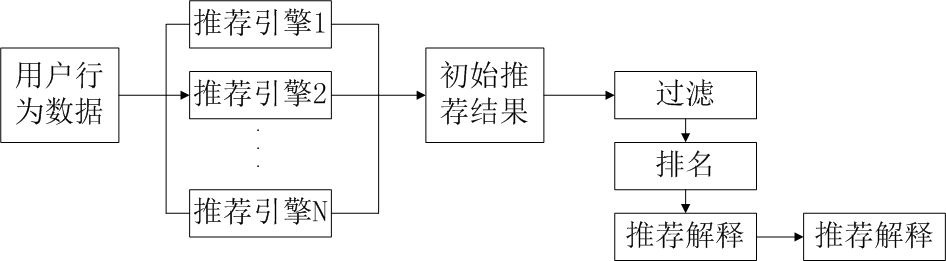
图3
用户行为数据--->推荐引擎(第一层过滤)--->初始推荐结果--->过滤--->排名--->推荐解释--->推荐结果。
图3中,推荐引擎的构建来源于不同的数据源(也就是用户的特征有很多种类,例如统计的、行为的、主题的)+不同的推荐模型算法,推荐引擎的架构可以是多样化的(实时推荐的+离线推荐的),然后融合推荐结果(人工规则+模型结果),融合方式多样的,有线性加权的或者切换式的等
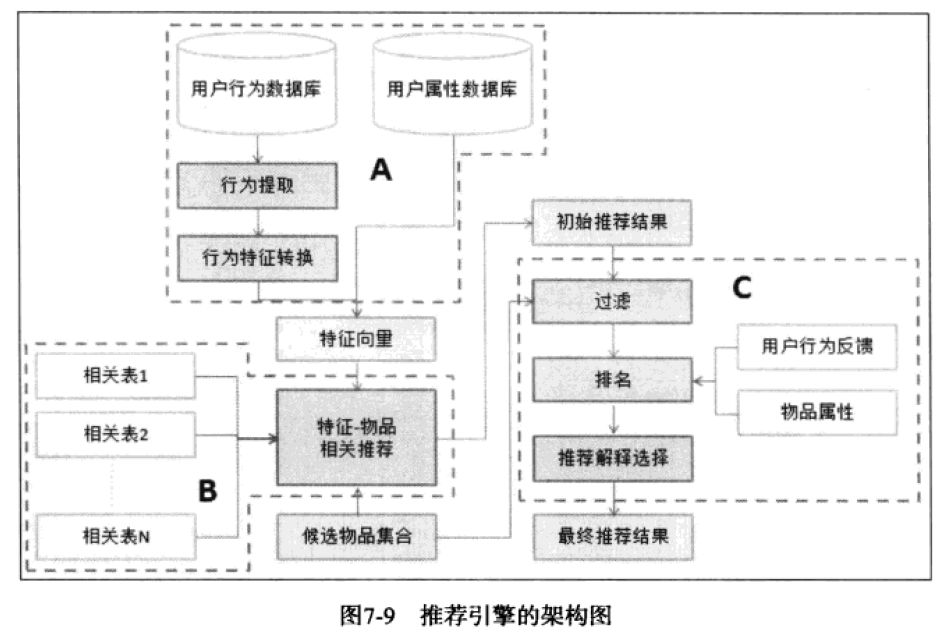
图4
图4中,A模块负责用户各类型特征的收集,B模块的相关表是根据图3中的推荐引擎来生成的,B模块的输出推荐结果用来C模块的输入,中间经过过滤模块(用户已经产生行为的物品,非候选物品,业务方提供的物品黑名单等),排名模块也根据预设定的推荐目标来制定,最后推荐解释的生成(这是可能是最容易忽视,但很关键的一环,微信的好友推荐游戏,这一解释已经胜过后台的算法作用了)
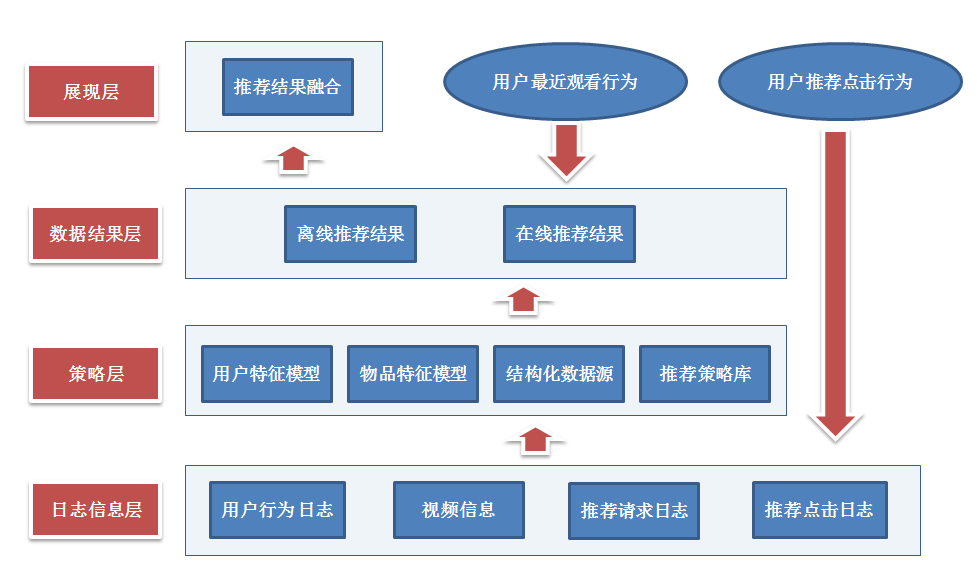
优酷的推荐系统
备注:上图来自easyhadoop举办的技术沙龙中优酷数据挖掘工程师的演讲,有关详细信息请移步 http://virtual.51cto.com/exp/Hadoop_20130330/index.html#top。作者在演讲中讲的一些"干货"跟推荐议题是很有价值的,下图简单描述。
模型前数据准备(理解数据源,用户,物品)
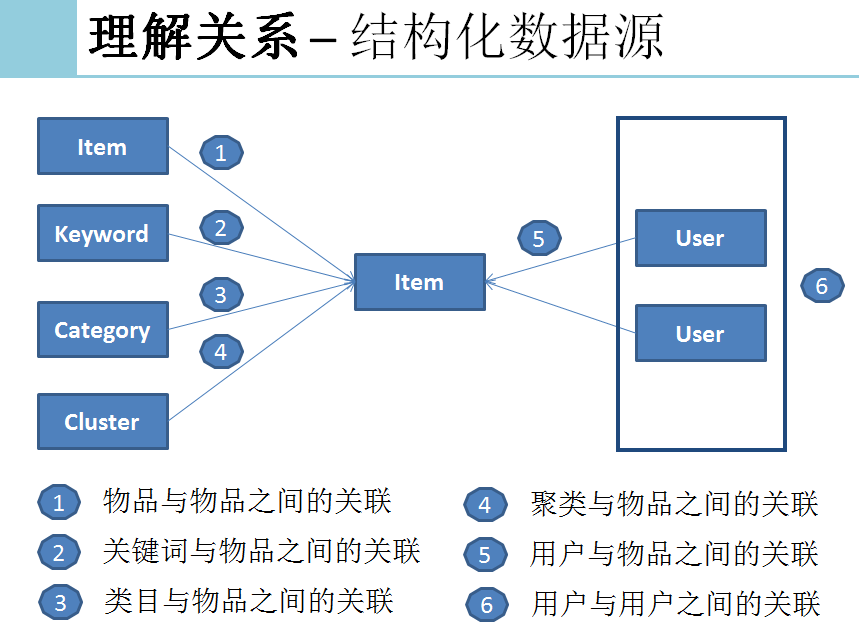
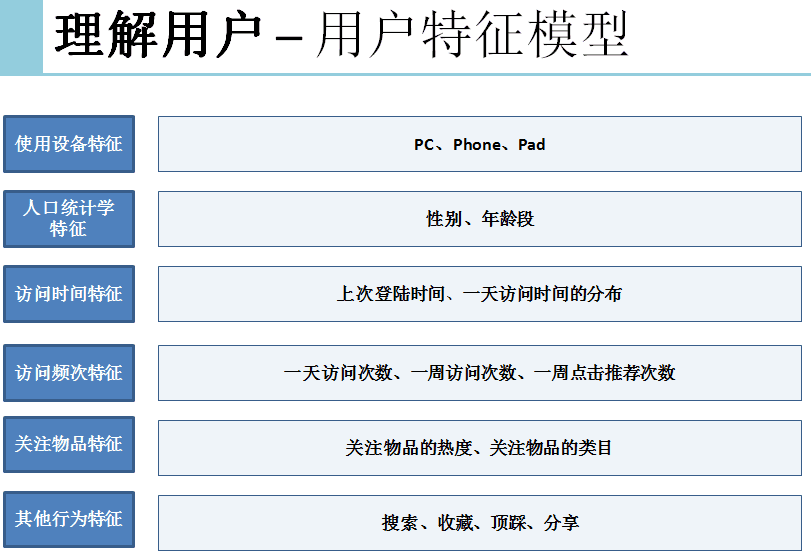


模型策略

其他考虑的场景
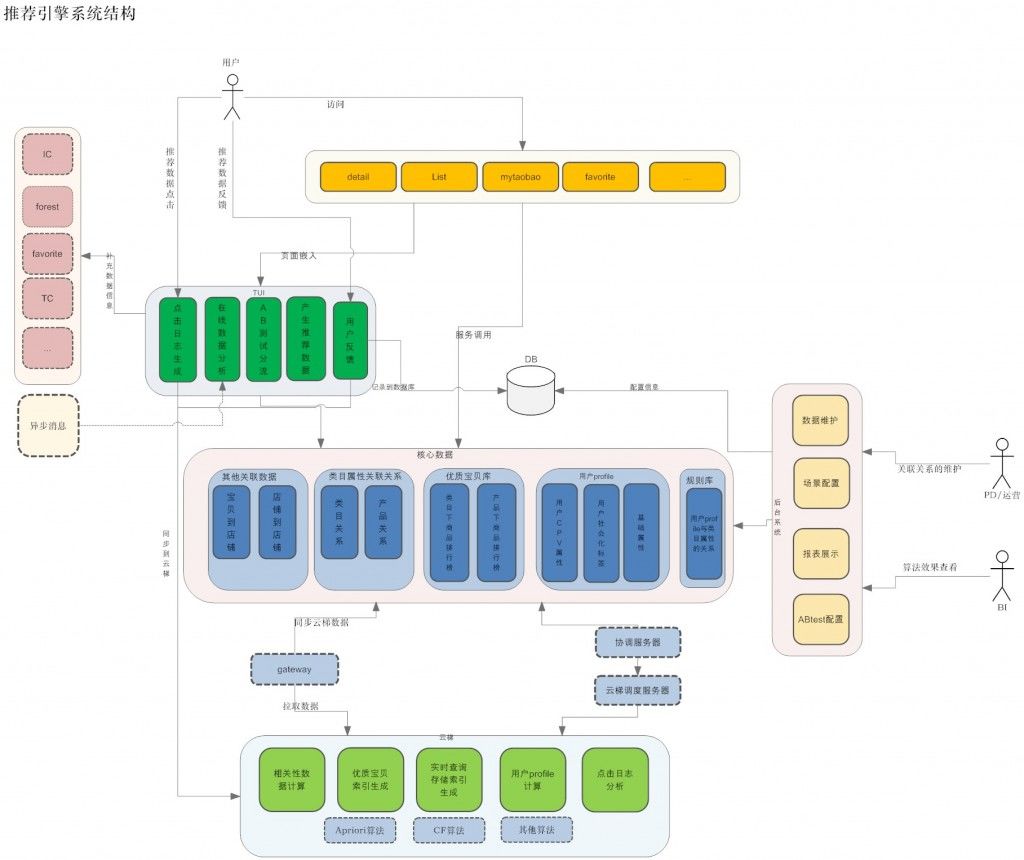 淘宝的推荐系统(详细版)
淘宝的推荐系统(详细版)
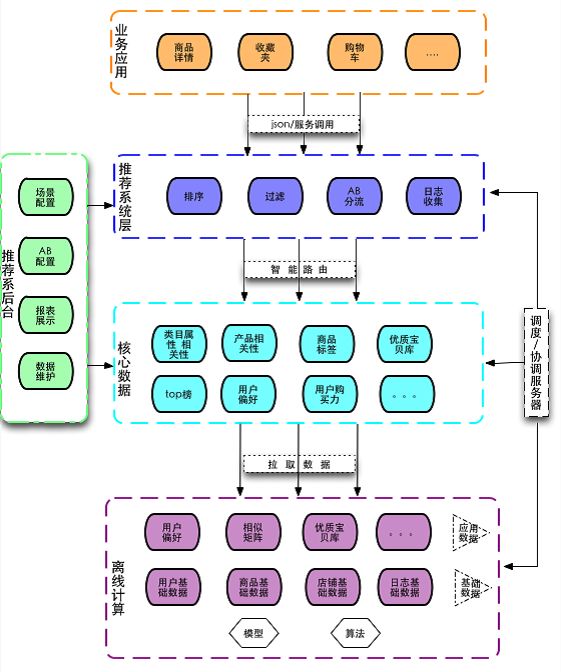
淘宝的推荐系统(简单版)
总结:淘宝的推荐系统,描述了推荐引擎搭建的整体架构,包括离线的分布式计算和存储、监控、数据统计和分析、实验平台等。给我们搭建推荐引擎提供了很好的建议。整体流程大致这样。通过后台的分布式计算,将算法产生的算法结果数据存储进入一种介质中,首推hbase。然后,通过一种叫做云梯的机制将算法结果推入中间层介质中,供推荐系统在线部分调用。在线部分提供引擎和实验分流,将用户的行为数据存储进入hadoop中,数据统计分析平台由hive来搭建,主要用来分析和统计hadoop中的用户行为log。这张图不仅讲了,推荐系统的架构流程,也讲了跟这个平台有关系的人,是怎么介入的,我觉得提供的信息可很好的参考。

















 1845
1845

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









