



1,注册人脸,
其实是通过yolo检测我们提供的人脸图片,提取128维的特征向量存储在bin文件中,实测注册一张人脸5秒不到
# 导入必要的库文件 / Import necessary libraries
from libs.PipeLine import PipeLine, ScopedTiming # 导入流水线和计时工具 / Import pipeline and timing tools
from libs.AIBase import AIBase # 导入AI基础类 / Import AI base class
from libs.AI2D import Ai2d # 导入AI 2D处理类 / Import AI 2D processing class
import os # 导入操作系统接口 / Import OS interface
import ujson # 导入JSON处理库 / Import JSON processing library
from media.media import * # 导入媒体处理库 / Import media processing library
from time import * # 导入时间处理库 / Import time processing library
import nncase_runtime as nn # 导入神经网络运行时 / Import neural network runtime
import ulab.numpy as np # 导入numpy库 / Import numpy library
import time # 导入时间库 / Import time library
import image # 导入图像处理库 / Import image processing library
import aidemo # 导入AI演示库 / Import AI demo library
import random # 导入随机数库 / Import random number library
import gc # 导入垃圾回收库 / Import garbage collection library
import sys # 导入系统库 / Import system library
import math # 导入数学库 / Import math library
global fr # 声明全局变量 / Declare global variable
class FaceDetApp(AIBase):
"""人脸检测应用类 / Face Detection Application Class
这个类继承自AIBase,实现了人脸检测的功能
This class inherits from AIBase and implements face detection functionality
"""
def __init__(self, kmodel_path, model_input_size, anchors,
confidence_threshold=0.25, nms_threshold=0.3,
rgb888p_size=[1280,720], display_size=[1920,1080],
debug_mode=0):
"""初始化函数 / Initialization function
参数 / Parameters:
- kmodel_path: KPU模型的路径 / Path to KPU model
- model_input_size: 模型输入尺寸 / Model input size
- anchors: 锚框参数 / Anchor box parameters
- confidence_threshold: 置信度阈值 / Confidence threshold
- nms_threshold: NMS阈值 / NMS threshold
- rgb888p_size: RGB888格式图像尺寸 / RGB888 format image size
- display_size: 显示尺寸 / Display size
- debug_mode: 调试模式 / Debug mode
"""
super().__init__(kmodel_path, model_input_size, rgb888p_size, debug_mode)
self.kmodel_path = kmodel_path # KPU模型路径 / KPU model path
self.model_input_size = model_input_size # 模型输入尺寸 / Model input size
self.confidence_threshold = confidence_threshold # 置信度阈值 / Confidence threshold
self.nms_threshold = nms_threshold # NMS阈值 / NMS threshold
self.anchors = anchors # 锚框参数 / Anchor box parameters
# 设置RGB888图像尺寸,确保宽度16字节对齐 / Set RGB888 image size, ensure width is 16-byte aligned
self.rgb888p_size = [ALIGN_UP(rgb888p_size[0],16), rgb888p_size[1]]
# 设置显示尺寸,确保宽度16字节对齐 / Set display size, ensure width is 16-byte aligned
self.display_size = [ALIGN_UP(display_size[0],16), display_size[1]]
self.debug_mode = debug_mode # 调试模式 / Debug mode
# 初始化AI2D对象,用于图像预处理 / Initialize AI2D object for image preprocessing
self.ai2d = Ai2d(debug_mode)
# 设置AI2D的数据类型和格式 / Set AI2D data type and format
self.ai2d.set_ai2d_dtype(nn.ai2d_format.NCHW_FMT,
nn.ai2d_format.NCHW_FMT,
np.uint8, np.uint8)
self.image_size = []
def config_preprocess(self, input_image_size=None):
"""配置预处理参数 / Configure preprocessing parameters
对输入图像进行pad和resize等预处理操作
Perform preprocessing operations such as pad and resize on input images
"""
with ScopedTiming("set preprocess config", self.debug_mode > 0):
# 设置输入图像尺寸 / Set input image size
ai2d_input_size = input_image_size if input_image_size else self.rgb888p_size
self.image_size = [input_image_size[1], input_image_size[0]]
# 配置padding参数 / Configure padding parameters
self.ai2d.pad(self.get_pad_param(ai2d_input_size), 0, [104,117,123])
# 配置resize参数 / Configure resize parameters
self.ai2d.resize(nn.interp_method.tf_bilinear, nn.interp_mode.half_pixel)
# 构建预处理流水线 / Build preprocessing pipeline
self.ai2d.build([1,3,ai2d_input_size[1],ai2d_input_size[0]],
[1,3,self.model_input_size[1],self.model_input_size[0]])
def postprocess(self, results):
"""后处理方法 / Post-processing method
处理模型的原始输出,得到最终的检测结果
Process the model's raw output to get final detection results
"""
with ScopedTiming("postprocess", self.debug_mode > 0):
# 调用aidemo库进行人脸检测后处理 / Call aidemo library for face detection post-processing
res = aidemo.face_det_post_process(self.confidence_threshold,
self.nms_threshold,
self.model_input_size[0],
self.anchors,
self.image_size,
results)
if len(res) == 0:
return res
else:
return res[0], res[1]
def get_pad_param(self, image_input_size):
"""计算padding参数 / Calculate padding parameters
计算等比例缩放后需要的padding参数
Calculate the padding parameters needed after proportional scaling
"""
dst_w = self.model_input_size[0]
dst_h = self.model_input_size[1]
# 计算缩放比例 / Calculate scaling ratio
ratio_w = dst_w / image_input_size[0]
ratio_h = dst_h / image_input_size[1]
ratio = min(ratio_w, ratio_h)
# 计算新的尺寸 / Calculate new dimensions
new_w = int(ratio * image_input_size[0])
new_h = int(ratio * image_input_size[1])
# 计算padding值 / Calculate padding values
dw = (dst_w - new_w) / 2
dh = (dst_h - new_h) / 2
top = int(round(0))
bottom = int(round(dh * 2 + 0.1))
left = int(round(0))
right = int(round(dw * 2 - 0.1))
return [0,0,0,0,top, bottom, left, right]
class FaceRegistrationApp(AIBase):
"""人脸注册应用类 / Face Registration Application Class
处理人脸注册相关的功能
Handle face registration related functions
"""
def __init__(self, kmodel_path, model_input_size,
rgb888p_size=[1920,1080], display_size=[1920,1080],
debug_mode=0):
"""初始化函数 / Initialization function"""
super().__init__(kmodel_path, model_input_size, rgb888p_size, debug_mode)
self.kmodel_path = kmodel_path # 模型路径 / Model path
self.model_input_size = model_input_size # 模型输入尺寸 / Model input size
# RGB尺寸,确保16字节对齐 / RGB size, ensure 16-byte aligned
self.rgb888p_size = [ALIGN_UP(rgb888p_size[0],16), rgb888p_size[1]]
# 显示尺寸,确保16字节对齐 / Display size, ensure 16-byte aligned
self.display_size = [ALIGN_UP(display_size[0],16), display_size[1]]
self.debug_mode = debug_mode # 调试模式 / Debug mode
# 标准5个关键点坐标 / Standard 5 keypoint coordinates
self.umeyama_args_112 = [
38.2946 , 51.6963,
73.5318 , 51.5014,
56.0252 , 71.7366,
41.5493 , 92.3655,
70.7299 , 92.2041
]
# 初始化AI2D / Initialize AI2D
self.ai2d = Ai2d(debug_mode)
self.ai2d.set_ai2d_dtype(nn.ai2d_format.NCHW_FMT,
nn.ai2d_format.NCHW_FMT,
np.uint8, np.uint8)
def config_preprocess(self, landm, input_image_size=None):
"""配置预处理参数 / Configure preprocessing parameters"""
with ScopedTiming("set preprocess config", self.debug_mode > 0):
ai2d_input_size = input_image_size if input_image_size else self.rgb888p_size
# 计算仿射变换矩阵并配置 / Calculate and configure affine transformation matrix
affine_matrix = self.get_affine_matrix(landm)
self.ai2d.affine(nn.interp_method.cv2_bilinear, 0, 0, 127, 1, affine_matrix)
# 构建预处理流水线 / Build preprocessing pipeline
self.ai2d.build([1,3,ai2d_input_size[1],ai2d_input_size[0]],
[1,3,self.model_input_size[1],self.model_input_size[0]])
def postprocess(self, results):
"""后处理方法 / Post-processing method"""
with ScopedTiming("postprocess", self.debug_mode > 0):
return results[0][0]
def svd22(self, a):
"""2x2矩阵的奇异值分解 / Singular Value Decomposition for 2x2 matrix"""
s = [0.0, 0.0]
u = [0.0, 0.0, 0.0, 0.0]
v = [0.0, 0.0, 0.0, 0.0]
# 计算奇异值 / Calculate singular values
s[0] = (math.sqrt((a[0] - a[3]) ** 2 + (a[1] + a[2]) ** 2) +
math.sqrt((a[0] + a[3]) ** 2 + (a[1] - a[2]) ** 2)) / 2
s[1] = abs(s[0] - math.sqrt((a[0] - a[3]) ** 2 + (a[1] + a[2]) ** 2))
# 计算右奇异向量 / Calculate right singular vectors
v[2] = math.sin((math.atan2(2 * (a[0] * a[1] + a[2] * a[3]),
a[0] ** 2 - a[1] ** 2 + a[2] ** 2 - a[3] ** 2)) / 2) if s[0] > s[1] else 0
v[0] = math.sqrt(1 - v[2] ** 2)
v[1] = -v[2]
v[3] = v[0]
# 计算左奇异向量 / Calculate left singular vectors
u[0] = -(a[0] * v[0] + a[1] * v[2]) / s[0] if s[0] != 0 else 1
u[2] = -(a[2] * v[0] + a[3] * v[2]) / s[0] if s[0] != 0 else 0
u[1] = (a[0] * v[1] + a[1] * v[3]) / s[1] if s[1] != 0 else -u[2]
u[3] = (a[2] * v[1] + a[3] * v[3]) / s[1] if s[1] != 0 else u[0]
v[0] = -v[0]
v[2] = -v[2]
return u, s, v
def image_umeyama_112(self, src):
"""使用Umeyama算法计算仿射变换矩阵 / Calculate affine transformation matrix using Umeyama algorithm"""
SRC_NUM = 5
SRC_DIM = 2
# 计算源点和目标点的均值 / Calculate mean of source and target points
src_mean = [0.0, 0.0]
dst_mean = [0.0, 0.0]
for i in range(0, SRC_NUM * 2, 2):
src_mean[0] += src[i]
src_mean[1] += src[i + 1]
dst_mean[0] += self.umeyama_args_112[i]
dst_mean[1] += self.umeyama_args_112[i + 1]
src_mean[0] /= SRC_NUM
src_mean[1] /= SRC_NUM
dst_mean[0] /= SRC_NUM
dst_mean[1] /= SRC_NUM
# 去中心化 / De-mean
src_demean = [[0.0, 0.0] for _ in range(SRC_NUM)]
dst_demean = [[0.0, 0.0] for _ in range(SRC_NUM)]
for i in range(SRC_NUM):
src_demean[i][0] = src[2 * i] - src_mean[0]
src_demean[i][1] = src[2 * i + 1] - src_mean[1]
dst_demean[i][0] = self.umeyama_args_112[2 * i] - dst_mean[0]
dst_demean[i][1] = self.umeyama_args_112[2 * i + 1] - dst_mean[1]
# 计算协方差矩阵 / Calculate covariance matrix
A = [[0.0, 0.0], [0.0, 0.0]]
for i in range(SRC_DIM):
for k in range(SRC_DIM):
for j in range(SRC_NUM):
A[i][k] += dst_demean[j][i] * src_demean[j][k]
A[i][k] /= SRC_NUM
# SVD分解和旋转矩阵计算 / SVD decomposition and rotation matrix calculation
T = [[1, 0, 0], [0, 1, 0], [0, 0, 1]]
U, S, V = self.svd22([A[0][0], A[0][1], A[1][0], A[1][1]])
T[0][0] = U[0] * V[0] + U[1] * V[2]
T[0][1] = U[0] * V[1] + U[1] * V[3]
T[1][0] = U[2] * V[0] + U[3] * V[2]
T[1][1] = U[2] * V[1] + U[3] * V[3]
# 计算缩放因子 / Calculate scaling factor
scale = 1.0
src_demean_mean = [0.0, 0.0]
src_demean_var = [0.0, 0.0]
for i in range(SRC_NUM):
src_demean_mean[0] += src_demean[i][0]
src_demean_mean[1] += src_demean[i][1]
src_demean_mean[0] /= SRC_NUM
src_demean_mean[1] /= SRC_NUM
for i in range(SRC_NUM):
src_demean_var[0] += (src_demean_mean[0] - src_demean[i][0]) ** 2
src_demean_var[1] += (src_demean_mean[1] - src_demean[i][1]) ** 2
src_demean_var[0] /= SRC_NUM
src_demean_var[1] /= SRC_NUM
scale = 1.0 / (src_demean_var[0] + src_demean_var[1]) * (S[0] + S[1])
# 计算平移向量 / Calculate translation vector
T[0][2] = dst_mean[0] - scale * (T[0][0] * src_mean[0] + T[0][1] * src_mean[1])
T[1][2] = dst_mean[1] - scale * (T[1][0] * src_mean[0] + T[1][1] * src_mean[1])
# 应用缩放 / Apply scaling
T[0][0] *= scale
T[0][1] *= scale
T[1][0] *= scale
T[1][1] *= scale
return T
def get_affine_matrix(self, sparse_points):
"""获取仿射变换矩阵 / Get affine transformation matrix"""
with ScopedTiming("get_affine_matrix", self.debug_mode > 1):
matrix_dst = self.image_umeyama_112(sparse_points)
matrix_dst = [matrix_dst[0][0], matrix_dst[0][1], matrix_dst[0][2],
matrix_dst[1][0], matrix_dst[1][1], matrix_dst[1][2]]
return matrix_dst
class FaceRegistration:
"""人脸注册主类 / Main Face Registration Class
整合人脸检测和注册功能的主类
Main class that integrates face detection and registration functions
"""
def __init__(self, face_det_kmodel, face_reg_kmodel, det_input_size,
reg_input_size, database_dir, anchors,
confidence_threshold=0.25, nms_threshold=0.3,
rgb888p_size=[1280,720], display_size=[1920,1080],
debug_mode=0):
"""初始化函数 / Initialization function"""
# 人脸检测模型路径 / Face detection model path
self.face_det_kmodel = face_det_kmodel
# 人脸注册模型路径 / Face registration model path
self.face_reg_kmodel = face_reg_kmodel
# 人脸检测模型输入尺寸 / Face detection model input size
self.det_input_size = det_input_size
# 人脸注册模型输入尺寸 / Face registration model input size
self.reg_input_size = reg_input_size
self.database_dir = database_dir
self.anchors = anchors
self.confidence_threshold = confidence_threshold
self.nms_threshold = nms_threshold
# RGB尺寸,确保16字节对齐 / RGB size, ensure 16-byte aligned
self.rgb888p_size = [ALIGN_UP(rgb888p_size[0],16), rgb888p_size[1]]
# 显示尺寸,确保16字节对齐 / Display size, ensure 16-byte aligned
self.display_size = [ALIGN_UP(display_size[0],16), display_size[1]]
self.debug_mode = debug_mode
# 初始化人脸检测和注册模型 / Initialize face detection and registration models
self.face_det = FaceDetApp(self.face_det_kmodel,
model_input_size=self.det_input_size,
anchors=self.anchors,
confidence_threshold=self.confidence_threshold,
nms_threshold=self.nms_threshold,
debug_mode=0)
self.face_reg = FaceRegistrationApp(self.face_reg_kmodel,
model_input_size=self.reg_input_size,
rgb888p_size=self.rgb888p_size)
def run(self, input_np, img_file):
"""运行人脸注册流程 / Run face registration process"""
# 配置人脸检测预处理 / Configure face detection preprocessing
self.face_det.config_preprocess(input_image_size=[input_np.shape[3],input_np.shape[2]])
# 执行人脸检测 / Perform face detection
det_boxes, landms = self.face_det.run(input_np)
try:
if det_boxes:
if det_boxes.shape[0] == 1:
# 若只检测到一张人脸,进行注册 / If only one face is detected, proceed with registration
db_i_name = img_file.split('.')[0]
for landm in landms:
# 配置人脸注册预处理 / Configure face registration preprocessing
self.face_reg.config_preprocess(landm, input_image_size=[input_np.shape[3],input_np.shape[2]])
# 执行人脸特征提取 / Perform face feature extraction
reg_result = self.face_reg.run(input_np)
# 保存特征到数据库 / Save features to database
with open(self.database_dir+'{}.bin'.format(db_i_name), "wb") as file:
file.write(reg_result.tobytes())
pass
else:
pass
else:
pass
except:
pass
def image2rgb888array(self, img):
"""将图像转换为RGB888数组 / Convert image to RGB888 array"""
with ScopedTiming("fr_kpu_deinit", self.debug_mode > 0):
# 转换为RGB888格式 / Convert to RGB888 format
img_data_rgb888 = img.to_rgb888()
# 转换为numpy数组 / Convert to numpy array
img_hwc = img_data_rgb888.to_numpy_ref()
shape = img_hwc.shape
# 重塑并转置数组 / Reshape and transpose array
img_tmp = img_hwc.reshape((shape[0] * shape[1], shape[2]))
img_tmp_trans = img_tmp.transpose()
img_res = img_tmp_trans.copy()
# 返回NCHW格式的数组 / Return array in NCHW format
img_return = img_res.reshape((1, shape[2], shape[0], shape[1]))
return img_return
def ensure_dir(directory):
"""
递归创建目录,适用于MicroPython环境
"""
# 如果目录为空字符串或根目录,直接返回
if not directory or directory == '/':
return
# 处理路径分隔符,确保使用标准格式
directory = directory.rstrip('/')
try:
# 尝试获取目录状态,如果目录存在就直接返回
os.stat(directory)
pass
return
except OSError:
# 目录不存在,需要创建
# 分割路径以获取父目录
if '/' in directory:
parent = directory[:directory.rindex('/')]
if parent and parent != directory: # 避免无限递归
ensure_dir(parent)
try:
os.mkdir(directory)
pass
except OSError as e:
# 可能是并发创建导致的冲突,再次检查目录是否存在
try:
os.stat(directory)
pass
except:
# 如果仍然不存在,则确实出错了
pass
except Exception as e:
pass
def get_directory_name(path):
"""获取路径中的目录名 / Get directory name from path"""
parts = path.split('/')
for part in reversed(parts):
if part:
return part
return ''
def exce_demo(reg_path, database_dir):
"""执行演示的主函数 / Main function to execute demonstration"""
# 配置模型和参数路径 / Configure model and parameter paths
face_det_kmodel_path = "/sdcard/kmodel/face_detection_320.kmodel"
face_reg_kmodel_path = "/sdcard/kmodel/face_recognition.kmodel"
anchors_path = "/sdcard/utils/prior_data_320.bin"
database_img_dir = reg_path
dir_name = get_directory_name(database_img_dir)
face_det_input_size = [320,320]
face_reg_input_size = [112,112]
confidence_threshold = 0.5
nms_threshold = 0.2
anchor_len = 4200
det_dim = 4
# 加载anchors数据 / Load anchors data
anchors = np.fromfile(anchors_path, dtype=np.float)
anchors = anchors.reshape((anchor_len, det_dim))
# 设置最大注册人脸数和特征维度 / Set maximum number of registered faces and feature dimensions
max_register_face = 1000
feature_num = 128
print("开始注册人脸")
if database_dir is None:
database_dir = "/data/face_database/" + dir_name + "/"
ensure_dir(database_dir)
# 初始化人脸注册对象 / Initialize face registration object
fr = FaceRegistration(face_det_kmodel_path, face_reg_kmodel_path,
det_input_size=face_det_input_size,
reg_input_size=face_reg_input_size,
database_dir=database_dir,
anchors=anchors,
confidence_threshold=confidence_threshold,
nms_threshold=nms_threshold)
print("人脸注册对象初始化完成")
# 获取图像列表并处理 / Get image list and process
print(database_img_dir)
img_list = os.listdir(database_img_dir)
for img_file in img_list:
# 检查文件扩展名
img_file_lower = img_file.lower()
if (img_file_lower.endswith('.jpg') or
img_file_lower.endswith('.jpeg') or
img_file_lower.endswith('.png') or
img_file_lower.endswith('.bmp')):
print("注册人脸: ", img_file)
# 读取图像 / Read image
full_img_file = database_img_dir + img_file
print(full_img_file)
img = image.Image(full_img_file)
img.compress_for_ide()
# 转换图像格式并处理 / Convert image format and process
rgb888p_img_ndarry = fr.image2rgb888array(img)
fr.run(rgb888p_img_ndarry, img_file)
gc.collect()
print("注册人脸成功: ", img_file)
else:
print("跳过非图片文件: ", img_file)
if __name__ == "__main__":
"""程序入口 / Program entry"""
exce_demo("data/face_register/","data/face_database/")
2,识别人脸
通过实时识别视像头的人脸 逐个与上次注册好的特征向量做对比进行识别,实测识别率80%以上
# 导入所需库 / Import required libraries
from libs.PipeLine import PipeLine, ScopedTiming # 导入视频处理Pipline和计时器类 / Import video pipeline and timer classes
from libs.AIBase import AIBase # 导入AI基础类 / Import AI base class
from libs.AI2D import Ai2d # 导入AI 2D处理类 / Import AI 2D processing class
import os
import ujson
from media.media import * # 导入媒体处理相关库 / Import media processing libraries
from time import *
import nncase_runtime as nn # 导入神经网络运行时库 / Import neural network runtime library
import ulab.numpy as np # 导入类numpy库,用于数组操作 / Import numpy-like library for array operations
import time
import image # 图像处理库 / Image processing library
import aidemo # AI演示库 / AI demo library
import random
import gc # 垃圾回收模块 / Garbage collection module
import sys
import math,re
from play_audio import play_audio
uart = None
# Import touch sensor module
# 导入触摸传感器模块
from machine import TOUCH
tp = TOUCH(0) # 人脸识别对象的全局变量 / Global variable for face recognition object
from libs.YbProtocol import YbProtocol
uart = None
pto = YbProtocol()
class FaceDetApp(AIBase):
"""
人脸检测应用类 / Face detection application class
继承自AIBase基类 / Inherits from AIBase class
"""
def __init__(self, kmodel_path, model_input_size, anchors, confidence_threshold=0.25,
nms_threshold=0.3, rgb888p_size=[1920,1080], display_size=[1920,1080], debug_mode=0):
"""
初始化函数 / Initialization function
参数说明 / Parameters:
kmodel_path: 模型文件路径 / Model file path
model_input_size: 模型输入尺寸 / Model input size
anchors: 锚框参数 / Anchor box parameters
confidence_threshold: 置信度阈值 / Confidence threshold
nms_threshold: 非极大值抑制阈值 / Non-maximum suppression threshold
rgb888p_size: 输入图像尺寸 / Input image size
display_size: 显示尺寸 / Display size
debug_mode: 调试模式标志 / Debug mode flag
"""
super().__init__(kmodel_path, model_input_size, rgb888p_size, debug_mode)
# 保存初始化参数 / Save initialization parameters
self.kmodel_path = kmodel_path # kmodel文件路径 / kmodel file path
self.model_input_size = model_input_size # 模型输入尺寸 / Model input size
self.confidence_threshold = confidence_threshold # 置信度阈值 / Confidence threshold
self.nms_threshold = nms_threshold # NMS阈值 / NMS threshold
self.anchors = anchors # 锚框参数 / Anchor parameters
# 图像尺寸处理(16字节对齐)/ Image size processing (16-byte alignment)
self.rgb888p_size = [ALIGN_UP(rgb888p_size[0],16), rgb888p_size[1]]
self.display_size = [ALIGN_UP(display_size[0],16), display_size[1]]
self.debug_mode = debug_mode # 调试模式 / Debug mode
# 初始化AI2D预处理器 / Initialize AI2D preprocessor
self.ai2d = Ai2d(debug_mode)
# 设置AI2D参数 / Set AI2D parameters
self.ai2d.set_ai2d_dtype(nn.ai2d_format.NCHW_FMT,
nn.ai2d_format.NCHW_FMT,
np.uint8, np.uint8)
def config_preprocess(self, input_image_size=None):
"""
配置图像预处理参数 / Configure image preprocessing parameters
使用pad和resize操作 / Use pad and resize operations
"""
with ScopedTiming("set preprocess config", self.debug_mode > 0):
# 设置输入大小 / Set input size
ai2d_input_size = input_image_size if input_image_size else self.rgb888p_size
# 配置padding参数 / Configure padding parameters
self.ai2d.pad(self.get_pad_param(), 0, [104,117,123])
# 配置resize参数 / Configure resize parameters
self.ai2d.resize(nn.interp_method.tf_bilinear, nn.interp_mode.half_pixel)
# 构建预处理pipeline / Build preprocessing pipeline
self.ai2d.build([1,3,ai2d_input_size[1],ai2d_input_size[0]],
[1,3,self.model_input_size[1],self.model_input_size[0]])
def postprocess(self, results):
"""
后处理方法 / Post-processing method
使用aidemo库处理检测结果 / Process detection results using aidemo library
"""
with ScopedTiming("postprocess", self.debug_mode > 0):
# 处理检测结果 / Process detection results
res = aidemo.face_det_post_process(self.confidence_threshold,
self.nms_threshold,
self.model_input_size[0],
self.anchors,
self.rgb888p_size,
results)
# 返回检测结果 / Return detection results
if len(res) == 0:
return res, res
else:
return res[0], res[1]
def get_pad_param(self):
"""
计算padding参数 / Calculate padding parameters
返回padding的边界值 / Return padding boundary values
"""
dst_w = self.model_input_size[0]
dst_h = self.model_input_size[1]
# 计算缩放比例 / Calculate scaling ratio
ratio_w = dst_w / self.rgb888p_size[0]
ratio_h = dst_h / self.rgb888p_size[1]
ratio = min(ratio_w, ratio_h)
# 计算新的尺寸 / Calculate new dimensions
new_w = int(ratio * self.rgb888p_size[0])
new_h = int(ratio * self.rgb888p_size[1])
# 计算padding值 / Calculate padding values
dw = (dst_w - new_w) / 2
dh = (dst_h - new_h) / 2
# 返回padding参数 / Return padding parameters
top = int(round(0))
bottom = int(round(dh * 2 + 0.1))
left = int(round(0))
right = int(round(dw * 2 - 0.1))
return [0, 0, 0, 0, top, bottom, left, right]
class FaceRegistrationApp(AIBase):
"""
人脸注册应用类 / Face registration application class
用于人脸特征提取和注册 / For face feature extraction and registration
"""
def __init__(self, kmodel_path, model_input_size, rgb888p_size=[1920,1080],
display_size=[1920,1080], debug_mode=0):
super().__init__(kmodel_path, model_input_size, rgb888p_size, debug_mode)
# 初始化参数 / Initialize parameters
self.kmodel_path = kmodel_path
self.model_input_size = model_input_size
self.rgb888p_size = [ALIGN_UP(rgb888p_size[0],16), rgb888p_size[1]]
self.display_size = [ALIGN_UP(display_size[0],16), display_size[1]]
self.debug_mode = debug_mode
# 标准人脸关键点坐标 / Standard face keypoint coordinates
self.umeyama_args_112 = [
38.2946, 51.6963,
73.5318, 51.5014,
56.0252, 71.7366,
41.5493, 92.3655,
70.7299, 92.2041
]
# 初始化AI2D / Initialize AI2D
self.ai2d = Ai2d(debug_mode)
self.ai2d.set_ai2d_dtype(nn.ai2d_format.NCHW_FMT,
nn.ai2d_format.NCHW_FMT,
np.uint8, np.uint8)
def config_preprocess(self, landm, input_image_size=None):
"""
配置预处理参数 / Configure preprocessing parameters
使用仿射变换进行人脸对齐 / Use affine transformation for face alignment
"""
with ScopedTiming("set preprocess config", self.debug_mode > 0):
ai2d_input_size = input_image_size if input_image_size else self.rgb888p_size
# 计算仿射变换矩阵 / Calculate affine transformation matrix
affine_matrix = self.get_affine_matrix(landm)
self.ai2d.affine(nn.interp_method.cv2_bilinear, 0, 0, 127, 1, affine_matrix)
# 构建预处理pipeline / Build preprocessing pipeline
self.ai2d.build([1,3,ai2d_input_size[1],ai2d_input_size[0]],
[1,3,self.model_input_size[1],self.model_input_size[0]])
def postprocess(self, results):
"""
后处理方法 / Post-processing method
提取人脸特征 / Extract face features
"""
with ScopedTiming("postprocess", self.debug_mode > 0):
return results[0][0]
def svd22(self, a):
"""
2x2矩阵的奇异值分解 / Singular value decomposition for 2x2 matrix
"""
# SVD计算 / SVD calculation
s = [0.0, 0.0]
u = [0.0, 0.0, 0.0, 0.0]
v = [0.0, 0.0, 0.0, 0.0]
s[0] = (math.sqrt((a[0] - a[3]) ** 2 + (a[1] + a[2]) ** 2) +
math.sqrt((a[0] + a[3]) ** 2 + (a[1] - a[2]) ** 2)) / 2
s[1] = abs(s[0] - math.sqrt((a[0] - a[3]) ** 2 + (a[1] + a[2]) ** 2))
v[2] = (math.sin((math.atan2(2 * (a[0] * a[1] + a[2] * a[3]),
a[0] ** 2 - a[1] ** 2 + a[2] ** 2 - a[3] ** 2)) / 2)
if s[0] > s[1] else 0)
v[0] = math.sqrt(1 - v[2] ** 2)
v[1] = -v[2]
v[3] = v[0]
u[0] = -(a[0] * v[0] + a[1] * v[2]) / s[0] if s[0] != 0 else 1
u[2] = -(a[2] * v[0] + a[3] * v[2]) / s[0] if s[0] != 0 else 0
u[1] = (a[0] * v[1] + a[1] * v[3]) / s[1] if s[1] != 0 else -u[2]
u[3] = (a[2] * v[1] + a[3] * v[3]) / s[1] if s[1] != 0 else u[0]
v[0] = -v[0]
v[2] = -v[2]
return u, s, v
def image_umeyama_112(self, src):
"""
使用Umeyama算法进行人脸对齐 / Face alignment using Umeyama algorithm
"""
SRC_NUM = 5 # 关键点数量 / Number of keypoints
SRC_DIM = 2 # 坐标维度 / Coordinate dimensions
# 计算源点和目标点的均值 / Calculate mean of source and target points
src_mean = [0.0, 0.0]
dst_mean = [0.0, 0.0]
for i in range(0, SRC_NUM * 2, 2):
src_mean[0] += src[i]
src_mean[1] += src[i + 1]
dst_mean[0] += self.umeyama_args_112[i]
dst_mean[1] += self.umeyama_args_112[i + 1]
src_mean[0] /= SRC_NUM
src_mean[1] /= SRC_NUM
dst_mean[0] /= SRC_NUM
dst_mean[1] /= SRC_NUM
# 去均值化 / De-mean
src_demean = [[0.0, 0.0] for _ in range(SRC_NUM)]
dst_demean = [[0.0, 0.0] for _ in range(SRC_NUM)]
for i in range(SRC_NUM):
src_demean[i][0] = src[2 * i] - src_mean[0]
src_demean[i][1] = src[2 * i + 1] - src_mean[1]
dst_demean[i][0] = self.umeyama_args_112[2 * i] - dst_mean[0]
dst_demean[i][1] = self.umeyama_args_112[2 * i + 1] - dst_mean[1]
# 计算A矩阵 / Calculate A matrix
A = [[0.0, 0.0], [0.0, 0.0]]
for i in range(SRC_DIM):
for k in range(SRC_DIM):
for j in range(SRC_NUM):
A[i][k] += dst_demean[j][i] * src_demean[j][k]
A[i][k] /= SRC_NUM
# SVD分解和旋转矩阵计算 / SVD decomposition and rotation matrix calculation
T = [[1, 0, 0], [0, 1, 0], [0, 0, 1]]
U, S, V = self.svd22([A[0][0], A[0][1], A[1][0], A[1][1]])
T[0][0] = U[0] * V[0] + U[1] * V[2]
T[0][1] = U[0] * V[1] + U[1] * V[3]
T[1][0] = U[2] * V[0] + U[3] * V[2]
T[1][1] = U[2] * V[1] + U[3] * V[3]
# 计算缩放因子 / Calculate scaling factor
scale = 1.0
src_demean_mean = [0.0, 0.0]
src_demean_var = [0.0, 0.0]
for i in range(SRC_NUM):
src_demean_mean[0] += src_demean[i][0]
src_demean_mean[1] += src_demean[i][1]
src_demean_mean[0] /= SRC_NUM
src_demean_mean[1] /= SRC_NUM
for i in range(SRC_NUM):
src_demean_var[0] += (src_demean_mean[0] - src_demean[i][0]) ** 2
src_demean_var[1] += (src_demean_mean[1] - src_demean[i][1]) ** 2
src_demean_var[0] /= SRC_NUM
src_demean_var[1] /= SRC_NUM
scale = 1.0 / (src_demean_var[0] + src_demean_var[1]) * (S[0] + S[1])
# 计算平移向量 / Calculate translation vector
T[0][2] = dst_mean[0] - scale * (T[0][0] * src_mean[0] + T[0][1] * src_mean[1])
T[1][2] = dst_mean[1] - scale * (T[1][0] * src_mean[0] + T[1][1] * src_mean[1])
# 应用缩放 / Apply scaling
T[0][0] *= scale
T[0][1] *= scale
T[1][0] *= scale
T[1][1] *= scale
return T
def get_affine_matrix(self, sparse_points):
"""
获取仿射变换矩阵 / Get affine transformation matrix
"""
with ScopedTiming("get_affine_matrix", self.debug_mode > 1):
matrix_dst = self.image_umeyama_112(sparse_points)
matrix_dst = [matrix_dst[0][0], matrix_dst[0][1], matrix_dst[0][2],
matrix_dst[1][0], matrix_dst[1][1], matrix_dst[1][2]]
return matrix_dst
class FaceRecognition:
"""
人脸识别类 / Face recognition class
集成了检测和识别功能 / Integrates detection and recognition functions
"""
def __init__(self, face_det_kmodel, face_reg_kmodel, det_input_size, reg_input_size,
database_dir, anchors, confidence_threshold=0.25, nms_threshold=0.3,
face_recognition_threshold=0.75, rgb888p_size=[1280,720],
display_size=[1920,1080], debug_mode=0):
# 初始化参数 / Initialize parameters
self.face_det_kmodel = face_det_kmodel
self.face_reg_kmodel = face_reg_kmodel
self.det_input_size = det_input_size
self.reg_input_size = reg_input_size
self.database_dir = database_dir
self.anchors = anchors
self.confidence_threshold = confidence_threshold
self.nms_threshold = nms_threshold
self.face_recognition_threshold = face_recognition_threshold
self.rgb888p_size = [ALIGN_UP(rgb888p_size[0],16), rgb888p_size[1]]
self.display_size = [ALIGN_UP(display_size[0],16), display_size[1]]
self.debug_mode = debug_mode
# 数据库参数 / Database parameters
self.max_register_face = 100
self.feature_num = 128
self.valid_register_face = 0
self.db_name = []
self.db_data = []
# 初始化检测和注册模型 / Initialize detection and registration models
self.face_det = FaceDetApp(self.face_det_kmodel,
model_input_size=self.det_input_size,
anchors=self.anchors,
confidence_threshold=self.confidence_threshold,
nms_threshold=self.nms_threshold,
rgb888p_size=self.rgb888p_size,
display_size=self.display_size,
debug_mode=0)
self.face_reg = FaceRegistrationApp(self.face_reg_kmodel,
model_input_size=self.reg_input_size,
rgb888p_size=self.rgb888p_size,
display_size=self.display_size)
self.face_det.config_preprocess()
self.database_init()
def run(self, input_np):
# 人脸检测
det_boxes, landms = self.face_det.run(input_np)
recg_res = []
try:
# 限制最大处理的人脸数量为5个
max_faces = 2 # 可以根据设备性能调整这个数值
if len(landms) > max_faces:
landms = landms[:max_faces]
det_boxes = det_boxes[:max_faces]
for landm in landms:
self.face_reg.config_preprocess(landm)
feature = self.face_reg.run(input_np)
res,name = self.database_search(feature)
recg_res.append(res)
return det_boxes, recg_res,name
except Exception as e:
print(e)
return [], [], []
def database_init(self):
"""
初始化人脸数据库 / Initialize face database
"""
with ScopedTiming("database_init", self.debug_mode > 1):
# 读取数据库文件 / Read database files
db_file_list = os.listdir(self.database_dir)
for db_file in db_file_list:
if not db_file.endswith('.bin'):
continue
if self.valid_register_face >= self.max_register_face:
break
valid_index = self.valid_register_face
full_db_file = self.database_dir + db_file
# 读取特征数据 / Read feature data
with open(full_db_file, 'rb') as f:
data = f.read()
feature = np.frombuffer(data, dtype=np.float)
self.db_data.append(feature)
# 保存人名 / Save person name
name = db_file.split('.')[0]
self.db_name.append(name)
self.valid_register_face += 1
def database_reset(self):
"""
重置数据库 / Reset database
"""
with ScopedTiming("database_reset", self.debug_mode > 1):
pass
self.db_name = []
self.db_data = []
self.valid_register_face = 0
pass
def database_search(self, feature):
"""
在数据库中搜索匹配的人脸 / Search for matching face in database
"""
with ScopedTiming("database_search", self.debug_mode > 1):
v_id = -1
v_score_max = 0.0
# 特征归一化 / Feature normalization
feature /= np.linalg.norm(feature)
# 遍历数据库进行匹配 / Search through database for matches
for i in range(self.valid_register_face):
db_feature = self.db_data[i]
db_feature /= np.linalg.norm(db_feature)
v_score = np.dot(feature, db_feature)/2 + 0.5
if v_score > v_score_max:
v_score_max = v_score
v_id = i
# 返回识别结果 / Return recognition result
if v_id == -1:
return 'unknown','unknown'
elif v_score_max < self.face_recognition_threshold:
return 'unknown','unknown'
else:
result = 'name: {}, score:{}'.format(self.db_name[v_id], v_score_max)
return result,self.db_name[v_id]
def draw_result(self, pl, dets, recg_results):
"""
绘制识别结果 / Draw recognition results
"""
pl.osd_img.clear()
if dets:
for i, det in enumerate(dets):
# 绘制人脸框 / Draw face box
x1, y1, w, h = map(lambda x: int(round(x, 0)), det[:4])
x1 = x1 * self.display_size[0]//self.rgb888p_size[0]
y1 = y1 * self.display_size[1]//self.rgb888p_size[1]
w = w * self.display_size[0]//self.rgb888p_size[0]
h = h * self.display_size[1]//self.rgb888p_size[1]
# 绘制识别结果 / Draw recognition result
recg_text = recg_results[i]
if recg_text == 'unknown':
pl.osd_img.draw_rectangle(x1, y1, w, h, color=(255,0,0,255), thickness=4)
else:
pl.osd_img.draw_rectangle(x1, y1, w, h, color=(255,0,255,0), thickness=4)
pl.osd_img.draw_string_advanced(x1, y1, 32, recg_text, color=(255,255,0,0))
# 使用正则表达式匹配 name 和 score 的值
pattern = r'name: (.*), score: (.*)'
match = re.match(pattern, recg_text)
if match:
name_value = match.group(1) # 提取 name 的值
score_value = match.group(2) # 提取 score 的值
pto_data = pto.get_face_recoginiton_data(x1, y1, w, h, name_value, score_value)
# uart.send(pto_data)
print(pto_data)
else:
pto_data = pto.get_face_recoginiton_data(x1, y1, w, h, recg_text, 0)
# uart.send(pto_data)
print(pto_data)
class YAHBOOM_DEMO:
def __init__(self, pl, _uart = None):
global uart
self.pl = pl
self.fr = None
uart = _uart
try:
MediaManager._config() # 添加配置步骤
MediaManager.init() # 尝试初始化
except AssertionError:
pass # 如果已初始化则跳过
def exce_demo(self, db_path="/data/face_database/", loading_text="Loading ..."):
"""
执行演示程序 / Execute demo program
"""
display_mode = self.pl.display_mode
rgb888p_size = self.pl.rgb888p_size
display_size = self.pl.display_size
self.pl.osd_img.clear()
self.pl.osd_img.draw_string_advanced(display_size[0]//2 - 40, 220, 40, loading_text, color=(255,255,0,0))
self.pl.show_image()
# 加载模型和配置 / Load models and configurations
face_det_kmodel_path = "/sdcard/kmodel/face_detection_320.kmodel"
face_reg_kmodel_path = "/sdcard/kmodel/face_recognition.kmodel"
anchors_path = "/sdcard/utils/prior_data_320.bin"
database_dir = db_path
face_det_input_size = [320,320]
face_reg_input_size = [112,112]
confidence_threshold = 0.5
nms_threshold = 0.2
anchor_len = 4200
det_dim = 4
# 读取anchor数据 / Read anchor data
anchors = np.fromfile(anchors_path, dtype=np.float)
anchors = anchors.reshape((anchor_len, det_dim))
face_recognition_threshold = 0.65
try:
gc.collect()
# 创建人脸识别对象 / Create face recognition object
self.fr = FaceRecognition(face_det_kmodel_path, face_reg_kmodel_path,
det_input_size=face_det_input_size,
reg_input_size=face_reg_input_size,
database_dir=database_dir,
anchors=anchors,
confidence_threshold=confidence_threshold,
nms_threshold=nms_threshold,
face_recognition_threshold=face_recognition_threshold,
rgb888p_size=rgb888p_size,
display_size=display_size)
MediaManager.init()
except Exception as e:
print(e)
# 主循环 / Main loop
try:
while True:
point = tp.read(1)
if len(point):
pt = point[0]
if pt.event == TOUCH.EVENT_DOWN:
if pt.x<100 and pt.y<100:
self.exit_demo()
time.sleep_ms(10)
break
# 获取图像并处理 / Get and process image
img = self.pl.get_frame()
det_boxes, recg_res,name = self.fr.run(img)
self.fr.draw_result(self.pl, det_boxes, recg_res)
self.pl.show_image()
gc.collect()
time.sleep_ms(1)
except Exception as e:
print(e)
def exit_demo(self):
print("exit")
MediaManager.deinit() # 释放资源
return
if __name__ == "__main__":
# 这里会自动执行demo
rgb888p_size=[640,360] # 原始图像分辨率 / Original image resolution
display_size=[640,480] # 显示分辨率 / Display resolution
display_mode="lcd" # 显示模式 / Display mode
pl = PipeLine(rgb888p_size=rgb888p_size, display_size=display_size, display_mode=display_mode)
pl.create() # 创建Pipline实例 / Create pipeline instance
demo = YAHBOOM_DEMO(pl, None)
demo.exce_demo()
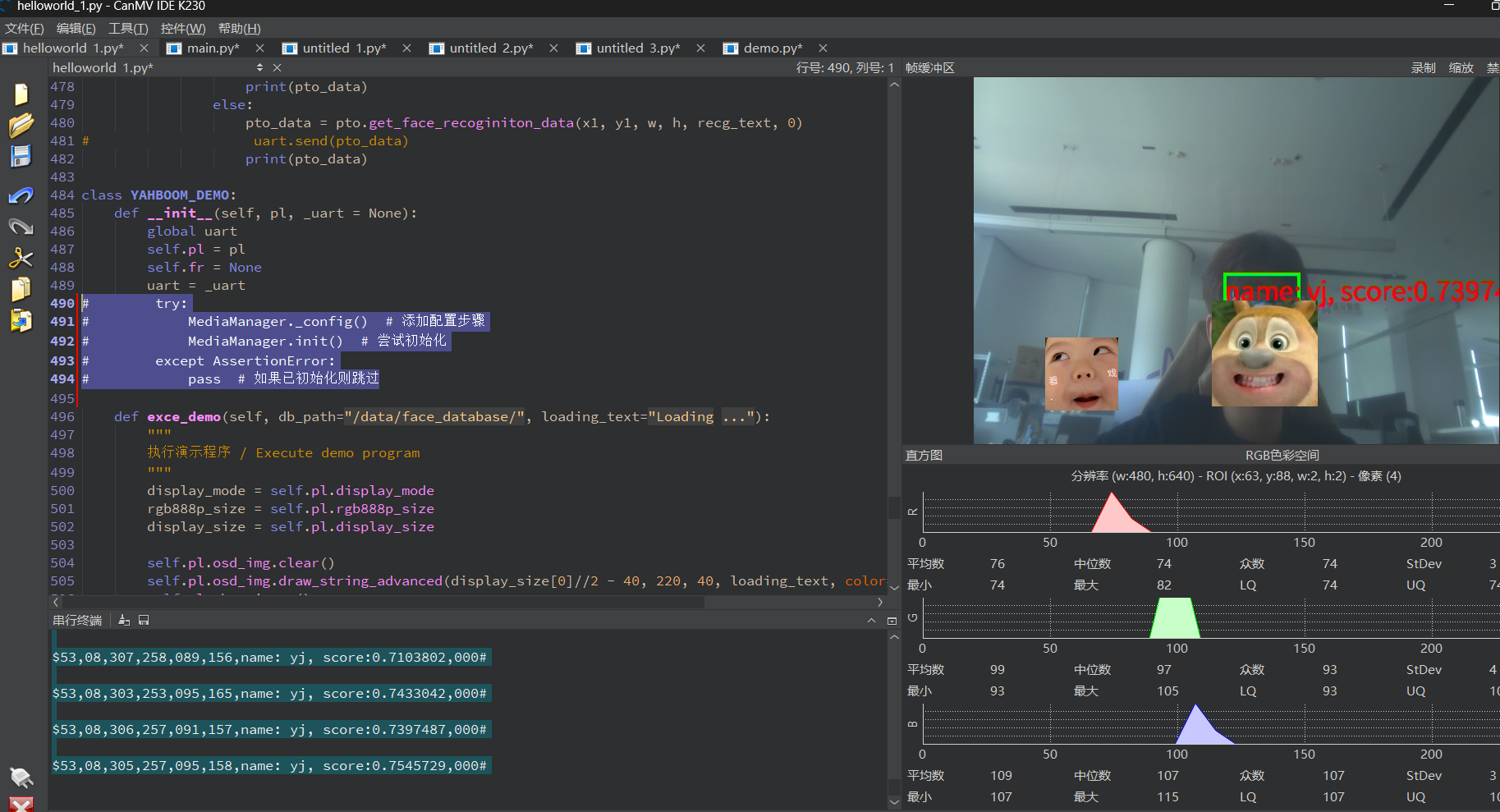
3,效果展示
我的设备是这个



















 5950
5950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









