




 本文介绍了一个使用Python和XPath实现的图片爬虫案例。该爬虫针对彼岸图网进行设计,能够根据用户选择的不同图片类型抓取4K分辨率的图片,并通过拼音转换功能支持中文输入。代码还包含了错误处理和文件保存功能。
本文介绍了一个使用Python和XPath实现的图片爬虫案例。该爬虫针对彼岸图网进行设计,能够根据用户选择的不同图片类型抓取4K分辨率的图片,并通过拼音转换功能支持中文输入。代码还包含了错误处理和文件保存功能。
爬虫部分的代码是xpath实现的,不妥的地方还请大佬们指点
运行结果如下:
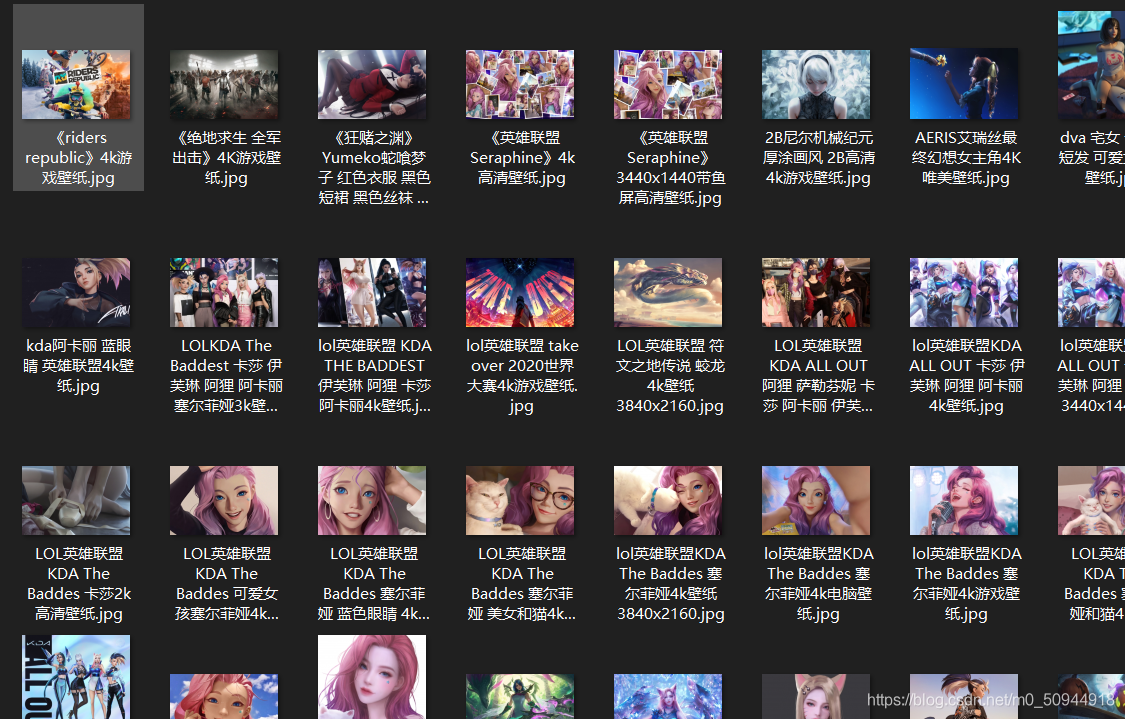
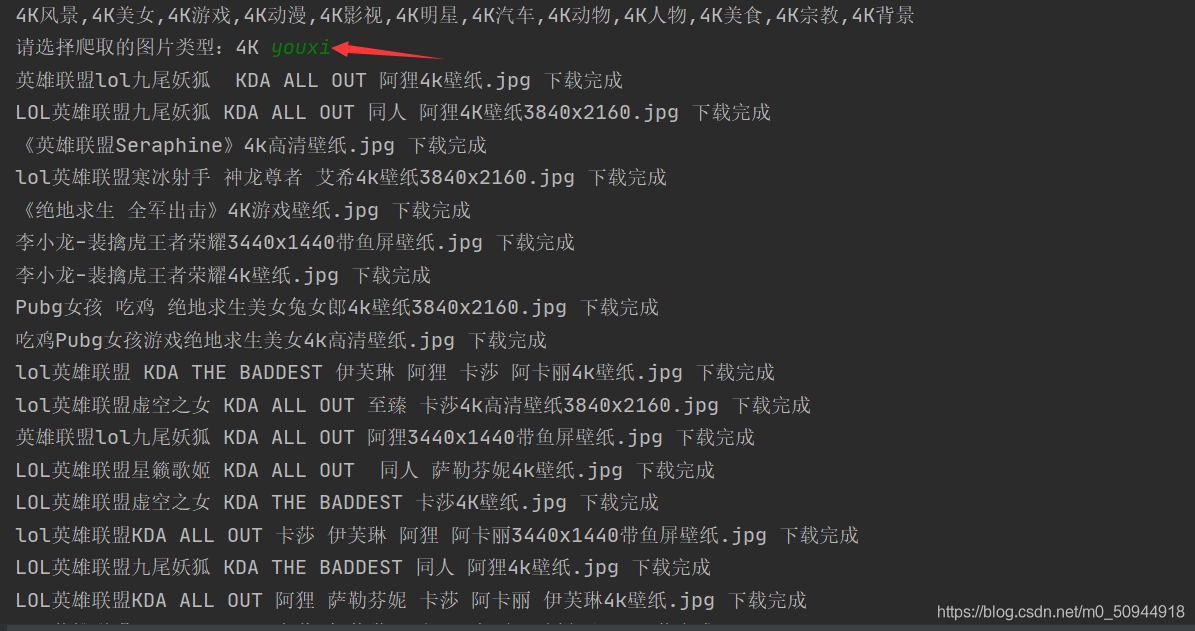
这里做了一个判断,中文的话转成拼音,拼接进url中进行解析
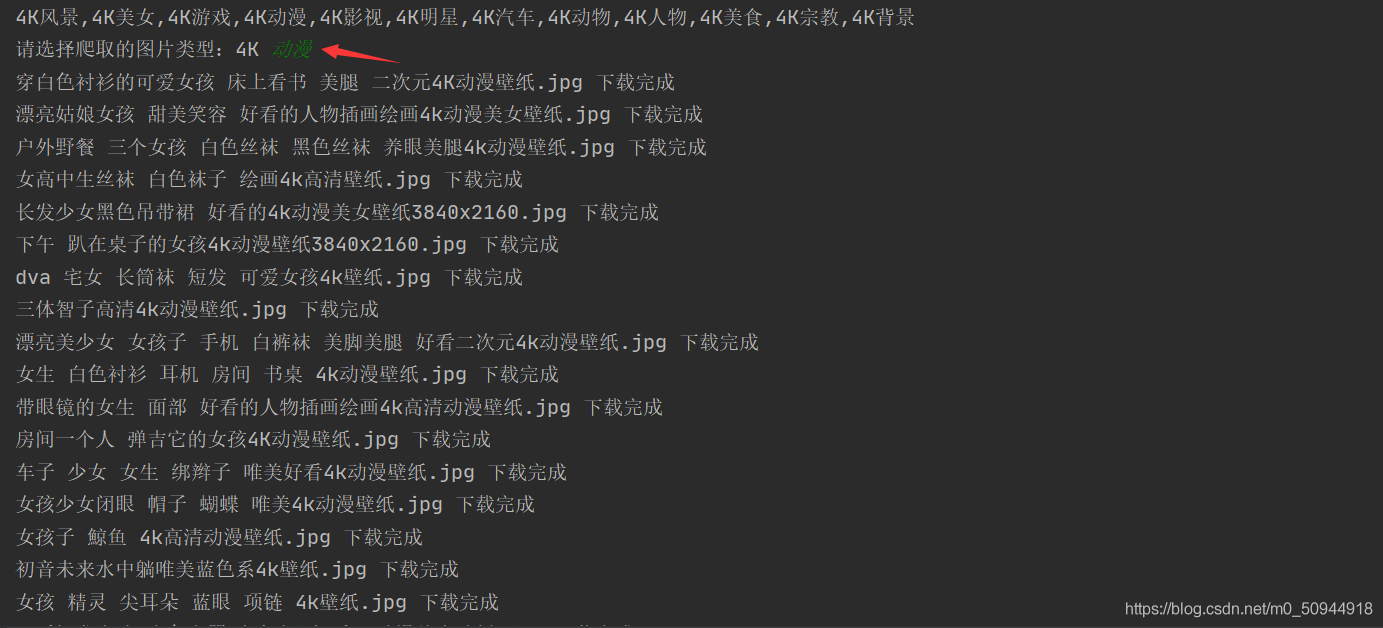
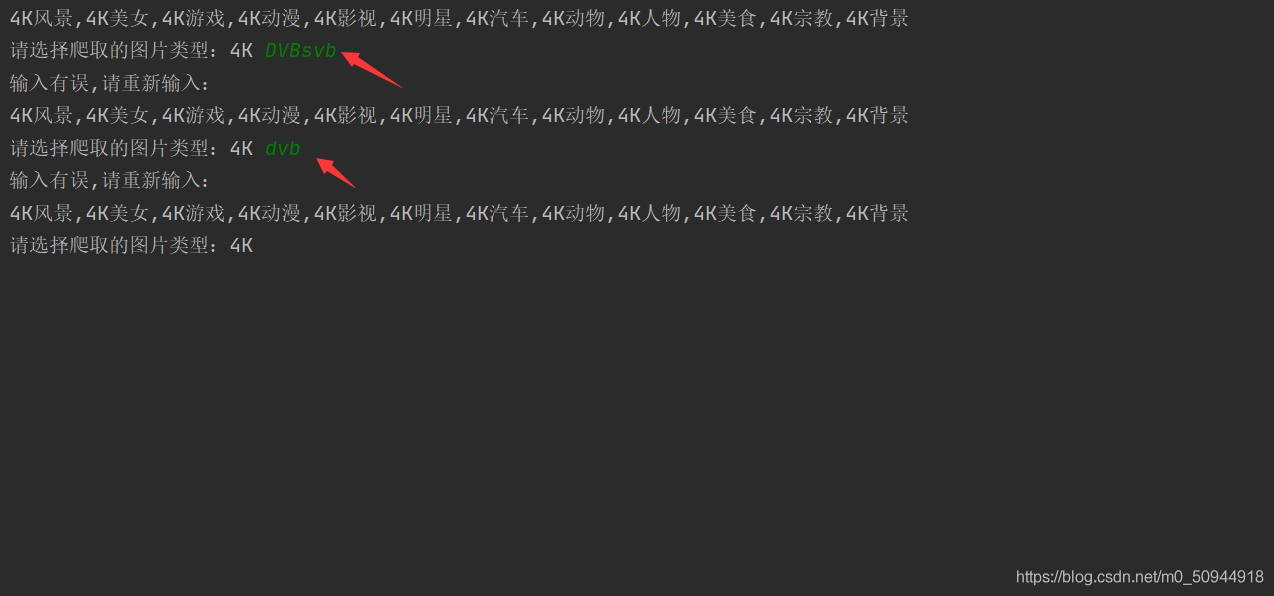
输入有误的话会执行循环,判断输入的内容类型是不是在列表里面
源码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/11/9 18:32
# @Author : huni
# @File : 爬彼岸图网.py
# @Software: PyCharm
import requests
from lxml import etree
import os
from pypinyin import lazy_pinyin
def main():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36'
}
while True:
typelist = ['fengjing','meinv','youxi','dongman','yingshi','mingxing','qiche','dongwu','renwu','meishi','zongjiao','beijing']
print('4K风景,4K美女,4K游戏,4K动漫,4K影视,4K明星,4K汽车,4K动物,4K人物,4K美食,4K宗教,4K背景')
searchtype = input('请选择爬取的图片类型:4K ')
res = True #判断是否全为中文 是中文就返回True
for w in searchtype:
if not '\u4e00' <= w <= '\u9fff':
res = False
if not res: #如果不是中文直接赋值给new_searchtype
new_searchtype = searchtype
if new_searchtype not in typelist:
print('输入有误,请重新输入:')
else:
getData(new_searchtype,headers)
break
else: #如果是中文就用拼音模块转成拼音再赋值给new_searchtype
new_searchtype = lazy_pinyin(searchtype)[0] + lazy_pinyin(searchtype)[1]
if new_searchtype not in typelist:
print('输入有误,请重新输入:')
else:
getData(new_searchtype,headers)
break
def getData(new_searchtype,headers):
for i in range(1,4):
if i == 1:
url = 'http://pic.netbian.com/4k' + new_searchtype +'/'
else:
url = 'http://pic.netbian.com/4k' + new_searchtype +'/' + 'index_' + str(i) + '.html'
response = requests.get(url=url,headers=headers)
response.encoding = 'gbk'
page_text = response.text
#解析src属性值,解析alt的属性值
tree = etree.HTML(page_text)
# with open()
li_list = tree.xpath('//*[@id="main"]/div[3]/ul/li')
#创建一个文件夹
if not os.path.exists('./picLibs'):
os.mkdir('./picLibs')
for li in li_list:
name = li.xpath('./a/img/@alt')[0] + '.jpg'
src = 'http://pic.netbian.com' + li.xpath('./a/img/@src')[0]
# print(name,src)
#请求图片进行储存
img_data = requests.get(url=src,headers=headers).content
img_path = 'picLibs/' + name
with open(img_path,'wb') as fp:
fp.write(img_data)
print(name,'下载完成')
if __name__ == '__main__':
main()
扩展阅读:
来自 优快云的 Refrain__WG 和 github的mozillazg
1判断全是英文
b = 'bilibili站'
b.isalpha() # 中英混合不适用
# True
b.encode('utf-8').isalpha()
# False
b.encode('utf-8')
# b'bilibili\xe7\xab\x99'
2.判断全是中文
word_1 = '如何再飘摇'
res = True
for w in word_1:
if not '\u4e00' <= w <= '\u9fff':
res = False
print(res)
# True
123456789
word_2 = '风停了云知道2333'
res = True
for w in word_2:
if not '\u4e00' <= w <= '\u9fff':
res = False
print(res)
# False
word_3 = 'abc风中有朵雨做的云abc'
res = True
for w in word_3:
if not '\u4e00' <= w <= '\u9fff':
res = False
print(res)
# False
4.汉字转拼音
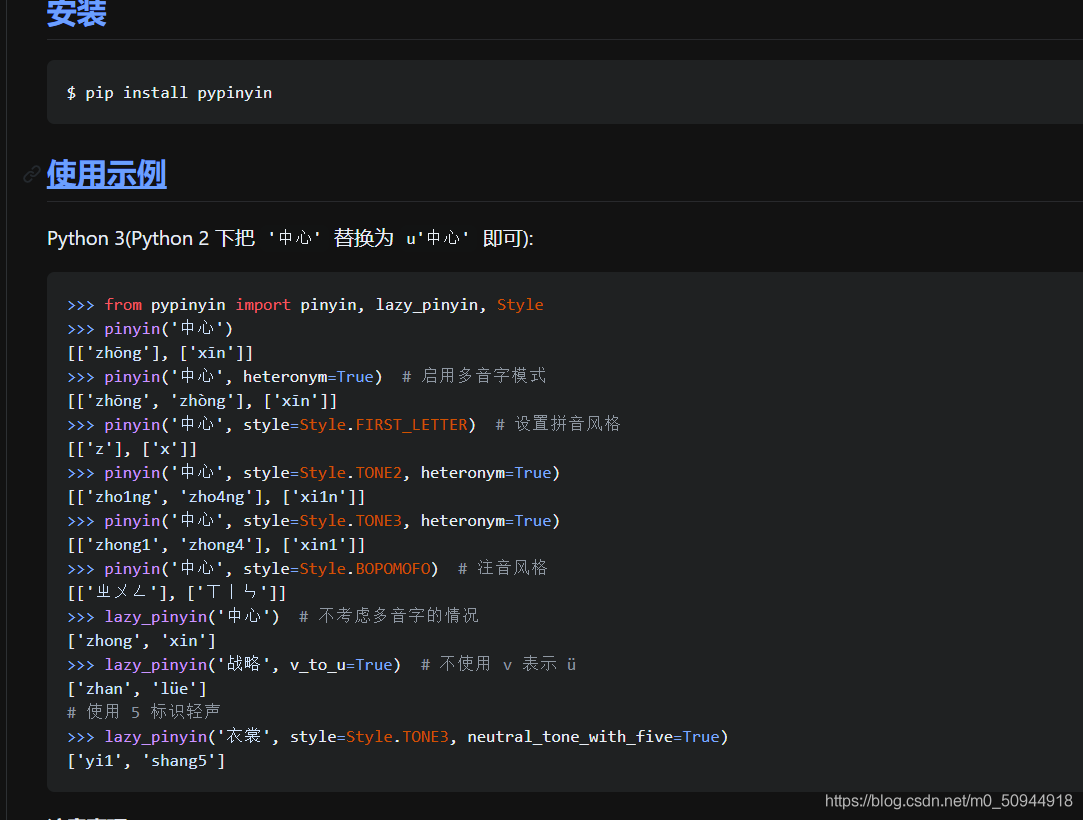
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取

















 23万+
23万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









