




Python应用最多的场景还是Web快速开发、爬虫、自动化运维。爬虫在开发过程中也有很多复用的过程,这里总结一下,以后也能省些事情。

1. 基本抓取网页
get方法
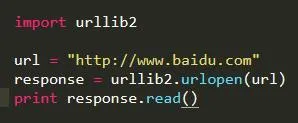
post方法
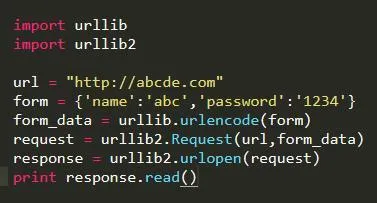
2. 使用代理IP
在开发爬虫过程中经常会遇到IP被封掉的情况,这时就需要用到代理IP;
在urllib2包中有ProxyHandler类,通过此类可以设置代理访问网页,如下代码片段:
 本文介绍了Python爬虫的七个实用技巧,包括基本的网页抓取、使用代理IP避免封禁、处理Cookies、伪装浏览器、应对验证码、处理gzip压缩数据以及利用多线程并发抓取,旨在提升爬虫开发的效率和成功率。
本文介绍了Python爬虫的七个实用技巧,包括基本的网页抓取、使用代理IP避免封禁、处理Cookies、伪装浏览器、应对验证码、处理gzip压缩数据以及利用多线程并发抓取,旨在提升爬虫开发的效率和成功率。
Python应用最多的场景还是Web快速开发、爬虫、自动化运维。爬虫在开发过程中也有很多复用的过程,这里总结一下,以后也能省些事情。
1. 基本抓取网页
get方法
post方法
2. 使用代理IP
在开发爬虫过程中经常会遇到IP被封掉的情况,这时就需要用到代理IP;
在urllib2包中有ProxyHandler类,通过此类可以设置代理访问网页,如下代码片段:
 2253
2253

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章






















 到【灌水乐园】发言
到【灌水乐园】发言






