




 本文介绍了一个爬虫实战案例,包括Python基础语法、第三方库使用、网页请求、解析及视频下载等步骤,展示了如何从特定网站抓取视频资源。
本文介绍了一个爬虫实战案例,包括Python基础语法、第三方库使用、网页请求、解析及视频下载等步骤,展示了如何从特定网站抓取视频资源。
学习前提
1、了解python基础语法
2、了解re、selenium、BeautifulSoup、os、requests等python第三方库
1.引入库
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
爬取网站视频需要引入的第三方库:
import os from selenium import webdriver import requests from bs4 import BeautifulSoup import re
模块用处:
1、os模块:文件目录操作模块,用于创建或者删除目录或文件。
2、selenium模块:python请求模块之一,用于某些特殊请求。
3、requests模块:用于请求网页地址。
4、BeautifulSoup模块:用于解析网页,获取页面元素或内容。
5、re模块:正则表达式,本程序中用于匹配视频链接。
2.请求网页地址
请求页面:
"""请求页面"""
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36"
} #请求
url = "http://www.kakadm.com/anime/2417/" #网页地址,这里以卡卡动漫中的无限斯特拉托斯为例
r = requests.get(url, headers=header)
html = r.text #以二进制打印页面
由上述代码获取如下页面:
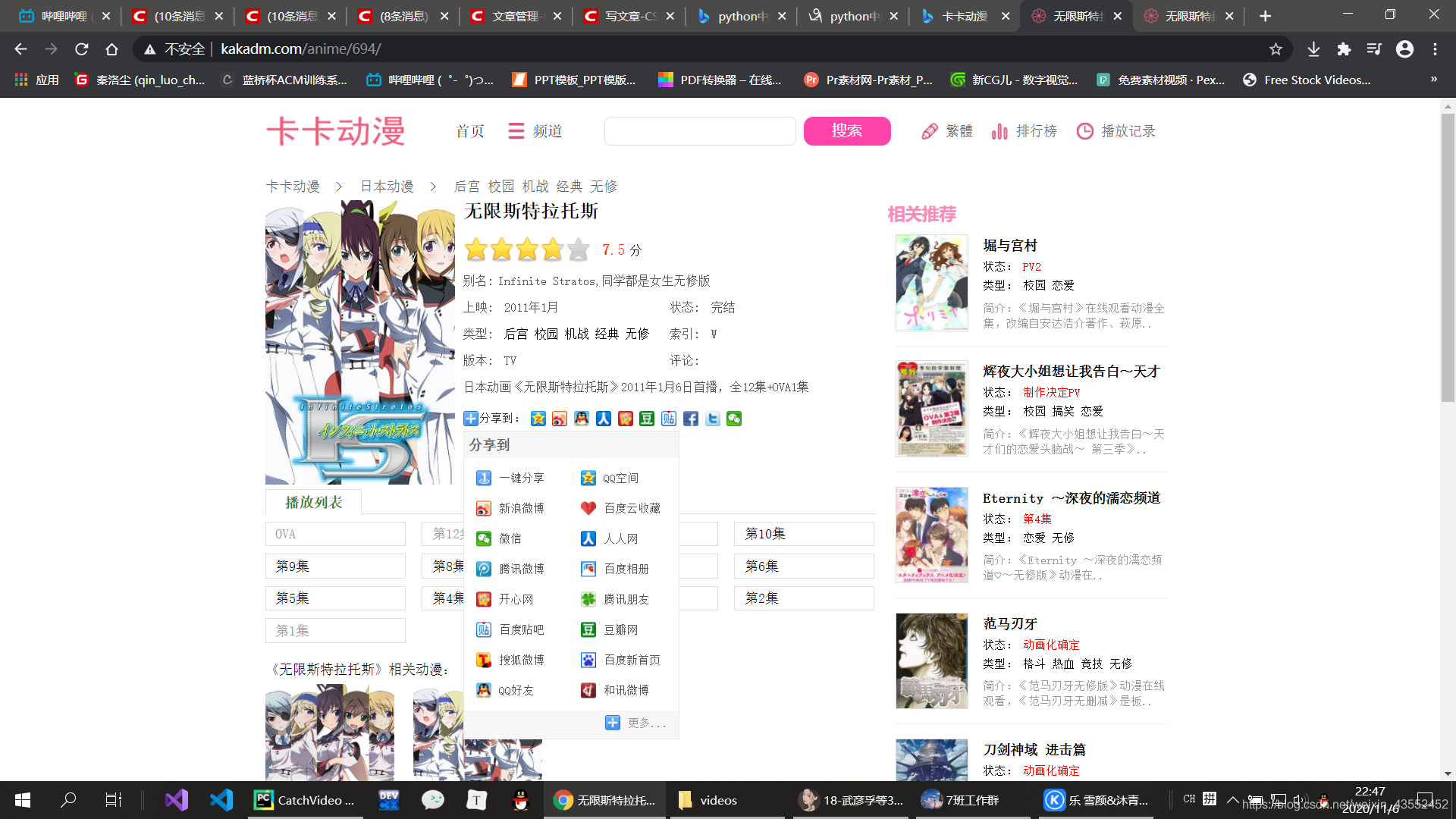
请求头(反爬机制中的一种):
headers中包含网页请求中的请求头,每一个浏览器都有属于自己的请求头,因此需要更改,以免请求失败
3.解析网页,获取播放链接
解析上述页面:
"""解析页面"""
soup = BeautifulSoup(html, "html.parser")
urls = soup.find("div", class_="movurl").find_all("a") #查找视频播放链接
videourls = []
for u in urls:
videourls.append(u.get("href")) #由分析网页元素可知,仅获取链接部分内容
# 获取视频播放地址
str = "http://www.kakadm.com/"
for index, item in enumerate(videourls):
videourls[index] = str + item #加上前缀,获取13个视频播放链接
由上述代码获取如下页面:
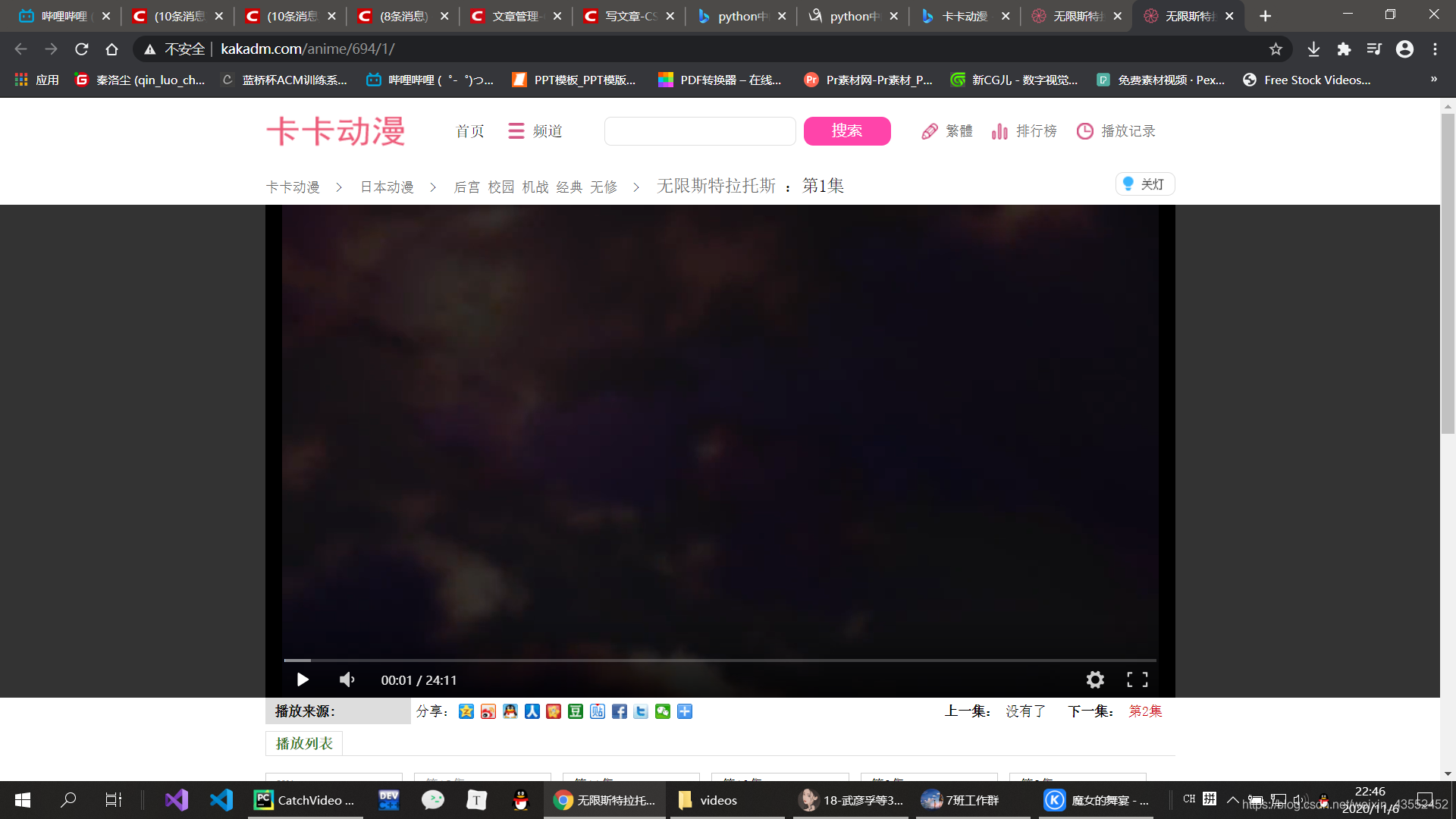
4.解析网页,获取视频源链接,即获取后缀名含.mp4的链接
由上述代码获取视频播放页面后,获取源视频链接:
# 请求获取视频源mp4
videos = []
title = []
chrome_options = webdriver.ChromeOptions()
# 使用headless无界面浏览器模式,即不需要打开浏览器
chrome_options.add_argument('--headless') # 增加无界面选项
chrome_options.add_argument('--disable-gpu') # 如果不加这个选项,有时定位会出现问题
flag = 0
name = ''
for u in videourls:
# 启动浏览器,获取网页源代码
b = webdriver.Chrome(options=chrome_options) # 建立Chrome的驱动
b.implicitly_wait(10) # 隐式等待,动态查找元素
b.get(u) # 在Chrome上打开网址
# 获取视频名字,如:无限斯特拉托斯
if flag == 0:
soup = BeautifulSoup(html, "html.parser")
name = soup.find("title").string.split('-')[0] # 获取标签内的内容
flag = 1
# 进入iframe内嵌网页
b.switch_to.frame("playbox") # 针对iframe标签,(id)
html = b.page_source # 打印页面
soup = BeautifulSoup(html, "html.parser")
t = soup.find("title").string.split(' ')[0] # 视频命名
v = re.findall(r'(http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+\.mp4)',
html) # 获取mp4网址
t = name + " " + t
title.append(t)
videos.append(v)
print(v)
b.quit() # 退出
由上述代码获取如下视频源链接:
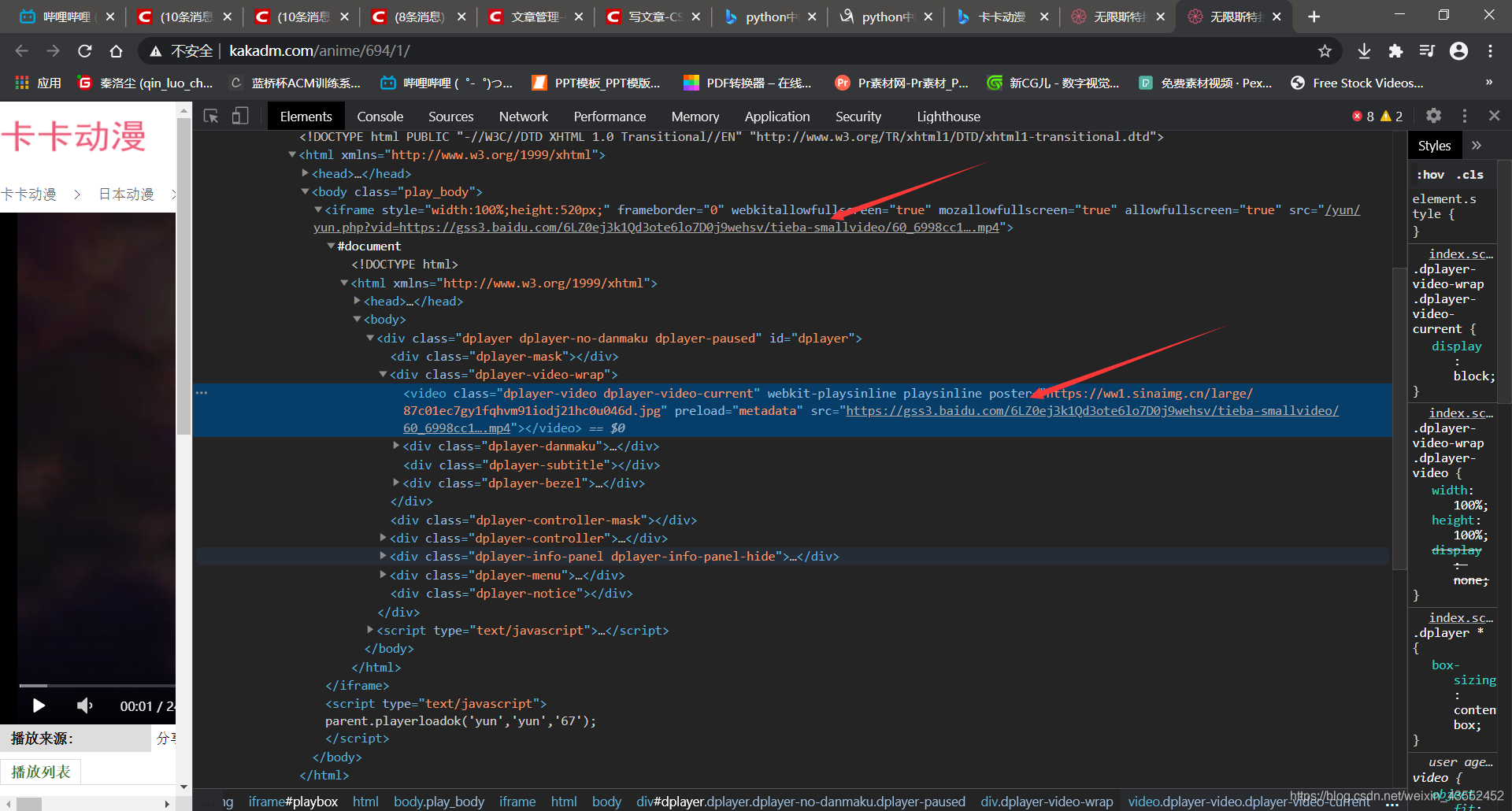
注意:
在本例子中,卡卡动漫里的视频源链接放在ifame标签中,这是基本反爬机制之一。ifame标签会隐藏其内的内容,用requests模块不能直接访问,需要在浏览器中访问,即需要selenium模块,通过针对iframe标签的方法b.switch_to.frame(id)
打开浏览器来访问iframe标签,并获取隐藏其中的视频源链接。
5.下载视频,并储存到指定文件夹
由上述代码获取视频源链接后,下载到指定文件目录:
"""下载mp4视频"""
i = 0 # 显示当前下载第几个视频
j = 0 # 遍历视频标题列表
# 创建视频文件目录
path = 'D:\Softdownload\Python\\videos\{}\\'.format(name)
if os.path.exists(path) == False: # 如果文件不存在
os.mkdir(path)
for index, item in enumerate(videos):
i += 1
print("正在下载第{}个视频".format(i))
file_name = title[j] + '.mp4' # 命名成mp4格式
j += 1
r = requests.get(videos[index][0], headers=header) # 请求里面的网址
with open(path + file_name, 'wb') as f: # 在指定文件夹下载视频,没有就创建
f.write(r.content)
由上述代码会建立如下文件目录:
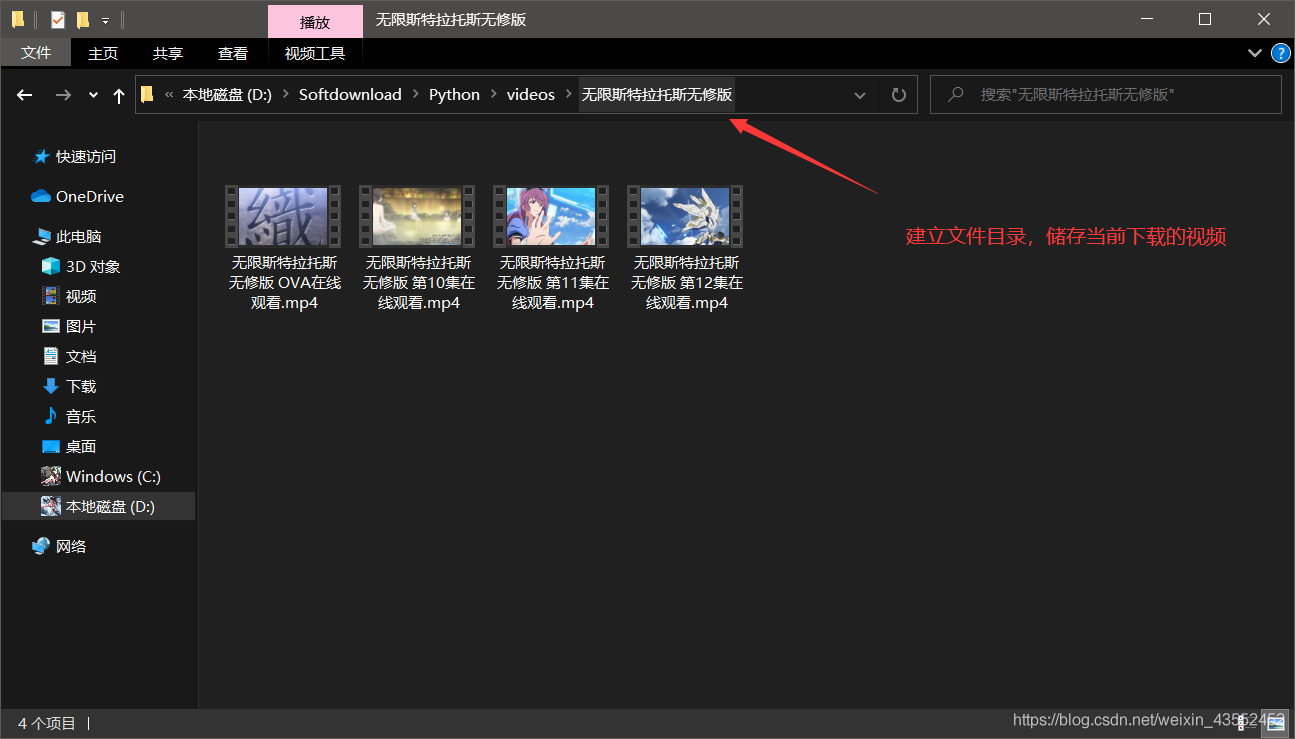
还是不难的哈!希望能从文中学到你想要得到的!

















 2979
2979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









