




 本文档详细解析了Scrapy爬虫过程中常见的错误及其解决方案,包括但不限于403错误的处理方法、items未正确传递的解决办法、项目不存在的排查步骤等。此外还提供了如何在命令行正确启动爬虫项目的指导。
本文档详细解析了Scrapy爬虫过程中常见的错误及其解决方案,包括但不限于403错误的处理方法、items未正确传递的解决办法、项目不存在的排查步骤等。此外还提供了如何在命令行正确启动爬虫项目的指导。
常见报错及解决方法
1. 缺请求头的报错,请求403
在setting文件加上请求头即可,修改完记得保存。

这个会在检查完环境之后,开启爬虫准备爬取时显示出错误,看到403,一般就是被反爬了,先检查一下请求头。
2. items没传、少传值或者不对应
报错:KeyError: 'DoubanItem does not support field: title1'
对应的,在items文件中,加上或修改相关的变量即可。


3. 没有项目
报错:KeyError: 'Spider not found: douban'
是否存在?是否保存?

4. 运行不了问题:Unknown command: crawl
在cmd或者终端中运行报错:

切换到项目目录下,再执行
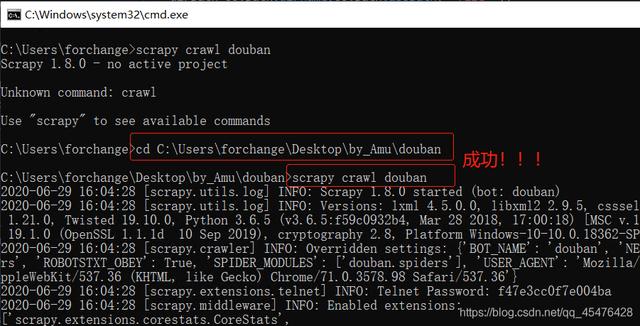
关于Unknown command: crawl更详细的解读,可以参考文章:https://blog.youkuaiyun.com/qq_45476428/article/details/108719410
关于scrapy的运行结果解读,参考:https://blog.youkuaiyun.com/qq_45476428/article/details/108701932
小彩蛋
其实,还可以把scrapy的运行结果设置不要打印到终端,当有报错直接抛出来即可。
方法一:在终端或cmd中运行,改为下面命令执行
scrapy crawl douban -s LOG_FILE=spider.log# douban 改为你的项目名字
方法二:在编辑器中运行,直接在setting.py 文件中添加以下代码:
# setting.py 文件中添加以下代码,即可去掉打印结果 LOG_LEVEL="WARNING"
方法三:在编辑器中运行,在setting.py 文件中添加以下5行代码:
# setting.py 文件中添加以下5行代码,去掉打印结果, LOG_FILE = "spider.log"LOG_STDOUT = True FEED_URI='output.csv'FEED_FORMAT='csv'FEED_EXPORT_ENCODING='ansi'

















 4884
4884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









