 大模型入门指南:免费资源与学习路线
大模型入门指南:免费资源与学习路线




2025年,DeepSeek-R1的发布在国内AI领域掀起了一场前所未有的开源风暴。作为一款性能卓越的开源大模型,它不仅开放了模型的获取权限,还主动分享算法细节以及优化策略,激发了整个行业的开放共享热潮。
与此同时,科研论文、技术博客和开源社区的讨论如雨后春笋般涌现,这种开放透明的氛围极大地推动了AI科研知识的共享与传播,吸引了更多研究者和开发者参与到大模型的创新与应用中。
不过,对于刚刚入门大模型的初学者而言,这些论文、研究中涉及的诸多高阶概念或许意味着较高的认知挑战。
一方面,国内外主流AI教科书的成书或更新时间,大多早于本轮生成式AI浪潮,对新近AI技术的发展缺乏全面覆盖。
另一方面,许多大模型“Know How”只能从一线实践中获取,且需要大量算力的投入,但像DeepSeek这样愿意分享此类知识的AI企业,依旧是少数。
令人庆幸的是,已经有一批一线AI研究者在从事大模型基础知识和应用经验的普及工作。
在国内,中国人民大学的科研团队于2023年3月底发布A Survey of Large Language Models论文,全面综述了大模型界的最新研究成果,此后,这篇综述持续更新,截至2025年3月,已有整整16个版本,最新一版文章达144页,引用了1000余篇论文。
去年年底,由上述文章整理而来的《大语言模型》一书,在历经数月的编辑之后,由高等教育出版社正式出版。与英文综述文章的定位不同,修订后的中文版更关注为大模型学习者供整体的技术讲解,对内容上进行了大范围的更新与重组,力图展现一个系统的大模型技术框架和路线图。
《大语言模型》一书由中国人民大学高瓴人工智能学院赵鑫教授和文继荣教授领衔主编,博士生李军毅、周昆和硕士唐天一参与编著,作者团队在大模型领域有着丰富的研究与开发经验,曾主导研发了文澜、玉兰等大模型。
编者团队认为,大模型研发的众多训练细节无法从已有的科学文献中直接获取,通常需要开展实验进行摸索。但实际上,很多研究人员并没有充足的算力资源去完成一次完整的大规模预训练实验,无法获取一手经验,极大限制了学术界在此次AI技术发展中所起到的作用。
然而,学术界在AI研究中的独特价值依然不可替代,且需要在多个领域持续发声并贡献力量。学术界更为长远和多元的研究视角,可以在大模型的基础理论研究中发挥重要作用,或是深入探索如AI安全、AI治理这样短期内难以变现,但对人类未来至关重要的议题。
本书前言中有这么一句话:“人类社会的技术发展从不会因为某个公司或某个国家的技术封锁而停滞不前。”《大语言模型》一书的出版,恰好为学术界提供了获取一线大模型知识和实践经验的渠道。这本书全面覆盖了大语言模型训练与使用的全流程,从预训练到微调与对齐,从使用技术到评测应用,帮助读者全面掌握大语言模型的核心技术。
在核心算法技术的基础之上,编者团队还提供了大量的代码实战与讲解,同时搭配相关的开发工具包LLMBox与YuLan大模型,供读者深入阅读理解相关技术。

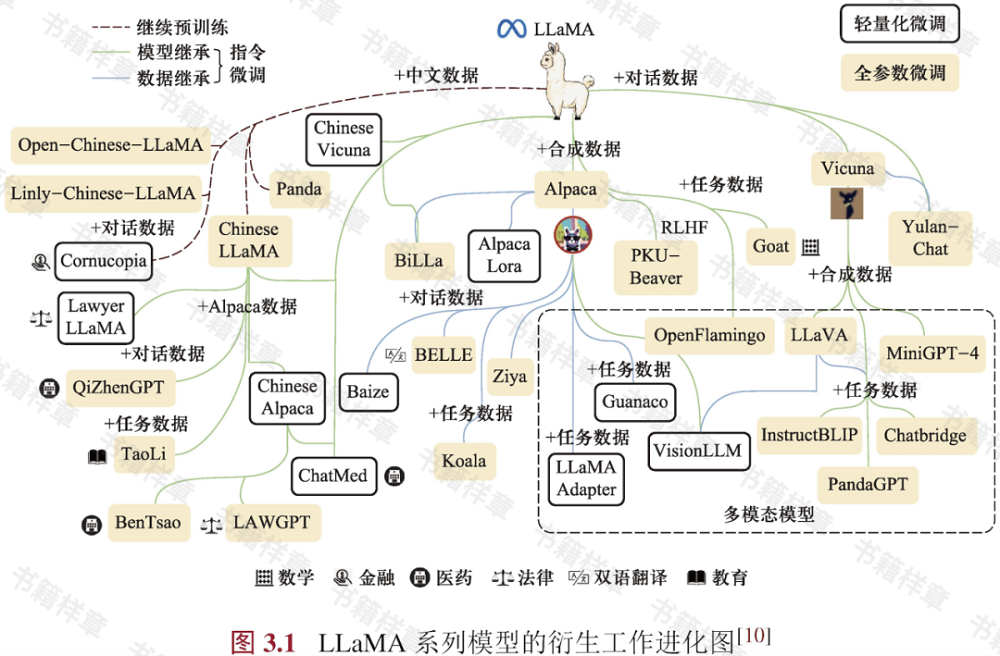
书中大量的可视化内容可帮助读者更好地理解相关概念,下方这张图表就呈现了基于LLaMA模型的各类衍生工作,通过继续预训练、指令微调等方法,LLaMA可以适配到不同的语言、多样的领域。
发布之际,《大语言模型》一书也得到了多位知名AI学者的推荐。北京智源人工智能研究院学术顾问委员会主任、美国国家工程院外籍院士张宏江称:“本书内容深入结合了编者在研发大模型过程中的第一手经验,......,可以作为深入学习大模型技术的参考书籍。”北京大学讲席教授、中国科学院院士鄂维南、清华大学智能科学讲席教授、中国工程院外籍院士张亚勤也为本书撰写了推荐语。
在AI技术飞速发展的当下,《大语言模型》的出版恰逢其时,相信无论是普通读者还是专业读者,都能从此书中获得关于AI前沿技术的最新见解。
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
第一不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来: 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

















 8286
8286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









