




 本文深入探讨Redis的分布式解决方案,包括主从复制、哨兵机制、Z轴拆分策略及其实现方式,如Modula、Random、Ketama一致性Hash。同时,介绍了Twemproxy和Predixy等代理层的搭建过程,以及Redis Cluster的工作原理和操作演示。
本文深入探讨Redis的分布式解决方案,包括主从复制、哨兵机制、Z轴拆分策略及其实现方式,如Modula、Random、Ketama一致性Hash。同时,介绍了Twemproxy和Predixy等代理层的搭建过程,以及Redis Cluster的工作原理和操作演示。
文章目录
容量问题
单机redis在使用的时候会碰到三个问题:单点故障、容量不足、访问压力。
- 因此我们可以对redis进行AKF拆分,站在x轴的角度上可以对redis进行 主从复制 + 哨兵机制。
- 主从复制:slave做master的全量备份保证数据的可靠性。master对外提供读写,slave对外提供读操作(读写分离),解决了部分访问压力。
- 哨兵机制:对master做高可用,使用 哨兵集群 监控master健康状态,哨兵之间相互通信,如果发现master挂了会进行投票选举 其中一个个slave作为新的master。解决了单点故障的问题。
- 但是由于slave是master的全量数据,在容量这个维度上来说,redis依然是一个单实例的。对于臃肿的redis实例来说,还需要对其进行y轴个z轴的拆分。
Z轴拆分
原因
Y轴拆分后某一业务的数据量还是很大,我们可以对Z轴方向上,在Client端根据 算法 继续拆分。(sharding 分片)
1. modula(hsah + 取模):
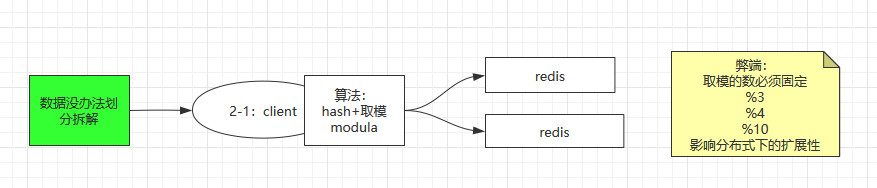
- 这种方式是在Client增加算法逻辑,把要存入数据的进行 % 运算,后边有几个redis实例,就和几进行 % 运算,根据取模的值,把数据存入到不同的redis实例。
优点: 简单,容易操作。
缺点: 取模的值是固定的,影响分布式下的扩展性,如果添加新的redis实例会使 模数值 发生改变,再取数据的时候根据 模数 去取就无法查找到数据了。
2. random:

- Client把数据随机放到不同的redis实例中:
应用
随机把数据放入不同的redis,取出成本很高?根本找不到数据?
如果存入的是一个list类型(lpush),key为ooxx,那么就会在两个redis中都生成ooxx的key,这个时候消费者并不是执行lpush的Client,而是执行rpop的另一个Client,都会从ooxx中取数据,无论从哪个redis取,都会取到key为ooxx的数据。这样就形成了一个类似于消息队列的功能。
3. ketama(一致性hash):
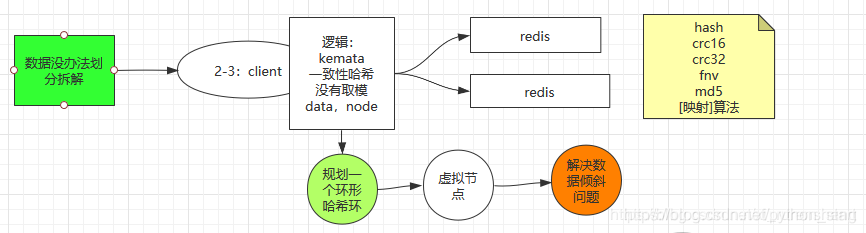
- 在得到一个长度随机的字符串后(redis的key),经过算法得到一个等宽的其他的值(算法:hash、crc16、crc32、fnv、md5),这个值会和字符串做一个映射。
- 和hash取模算法不同的是,一致性hash没有取模的过程(即:不会影响分布式扩展性),并且要求key和node都要参与计算。
- 会在内存中虚拟出一个环形(哈希环)。

- 哈希环由0 -2^32个数字组成,每一个数字都是一个点。无论后面有多少个redis实例,或新增,或减少,都会给这些redis实例一个ID号(或者IP+Port之类的)唯一标识。
优点:
- 没有固定node数量的限制,不会造成全局洗牌。
缺点:
- 新增节点后,造成一小部分数据无法命中。
- 如上图,新增一个节点 node3,把node3的ID进行hash运算得到一个数值,这个数值对应 哈希环 的点 恰好在之前数据映射的点和它存入node之间(data -> node2 变为 data -> node3 -> node2), 此时如果查询data,不会从node2查询,而是会从node3里面查找data,因此查询结果为null。
- 这种方式只适合做缓存而不适合做数据库,缓存大多为期限,即使node2里面data数据永远不会被查询到,data也会随着时间的推移而被清除掉,或者开启缓存清理策略LRU、LFU。并且node3里面无法查询到数据,可以走数据库从新缓存到node3(缓存击穿),也可以修改为从比自己大的两个node中查找数据。
扩展:虚拟节点
- 原因
如果node1和node2映射在哈希环的点分别在最左边和最右边,把哈希环切分成了 上半环 和 下半环,在添加数据的时候就可能出现 数据集中在某个半环上而导致 数据量的倾斜。 - 解决
我们可以每个node ID后面依次拼10个数字,让一个ID变成10个,用这些ID做hash运算映射到 哈希环 不同的点上,如果是两个设备在 哈希环 上面就会有20个点,这样做的目的是让一个物理设备出现在多个点上,就可以间接的解决数据倾斜的问题。
redis的连接成本很高
可以在Client和redis之间增加一个代理层(proxy),类似于Nginx这种应用层 的反向代理,基于反向代理的基础上负载均衡服务器。
- redis自带的拆分:cluster
- twemproxy
- predixy
扩展
proxy是不需要记录Client状态,本身不存在数据库存储,所以proxy是无状态的 ,很容易的就可以把proxy一变多。
为了提高可用性,可以搭建LVS四层负载均衡服务器对两个proxy做负载均衡。
但是LVS也是一个单点,并且不能对后端的proxy集群做健康检查,所以可以使用keepalived建立VIP对LVS做主备HA高可用。

redis自带的拆分:cluster
规避了ketama新增redis实例时截断数据
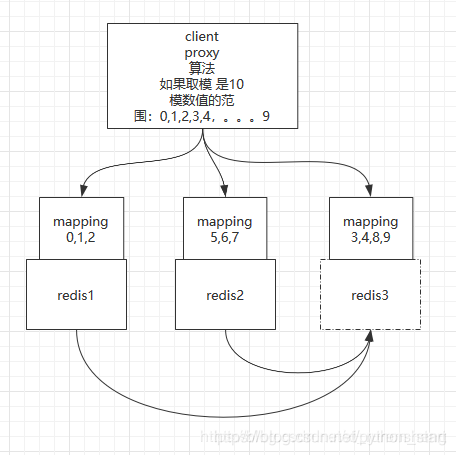
拆分逻辑中进行预分区
redis1映射0,1,2,3,4
redis2映射5,6,7,8,9
(各领取5个槽位)。
如果redis3加入集群,会让redis1和redis2让出几个槽位,比如从redis1中拿到了3和4,在redis2中拿到了8和9(如上图)。移动数据的时候,不需要把redis全部rehash,只需要把3,4,8,9槽位的时点数据找到直接传输给redis3,redis3接收完数据后,会根据时点数据跟redis1和redis2传输期间内的数据做一个追平更新,追平的一刹那,再往3,4,8,9槽位存数据就会直接存入redis3。
Client只需要知道映射关系,就可以根据槽位正确的读取数据了
存取数据
Client想要存入k1,会随机访问redis1和redis2。可以让每个redis实例都能当家做主。k1随机进入一个redis实例后(假设这个实例是redis2),redis2会先拿k1进行hash取模算出槽位,用计算的槽位和自己的mapping映射的槽位做一个匹配,如果和自己匹配就直接存入redis2,如果不匹配再和redis2内保存的其他实例的槽位映射关系进行匹配,就能找到k1需要存的redis实例是哪个,把k1返回给Client并重定向到正确的redis实例中(假设匹配结果为redis3)。redis3拿到k1后同样要进行hash运算并且把结果和自身映射槽位进行匹配,匹配成功直接存入自己这个实例当中。
Redis 集群没有使用一致性hash, 而是引入了 哈希槽的概念。
Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽.集群的每个节点负责一部分hash槽
问题: 聚合操作很难实现
操作的key都在相同的节点,可以用 hash tag 。
比如:把key设置成为{oo}k1,{oo}k2,{oo}k3这种带有{}内部有固定标识的 格式,这样在存入key的时候会使用 oo 进行取模,而不会使用k1,k2,k3进行取模。进而存入同一个redis节点。
twemproxy搭建过程
git clone https://github.com/twitter/twemproxy.git
yum install automake libtool -y
cd twemproxy
autoreconf -fvi
报错:autoconf版本过低
解决办法
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-6.repo
yum clean all
yum install autoconf268
cd twemproxy
autoconf268 -fvi
./configure
make
cd scripts/
cp nutcracker.init /etc/init.d/twemproxy
cd /etc/init.d/
chmod +x twemproxy
mkdir /etc/nutcracker/
cd twemproxy /conf
cp ./* /etc/nutcracker/
cd twemproxy/src
cp nutcracker /usr/bin
cd /etc/nutcracker
cp nutcracker.yml nutcracker.yml.back
vi nutcracker.yml
service twemproxy start
nutcracker.yml
alpha:
listen: 127.0.0.1:22121
hash: fnv1a_64
distribution: ketama
auto_eject_hosts: true
redis: true
server_retry_timeout: 2000
server_failure_limit: 1
servers:
- 127.0.0.1:6379:1
- 127.0.0.1:6380:1
客户端直接连接22121端口
谈到集群管理不得不又说到数据的分片管理(shard),为了满足数据的日益增长和扩展性,数据存储系统一般都需要进行一定的分片,如传统的MySQL进行横向分表和纵向分表,然后应用程序访问正确的位置就需要找的正确的表。这时候,这个数据定向工作一般有三个位置可以放:
数据存储系统本身支持,Redis Cluster就是典型的试图在数据存储系统上支持分片;
客户端支持,Memcached的客户端对分片的支持就是客户端层面的;
代理支持,twemproxy就是试图在服务器端和客户端中间建代理支持;
predixy搭建过程
mkdir predixy
cd predixy/
wget https://github.com/joyieldInc/predixy/releases/download/1.0.5/predixy-1.0.5-bin-amd64-linux.tar.gz
cd predixy/
vi predixy.conf
GENERAL模块:Bind 127.0.0.1:7617 //设置对外暴露的统一接口
SERVERS模块:Include sentinel.conf //引入哨兵配置文件
vi sentinel.conf
sentinel.conf
SentinelServerPool {
Databases 16
Hash crc16
HashTag "{}"
Distribution modula
MasterReadPriority 60
StaticSlaveReadPriority 50
DynamicSlaveReadPriority 50
RefreshInterval 1
ServerTimeout 1
ServerFailureLimit 10
ServerRetryTimeout 1
KeepAlive 120
Sentinels {
+ 127.0.0.1:26379 //三个哨兵的 IP+端口
+ 127.0.0.1:26380
+ 127.0.0.1:26381
}
Group ooxx { //一套哨兵可以监控多套主从,一个Group为一套主从。
} //Client写入的数据会被打散分别存入ooxx主从的master和xxoo主从的master。
Group xxoo {
}
}
配置哨兵
vi 26379.conf
port 26379
sentinel monitor ooxx 127.0.0.1 36379 2 //第一套主从ooxx的master ID+ Port,组为ooxx
sentinel monitor xxoo 127.0.0.1 46379 2 //第二套主从xxoo的master ID+ Port 组为xxoo
vi 26380.conf
port 26380
sentinel monitor ooxx 127.0.0.1 36379 2
sentinel monitor xxoo 127.0.0.1 46379 2
vi 26381.conf
port 26381
sentinel monitor ooxx 127.0.0.1 36379 2
sentinel monitor xxoo 127.0.0.1 46379 2
#启动哨兵
redis-server 26379.conf --sentinel
redis-server 26380.conf --sentinel
redis-server 26381.conf --sentinel
# 建立四个个文件夹36379、36380、46379、46380,分别进去启动对应的redis
redis-server --port 36379
redis-server --port 46379
//开启两个从机,追随对应的主机
redis-server --port 36380 --replicaof 127.0.0.1 36379
redis-server --port 46380 --replicaof 127.0.0.1 46379
//进入代理predixy的根目录
./predixy ../conf/predixy.conf
//客户端连接
redis-cli -p 7617
cluster操作演示
#自带配置
cd utils/create-cluster
vim create-cluster
./create-cluster start
./create-cluster create
redis-cli -c -p 3000
./create-cluster satrt //启动节点
./create-cluster create //创建集群
./create-cluster stop //停止集群和节点
./create-cluster clean //清理数据文件
# 手工启动的redis实例需要在配置文件中开启 cluster-enabled yes
redis-cli --cluster create 127.0.0.1:30001 127.0.0.1:30002 127.0.0.1:30003 127.0.0.1:30004 127.0.0.1:30005 127.0.0.1:30006 --cluster-replicas 1
redis-cli --cluster reshard 127.0.0.1:30001
redis-cli --cluster info 127.0.0.1:30001 //随便选一个节点的ip端口
redis-cli --cluster check 127.0.0.1:30001
总结:
- 三种搭建都是分摊redis的内存压力,将数据分到不同的redis
- 正常数据会分到不同节点上,不支持事务
- 人为干涉将数据分到同一个redis从而支持事务,watch也是一样的道理
- {tag}key 可以分发到同一redis支持事务

















 1545
1545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









