




 本文利用Python对北京二手房数据进行处理和Pyecharts可视化,揭示各城区房源数量、平均价格、房屋朝向等关键信息。丰台、朝阳、海淀、昌平房源最多,东城、西城、海淀平均价格最高。
本文利用Python对北京二手房数据进行处理和Pyecharts可视化,揭示各城区房源数量、平均价格、房屋朝向等关键信息。丰台、朝阳、海淀、昌平房源最多,东城、西城、海淀平均价格最高。
前言
嗨喽~大家好呀,这里是魔王呐 ❤ ~!

今天我们的目的想必大家看标题就能明白了~
准备
首先,我们要提前准备好数据
然后打开我们的数据分析工具: Jupyter

代码及效果展示
导入模块
# 导入做数据处理的模块pandas
import pandas as pd
# 导入绘图模块pyecharts,*号代表模块里面的所有图形
from pyecharts.charts import *
from pyecharts import options as opts
数据处理
1.读取数据
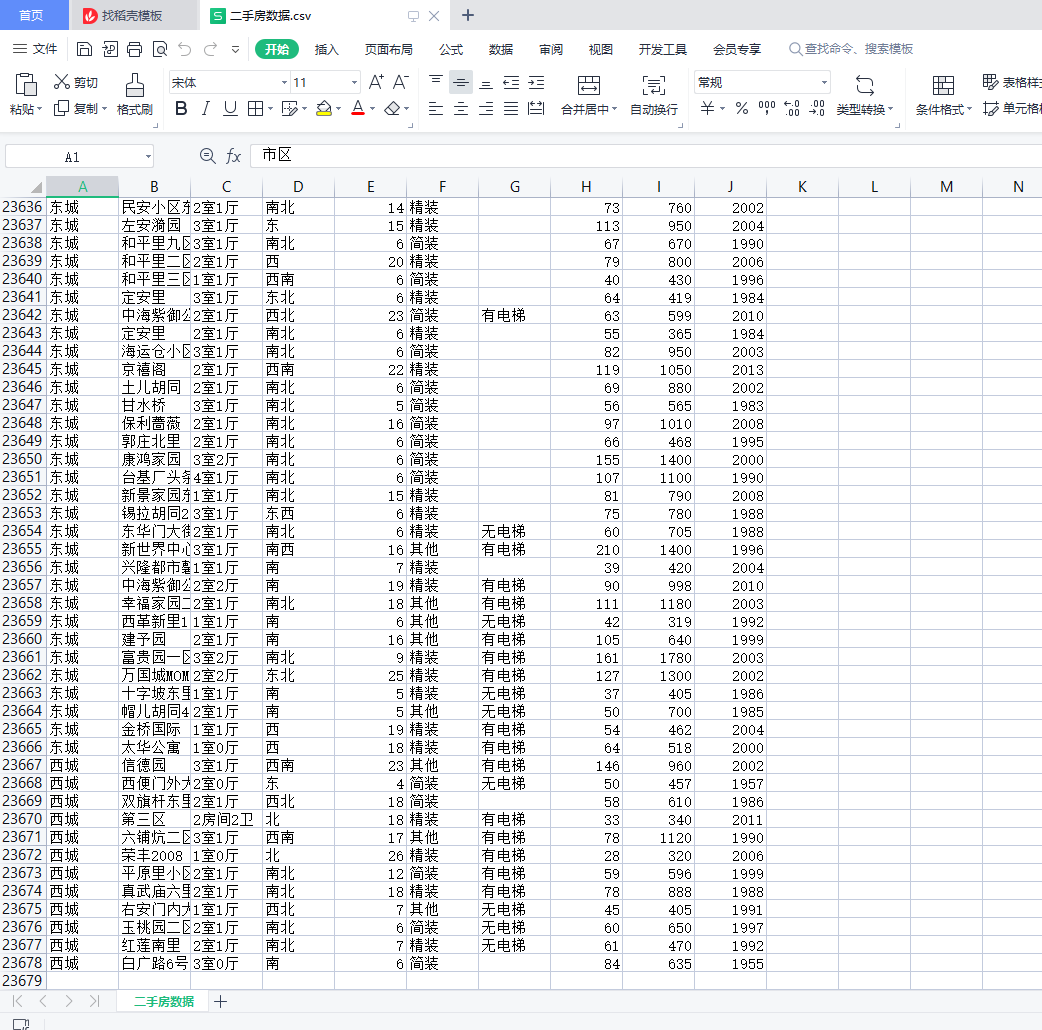
导入数据
设置编码encoding='gbk'
设置解释器为engine='python'
df = pd.read_csv('二手房数据.csv', encoding='gbk', engine='python')
df
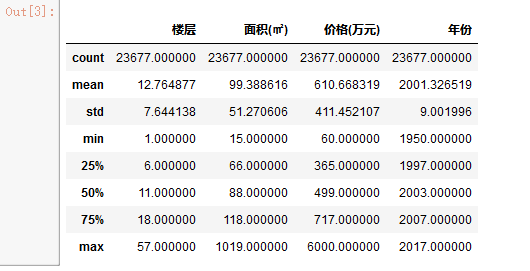
2.查看表格数据描述
describe可以直接计算数值类型数据的平均值,标准差
df.describe()
3.查看表格是否有数据缺失
通过isnull查找出包含缺失值的字段
然后进行求和,计算每一列的缺失数据的数量
df.isnull().sum()

可以看到电梯数据缺失8257行
4.查看电梯列共有几种值
通过unique可以统计数据里面出现了几种值
方便后面进行填充
df['电梯'].unique()

5.缺失值填充
用“未知”填充缺失值
缺失值的处理方式有两种
第一种删除,第二种填补
-
缺失值少,就直接删除
-
缺失值多,就进行填补
这里缺失值占比较多,所以进行填补
df['电梯'].fillna('未知',inplace=True)
# 填补之后查看是否还有缺失值
df.isnull().sum()

6.查看房屋朝向数据
查看朝向值的种类
df['朝向'].unique()

朝向数据包含了‘西南’和‘南西’两个方向,将其合并为一个方向‘西南’:
# replace(被替换的值,替换后的值):
df['朝向'] = df['朝向'].str.replace('南西','西南')
df['朝向'].unique()

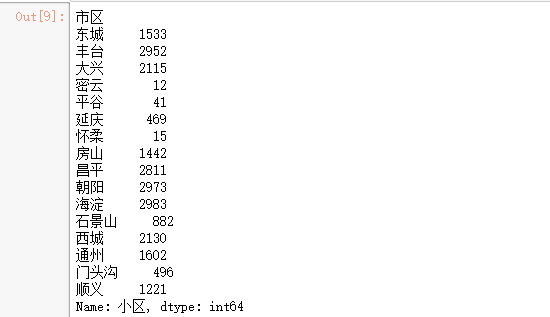
可以看到,丰台、朝阳、海淀、昌平在售的房源数量最多,高达12000多套,占了总量的1/2
🎯 博主文章素材、解答、源码、教程领取处:点击
Pyecharts可视化
1.统计各城区二手房数据
# 这里我们要用到分组
g = df.groupby('市区')
df_region = g.count()['小区']
region = df_region.index.tolist()
count = df_region.values.tolist()
df_region
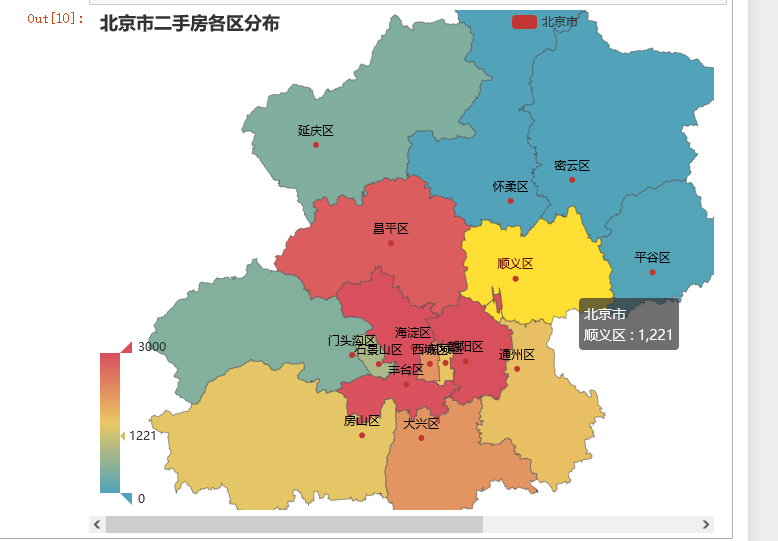
1.各城区二手房数量北京市地图
# 各城区二手房数量北京市地图
new = [x + '区' for x in region]
m = (
Map()
.add('北京市', [list(z) for z in zip(new, count)], '北京')
.set_global_opts(
title_opts=opts.TitleOpts(title='北京市二手房各区分布'),
visualmap_opts=opts.VisualMapOpts(max_=3000),
)
)
m.render_notebook()
2.各城区二手房数量-平均价格柱状图
df_price = g 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1773
1773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









