




 本文介绍了如何使用Python进行微博舞蹈视频的数据采集。通过讲解requests和pprint模块的运用,详细阐述了从找到目标网址到发送网络请求,再到解析数据和保存视频文件的全过程。适合初学者了解爬虫基本原理和实践操作。
本文介绍了如何使用Python进行微博舞蹈视频的数据采集。通过讲解requests和pprint模块的运用,详细阐述了从找到目标网址到发送网络请求,再到解析数据和保存视频文件的全过程。适合初学者了解爬虫基本原理和实践操作。
前言
嗨喽!大家好,这里是魔王~
今天,我们的目标是微博数据采集,爬的是那些跳舞的小姐姐视频

知识点
- requests
- pprint
开发环境
版 本:python 3.8
编辑器:pycharm 2021.2
爬虫原理
作用:批量获取互联网数据(文本, 图片, 音频, 视频)
本质:一次次的请求与响应

案例实现
1. 导入模块
import requests
import pprint
2. 找到目标网址
打开开发者工具,选中Fetch/XHR,选中数据所在的标签,找到目标所在url
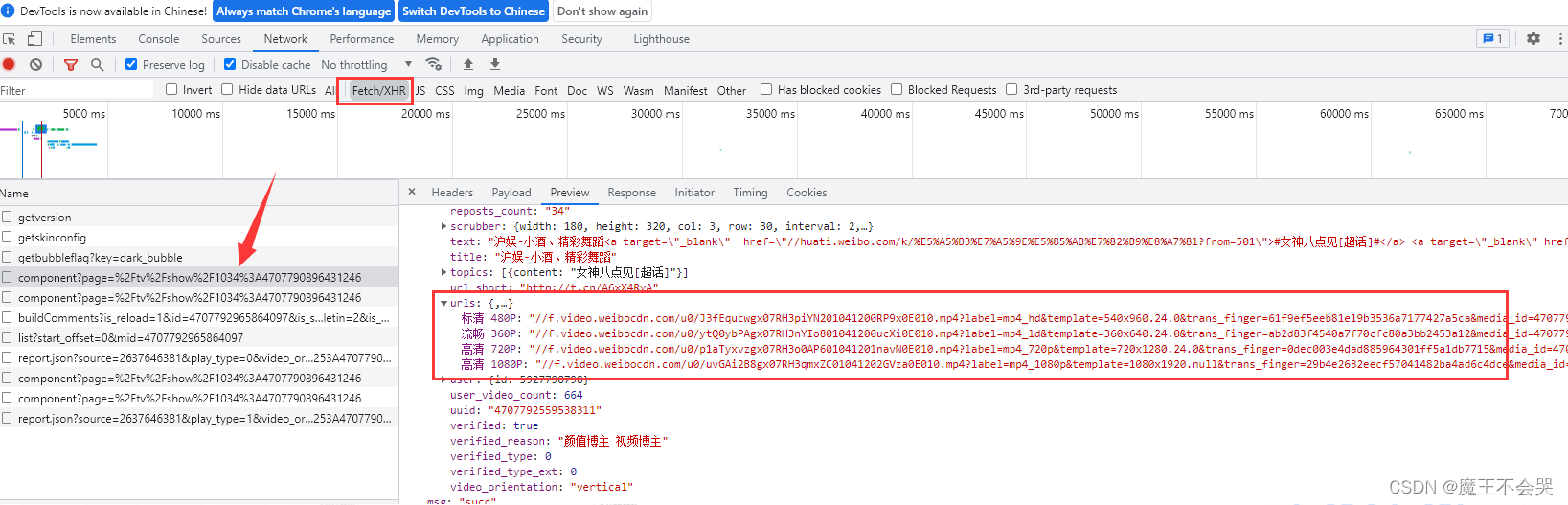
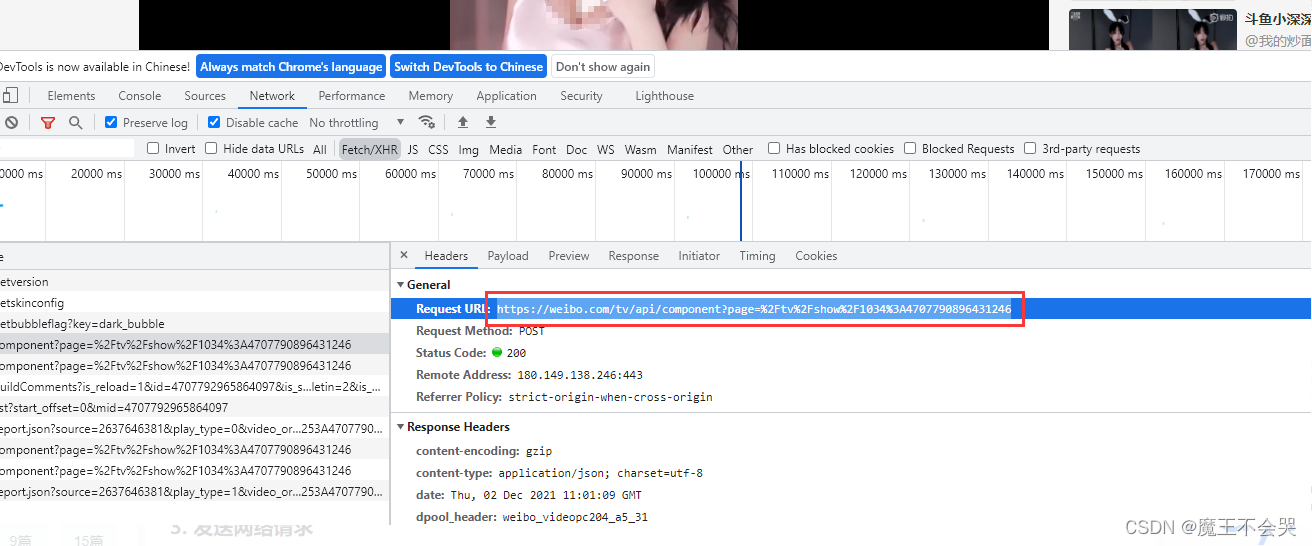
https://www.weibo.com/tv/api/component?page=/tv/channel/4379160563414111/editor
3. 发送网络请求
headers = {
'cookie': '',
'referer': 'https://weibo.com/tv/channel/4379160563414111/editor',
'user-agent': '',
}
data = {
'data': '{"Component_Channel_Editor":{"cid":"4379160563414111","count":9}}'
}
url = 'https://www.weibo.com/tv/api/component?page=/tv/channel/4379160563414111/editor'
json_data = requests.post(url=url, headers=headers, data=data).json()
4. 获取数据
json_data_2 = requests.post(url=url_1, headers=headers, data=data_1).json()
5. 筛选数据
dict_urls = json_data_2['data']['Component_Play_Playinfo']['urls']
video_url = "https:" + dict_urls[list(dict_urls.keys())[0]]
print(title + "\t" + video_url)
6. 保存数据
video_data = requests.get(video_url).content
with open(f'video\\{title}.mp4', mode='wb') as f:
f.write(video_data)
print(title, "爬取成功................")
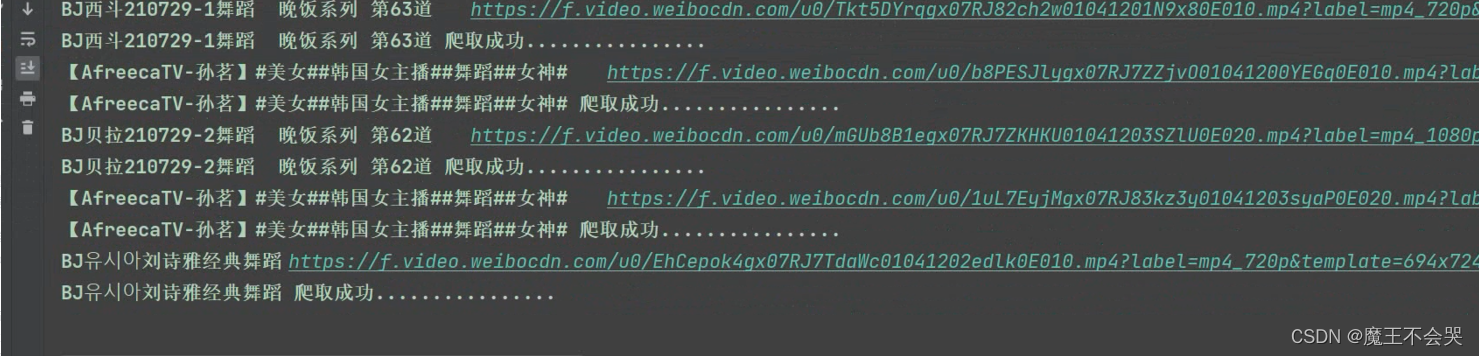
好了,我的这篇文章写到这里就结束啦!
有更多建议或问题可以评论区或私信我哦!一起加油努力叭(ง •_•)ง
喜欢就关注一下博主,或点赞收藏评论一下我的文章叭!!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









