



你是否也曾遇到过这样的窘境:刚跟AI助手交代完关键信息,转头再问相关问题,它却像从没听过一样,完全“失忆”?其实,这并非个例,而是多数AI助手在对话连续性上的普遍痛点。
不妨设想这样一个场景:你正在用AI代理处理公司的核心文档,比如季度财报分析。第一次提问时,它能精准定位文档中的关键数据,给出条理清晰的解读;可当你追问“这份财报里的研发投入环比增长多少,对下季度产品迭代有何影响”时,它却像重启了一样,重新从头扫描整个文档,不仅浪费了大量时间,还额外消耗了不少令牌——仿佛之前的互动从未发生过。
这种“聊完就忘”的问题,根源在于传统的检索增强生成(RAG)代理,本质上就是“数字金鱼”:面对单个查询时,它能凭借即时检索展现出不错的短期响应能力,但一旦涉及多轮对话的长期记忆,就完全“失灵”了。
今天,我们就来拆解这个核心难题,看看如何让AI助手既能记住关键信息、持续进化,又能严格控制令牌开销。

一、为什么传统RAG代理总爱“失忆”?
要解决问题,先得找到症结。传统RAG系统的“健忘症”,不仅会拉低工作效率,还会让你的令牌成本在不知不觉中飙升,背后其实是两大核心缺陷在作祟。
1. 根深蒂固的“单次查询依赖症”
传统RAG的工作逻辑看似合理:接收用户查询→检索相关文档片段→将片段嵌入提示词→生成回答。但这套流程有个致命问题——每一次查询都是“从零开始”。
就像你雇了个临时研究助理,每次问完问题,他就把所有笔记当场撕掉,下次提问时,又得重新找资料、记笔记,完全不记得上一次的沟通内容。比如你第一次让AI分析“产品A的用户流失原因”,它检索了用户反馈文档并给出结论;可当你接着问“那针对这些原因,有哪些可行的改进方案”时,它又得重新检索一遍用户反馈,甚至可能重复之前已经提到过的流失点——因为它没有“记忆”,每一次互动都是独立的“新任务”。
2. 无法避免的“令牌雪崩陷阱”
为了弥补记忆缺陷,有些传统RAG系统会尝试“笨办法”:把每一轮对话的内容都塞进提示词里,试图让AI“带着历史记录干活”。但这会直接引发“令牌雪崩”——随着对话轮次增加,上下文长度会呈指数级增长,很快就会触达大语言模型的上下文窗口上限。
即便像GPT-4o这样支持128K上下文窗口的模型,在多轮复杂对话中也会力不从心。Anthropic的研究数据就显示,即便把上下文窗口扩大到200K,如果没有智能的记忆管理机制,面对10轮以上的深度互动,模型依然会出现响应延迟、信息遗漏的问题。
更直观的是成本问题:按GPT-4o每1K令牌0.03美元的计费标准,如果一个对话的上下文膨胀到50K令牌,单次查询的成本就高达1.5美元。要是团队里有100个用户都在进行这类对话,仅令牌开销就会达到150美元——而这些成本中,很大一部分都花在了重复、冗余的历史信息上,原本通过简洁总结就能避免。
二、破局之道:记忆增强型RAG,给AI一个“可成长的数字笔记本”
想要让AI助手摆脱“健忘症”,同时控制令牌成本,关键在于跳出“单次检索”的思维定式——给AI一个能持续积累、随时调用的“数字笔记本”,这就是记忆增强型RAG的核心逻辑。
它不再让AI每次都“从零检索”,而是让AI像人类一样,在每轮互动后主动记录关键信息,随着对话深入不断丰富“笔记本”内容;后续提问时,只需调取“笔记本”里的核心总结,而非重复加载全部历史文档或对话,既保留了记忆连续性,又大幅压缩了上下文长度。
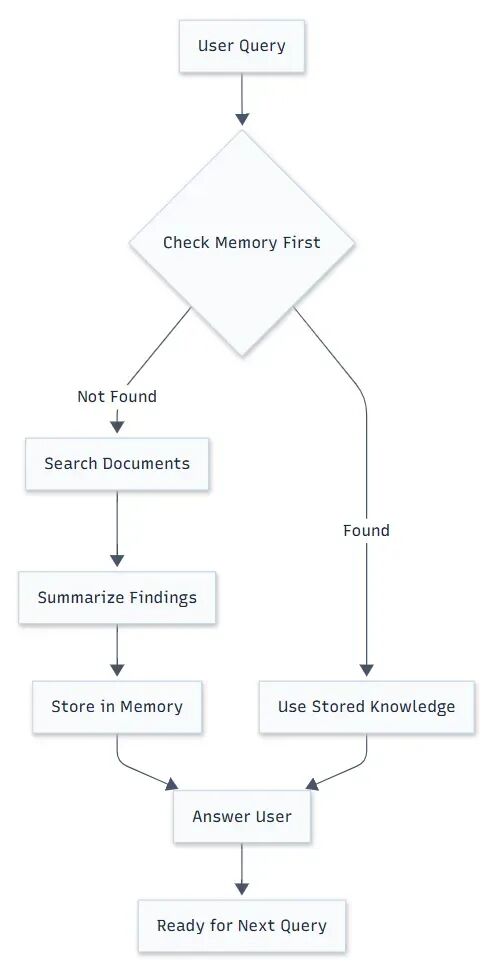
用人类的学习逻辑,理解记忆增强型RAG
其实,记忆增强型RAG的工作方式,和我们阅读研究论文、做笔记的过程高度相似:
当你读一篇几十页的学术论文时,不会逐字逐句记住所有内容,而是会提炼核心观点——比如研究方法、关键数据、结论与不足,然后把这些要点整理成几页笔记。后续需要引用这篇论文时,你只需翻看笔记,而不用重新读完整篇论文。
记忆增强型RAG就是这样运作的:
- 首次检索与总结:面对用户的第一个查询,AI会检索相关文档,生成回答后,自动将“文档核心信息+回答逻辑”压缩成简洁的总结(比如“产品A用户流失主因:价格敏感(35%)、功能迭代慢(28%),引用文档章节:用户反馈报告P12-15”),存入“数字笔记本”;
- 多轮互动与记忆更新:当用户提出后续问题(如“如何解决价格敏感问题”),AI会先调取“笔记本”里的流失原因总结,再针对性检索“定价策略”相关文档片段,生成回答后,把“解决方案要点+对应文档来源”补充到“笔记本”中;
- 长期记忆与复用:即便几小时后用户再问“之前提到的产品A流失解决方案,需要多少研发资源支持”,AI也能直接从“笔记本”里调取解决方案要点,无需重新检索流失原因和方案文档,大幅节省时间与令牌。
这种模式下,AI的“记忆”不再是一次性的上下文加载,而是可积累、可迭代的“知识库”,既能随着互动变得越来越“懂用户”,又能始终把上下文长度控制在合理范围,从根本上避免“令牌雪崩”。

三、构建你的第一个记忆感知代理(一步一步)
准备好构建一个真正能记住的 AI 了吗?我们来深入代码。我们将使用 OpenAI Agents SDK 创建一个文档问答代理,随着每次互动变得更聪明。
步骤 1:设置你的代理大脑
首先,建立基础——一个简单的知识库和记忆存储:
from agents import Agent, Runner, function_tool
# 你的文档(生产环境中,使用合适的 vector database)
documents = [
{
"title": "Apollo 11 Mission",
"content": "Apollo 11 was the first spaceflight to land humans on the Moon. It launched in 1969."
},
{
"title": "Neil Armstrong Bio",
"content": "Neil Armstrong was the first person to walk on the Moon, during the Apollo 11 mission."
}
]
# 你的代理的记忆笔记本
memory_store = []
步骤 2:创建记忆工具
现在来点魔法——我们给代理四个超能力:
@function_tool
def retrieve_docs(query: str) -> str:
"""Search documents for relevant information."""
for doc in documents:
if query.lower() in doc["content"].lower():
return f"From {doc['title']}: {doc['content']}"
return "No relevant document found."
@function_tool
def summarize_content(text: str) -> str:
"""Create a concise summary of the text."""
if len(text.split()) < 30:
return text
# In production, use an LLM call here
summary = text.split('.')[0] + '.'
return f"SUMMARY: {summary}"
@function_tool
def store_summary(info: str) -> str:
"""Save important information to long-term memory."""
memory_store.append(info)
return "Stored in memory."
@function_tool
def search_memory(query: str) -> str:
"""Search through stored memories."""
for entry in memory_store:
if query.lower() in entry.lower():
return entry
return ""
步骤 3:记忆优先策略
这里是我们教代理聪明使用记忆的地方:
memory_rag_agent = Agent(
name="SmartResearchAssistant",
model="gpt-4",
instructions="""
You are an AI research assistant with a perfect memory system.
Here's your workflow:
1. **Always check memory first** - Use search_memory() to see if you already
know the answer
2. **Retrieve new info only when needed** - If memory doesn't help, use
retrieve_docs()
3. **Summarize and store** - Use summarize_content() then store_summary()
for new findings
4. **Build your knowledge base** - Over time, you'll become an expert on
the topics
Remember: Your memory is your superpower. Use it wisely and never forget to update it with new knowledge!
""",
tools=[search_memory, retrieve_docs, summarize_content, store_summary]
)
四、观察你的代理实时学习
来看看实际运行。以下是你的记忆感知代理如何处理对话的:
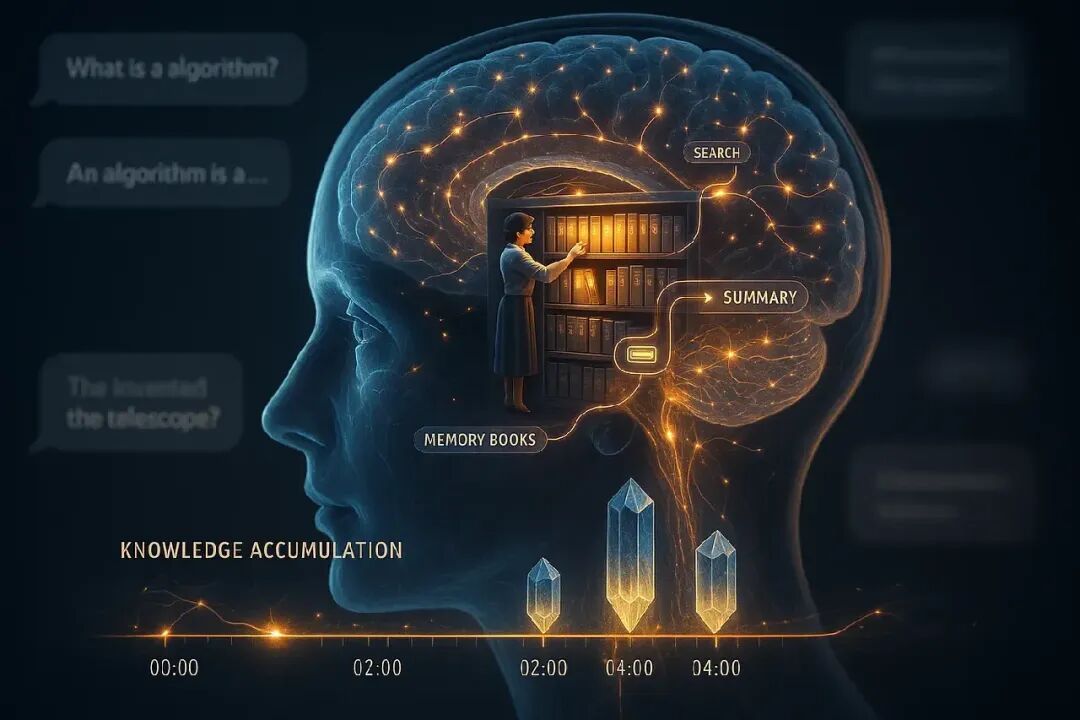
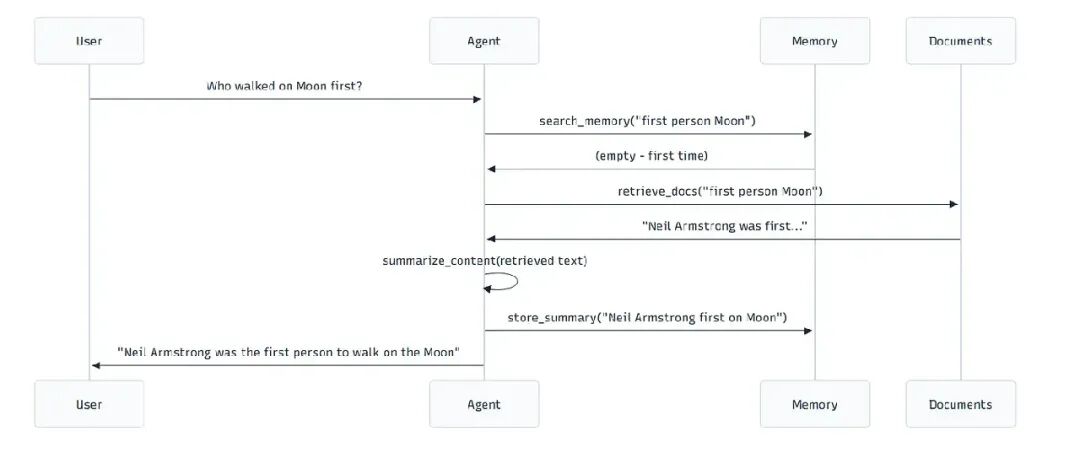
第一个问题:学习阶段
user_query1 = "Who was the first person to walk on the Moon?"
result1 = Runner.run_sync(memory_rag_agent, user_query1)
幕后发生什么:
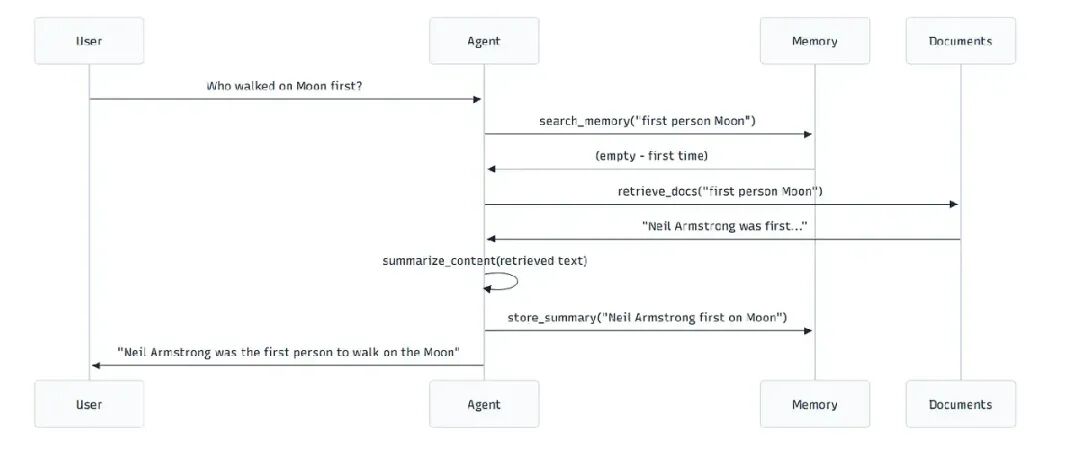
后续问题:记忆发挥作用
user_query2 = "What mission was that?"
result2 = Runner.run_sync(memory_rag_agent, user_query2)
现在看魔法:
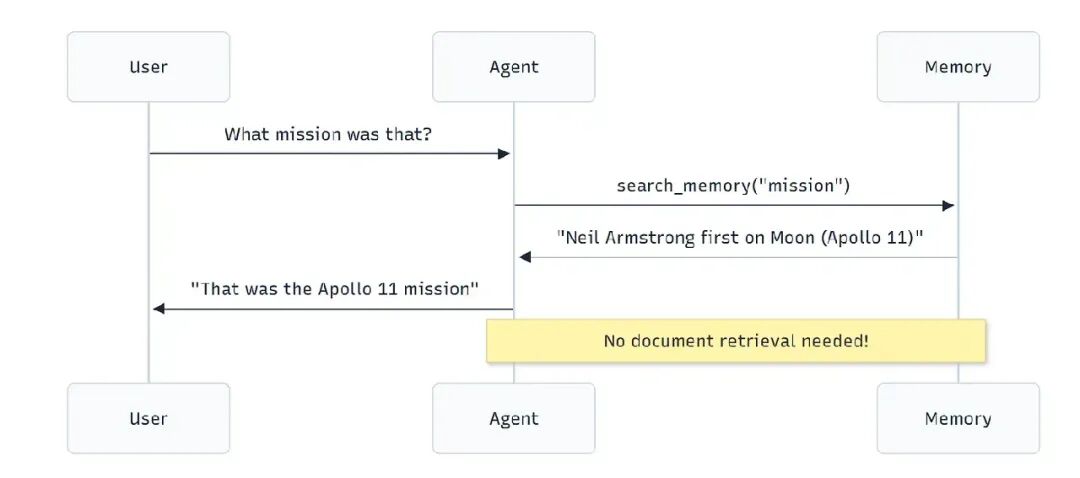
代理立即从记忆中回答——没有文档搜索,没有浪费令牌,没有延迟。
五、数字不会撒谎:为什么这很重要
让我展示你会看到的巨大改进:
令牌节省
传统 RAG:每个查询处理完整文档(每个 500+ 令牌)
记忆增强型:总结通常是 20–50 令牌
节省:随着时间推移,令牌使用减少 80–90%
速度改进
传统 RAG:文档搜索 + 检索 + 处理 = 2–5 秒
记忆增强型:记忆查找 = 200–500ms
结果:已知信息响应快 4–10 倍
成本分析
这里是一个真实场景:一周内关于同一文档集的 100 个查询。
传统 RAG:
- 100 查询 × 平均 2,000 令牌 = 200,000 令牌
- 成本:6.00 美元(按 0.03 美元/1K 令牌)
记忆增强型 RAG:
- 前 20 查询:每个 2,000 令牌 = 40,000 令牌
- 后 80 查询:每个 300 令牌(从记忆) = 24,000 令牌
- 总计:64,000 令牌
- 成本:1.92 美元
节省:4.08 美元(减少 68%)

六、高级记忆策略:超越基本存储
一旦你掌握了基本记忆增强型 RAG,这里有一些高级技巧,让你的代理更聪明:
分层记忆
想象成你的代理的文件系统:
memory_structure = {
"facts": [], # 快速事实查找
"procedures": [], # 一步一步的过程
"relationships": [], # 概念之间的连接
"summaries": [] # 高层概述
}
记忆过期
不是所有记忆都一样重要。实现智能遗忘:
@function_tool
def store_memory_with_priority(info: str, priority: str = "medium") -> str:
"""Store memory with importance level."""
timestamp = datetime.now()
memory_entry = {
"content": info,
"priority": priority,
"timestamp": timestamp,
"access_count": 0
}
memory_store.append(memory_entry)
return f"Stored {priority} priority memory."
语义记忆搜索
对于生产系统,使用 vector embeddings 进行记忆搜索:
@function_tool
def semantic_memory_search(query: str) -> str:
"""Find memories using semantic similarity."""
query_embedding = get_embedding(query)
best_match = None
best_score = 0
for memory in memory_store:
memory_embedding = memory.get("embedding")
if memory_embedding:
similarity = cosine_similarity(query_embedding, memory_embedding)
if similarity > best_score and similarity > 0.8:
best_score = similarity
best_match = memory["content"]
return best_match or ""
七、常见陷阱(以及如何避免)

“一切都重要”陷阱
问题:你的代理存储每个小细节,导致记忆膨胀。
解决方案:选择性存储。只存储可能再次引用的信息。
@function_tool
def should_store_memory(text: str, context: str) -> bool:
"""Decide if information is worth remembering."""
if len(text.split()) < 5: # 太短
return False
if "trivial" in context.lower(): # 明确标记为不重要
return False
return True
“陈旧记忆”问题
问题:代理记住过时信息。
解决方案:实现记忆刷新机制:
@function_tool
def refresh_memory(topic: str) -> str:
"""Update memories about a specific topic."""
# Remove old memories about topic
global memory_store
memory_store = [m for m in memory_store if topic.lower() not in m.lower()]
# Retrieve fresh information
fresh_info = retrieve_docs(topic)
if fresh_info:
summary = summarize_content(fresh_info)
store_summary(f"[UPDATED] {summary}")
return f"Refreshed memory about {topic}"
“记忆混乱”挑战
问题:无组织的记忆越来越难搜索。
解决方案:使用带标签的结构化记忆:
@function_tool
def store_tagged_memory(info: str, tags: list) -> str:
"""Store memory with searchable tags."""
memory_entry = {
"content": info,
"tags": tags,
"timestamp": datetime.now()
}
memory_store.append(memory_entry)
return f"Stored memory with tags: {', '.join(tags)}"
八、现实世界应用

客户支持代理
想象一个支持代理,能记住与客户几个月对话的每一次互动。不再有“能重复你的问题吗?”的时刻。
研究助手
完美用于学术研究,在几周的文档分析中积累知识。代理真正成为你研究领域的专家。
代码审查机器人
一个记住你的编码模式、之前 bug 和架构决定的代理。随着学习你的代码库,它给出越来越相关的建议。
个人知识管理者
你自己的 AI 助手,记住你讨论过的所有项目、目标和偏好。
九、AI 记忆的未来
我们只是触及表面。下一波记忆增强型代理将包括:
- 自传式记忆:代理记住自己的推理过程
- 情节式记忆:具体互动和上下文的详细记录
- 程序式记忆:学习和记住如何执行复杂任务
- 协作式记忆:多个代理间的共享知识库
你的下一步:构建生产就绪的记忆系统
准备好在生产环境中实现这个?这里是你的路线图:
阶段 1:基本实现(第 1–2 周)
- 设置记忆存储(从简单内存开始,然后移到 Redis/database)
- 实现四个核心工具(搜索、检索、总结、存储)
- 创建记忆优先的提示指令
- 用小文档集测试
阶段 2:增强记忆(第 3–4 周)
- 添加 vector embeddings 用于语义记忆搜索
- 实现记忆优先级和过期
- 创建记忆分析和监控
- 添加记忆刷新机制
阶段 3:高级功能(第 5–8 周)
- 多层记忆架构
- 代理实例间的记忆共享
- 自动化记忆组织
- 性能优化和扩展
入门工具和资源
必需库
- OpenAI Agents SDK:用于代理框架
- LangChain:备选代理框架,带记忆组件
- ChromaDB/Pinecone:用于语义记忆的 vector databases
- Redis:快速内存存储,用于频繁访问
监控和分析
LangSmith:跟踪记忆使用和代理性能
Weights & Biases:监控记忆效率指标
自定义仪表板:跟踪记忆命中率和令牌节省
记忆革命现在开始
记忆增强型 RAG 不只是技术改进——它是向真正学习和成长的 AI 的根本转变。我们不是在构建无状态的问答机器人,而是创建随着每次互动变得更聪明的数字同事。
好处很明显:巨大令牌节省、更快响应、更一致答案,以及代理随着时间真正理解上下文。
但真正刺激的是——这只是开始。随着我们添加更复杂的记忆系统,我们正走向不只是处理信息,而是积累智慧的 AI。
轮到你了:你会用能记住的代理构建什么?
如何从零学会大模型?小白&程序员都能跟上的入门到进阶指南
当AI开始重构各行各业,你或许听过“岗位会被取代”的焦虑,但更关键的真相是:技术迭代中,“效率差”才是竞争力的核心——新岗位的生产效率远高于被替代岗位,整个社会的机会其实在增加。
但对个人而言,只有一句话算数:
“先掌握大模型的人,永远比后掌握的人,多一次职业跃迁的机会。”
回顾计算机、互联网、移动互联网的浪潮,每一次技术革命的初期,率先拥抱新技术的人,都提前拿到了“职场快车道”的门票。我在一线科技企业深耕12年,见过太多这样的案例:3年前主动学大模型的同事,如今要么成为团队技术负责人,要么薪资翻了2-3倍。
深知大模型学习中,“没人带、没方向、缺资源”是最大的拦路虎,我们联合行业专家整理出这套 《AI大模型突围资料包》,不管你是零基础小白,还是想转型的程序员,都能靠它少走90%的弯路:
- ✅ 小白友好的「从零到一学习路径图」(避开晦涩理论,先学能用的技能)
- ✅ 程序员必备的「大模型调优实战手册」(附医疗/金融大厂真实项目案例)
- ✅ 百度/阿里专家闭门录播课(拆解一线企业如何落地大模型)
- ✅ 2025最新大模型行业报告(看清各行业机会,避免盲目跟风)
- ✅ 大厂大模型面试真题(含答案解析,针对性准备offer)
- ✅ 2025大模型岗位需求图谱(明确不同岗位需要掌握的技能点)
所有资料已整理成包,想领《AI大模型入门+进阶学习资源包》的朋友,直接扫下方二维码获取~

① 全套AI大模型应用开发视频教程:从“听懂”到“会用”
不用啃复杂公式,直接学能落地的技术——不管你是想做AI应用,还是调优模型,这套视频都能覆盖:
- 小白入门:提示工程(让AI精准输出你要的结果)、RAG检索增强(解决AI“失忆”问题)
- 程序员进阶:LangChain框架实战(快速搭建AI应用)、Agent智能体开发(让AI自主完成复杂任务)
- 工程落地:模型微调与部署(把模型用到实际业务中)、DeepSeek模型实战(热门开源模型实操)
每个技术点都配“案例+代码演示”,跟着做就能上手!

课程精彩瞬间

② 大模型系统化学习路线:避免“学了就忘、越学越乱”
很多人学大模型走弯路,不是因为不努力,而是方向错了——比如小白一上来就啃深度学习理论,程序员跳过基础直接学微调,最后都卡在“用不起来”。
我们整理的这份「学习路线图」,按“基础→进阶→实战”分3个阶段,每个阶段都明确:
- 该学什么(比如基础阶段先学“AI基础概念+工具使用”)
- 不用学什么(比如小白初期不用深入研究Transformer底层数学原理)
- 学多久、用什么资料(精准匹配学习时间,避免拖延)
跟着路线走,零基础3个月能入门,有基础1个月能上手做项目!

③ 大模型学习书籍&文档:打好理论基础,走得更稳
想长期在大模型领域发展,理论基础不能少——但不用盲目买一堆书,我们精选了「小白能看懂、程序员能查漏」的核心资料:
- 入门书籍:《大模型实战指南》《AI提示工程入门》(用通俗语言讲清核心概念)
- 进阶文档:大模型调优技术白皮书、LangChain官方中文教程(附重点标注,节省阅读时间)
- 权威资料:斯坦福CS224N大模型课程笔记(整理成中文,避免语言障碍)
所有资料都是电子版,手机、电脑随时看,还能直接搜索重点!

④ AI大模型最新行业报告:看清机会,再动手
学技术的核心是“用对地方”——2025年哪些行业需要大模型人才?哪些应用场景最有前景?这份报告帮你理清:
- 行业趋势:医疗(AI辅助诊断)、金融(智能风控)、教育(个性化学习)等10大行业的大模型落地案例
- 岗位需求:大模型开发工程师、AI产品经理、提示工程师的职责差异与技能要求
- 风险提示:哪些领域目前落地难度大,避免浪费时间
不管你是想转行,还是想在现有岗位加技能,这份报告都能帮你精准定位!
⑤ 大模型大厂面试真题:针对性准备,拿offer更稳
学会技术后,如何把技能“变现”成offer?这份真题帮你避开面试坑:
- 基础题:“大模型的上下文窗口是什么?”“RAG的核心原理是什么?”(附标准答案框架)
- 实操题:“如何优化大模型的推理速度?”“用LangChain搭建一个多轮对话系统的步骤?”(含代码示例)
- 场景题:“如果大模型输出错误信息,该怎么解决?”(教你从技术+业务角度回答)
覆盖百度、阿里、腾讯、字节等大厂的最新面试题,帮你提前准备,面试时不慌!

以上资料如何领取?
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

为什么现在必须学大模型?不是焦虑,是事实
最近英特尔、微软等企业宣布裁员,但大模型相关岗位却在疯狂扩招:
- 大厂招聘:百度、阿里的大模型开发岗,3-5年经验薪资能到50K×20薪,比传统开发岗高40%;
- 中小公司:甚至很多传统企业(比如制造业、医疗公司)都在招“会用大模型的人”,要求不高但薪资可观;
- 门槛变化:不出1年,“有大模型项目经验”会成为很多技术岗、产品岗的简历门槛,现在学就是抢占先机。
风口不会等任何人——与其担心“被淘汰”,不如主动学技术,把“焦虑”变成“竞争力”!

最后:全套资料再领一次,别错过这次机会
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 600
600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









