



把之前的deepseek +本地知识库的部署内容做了一版,
增加内容:
1, ollama 安装
2,cherry studio在线模型配置
3,anythingLLM的在线以及文本分割配置
先画个数据流程流程。

Ollama安装(非必须)
14B及以上有推理能力,32b比较实用。显卡最低12GB。内存最好32GB.
相关的软件,我已经放入到网盘,网不好的同学,可以直接下载。
下载链接:https://pan.quark.cn/s/b69829720b68
电脑配置低:可以参考
下载ollama
https://ollama.com/download/
默认为当前电脑的对应的版本,直接下载即可。下载以后,一路点点点即可。
环境变量设置
安装完以后先不要使用,先设置下环境变量。默认模型下载到C盘。一个模型最小也得几个GB.
通过 我的电脑->右键-> 属性-> 高级系统设置-> 环境变量->新建用户变量即可。

OLLAMA_HOST: 0.0.0.0
OLLAMA_MODELS:E:\ai\ollama\models
OLLAMA_HOST:设置为0.0.0.0 会将ollama服务暴露到所有的网络,默认ollama只绑定到了127.0.0.1,只能通过localhost或127.0.0.1访问。
OLLAMA_MODELS:设置了模型的存放的地址。
https://ollama.com/library/deepseek-r1
安装DeepSeek模型(可选)
打开:https://ollama.com/library/deepseek-r1
选择适合自己的模型,12GB~16GB显存建议最大选择14B,24GB显存建议32B.
安装语言模型
# 下载模型
ollama pull deepseek-r1:14b
# 下载或运行模型,正常ollama不会运行模型的
ollama run deepseek-r1:14b
安装向量模型
基于本地的deepseek搭建个人知识库。使用本地服务,安装嵌入模型,用于将文本数据转换为向量标识的模型。
# 命令行窗口执行拉取下即可。
ollama pull bge-m3
基于Cherry Studio搭建(首选)
cherry Studio 文本分割不能选择文本长度和重叠度。
下载cherry studio
根据自己的环境下载cherry studio

安装的时候,注意安装到其他磁盘,不要在c盘安装。
本地模型知识库
配置本地ollama


操作步骤:
- 找到左下角设置图标
- 选择模型服务
- 选择ollama
- 点击管理
- 点击模型后面的加号(会自动查找到本地安装的模型)
- 减号表示已经选择了
配置在线模型:

1,在模型服务里,选择对应的模型服务商,比如硅基流动
2,注意开关
3,填写自己的密钥

1,选择嵌入模型
2,选择要添加的模型
知识库配置

- 选择知识库
- 选择添加
- 选择嵌入模型,这个时候有在线和本地的
- 填写知识库名称
添加知识文档
cherry可以添加文档,也可以添加目录(这个极其方便),添加完以后出现绿色的对号,表示向量化完成。

搜索验证

- 点击搜索知识库
- 输入搜索顺序
- 点击搜索 大家可以看下我搜索的内容和并没有完全匹配,不过已经和意境关联上了。
大模型处理

-
点击左上角的聊天图标
-
点击助手
-
点击默认助手(你也可以添加助手)
-
选择大模型
-
选择本地deepseek,也可以选择自己已经开通的在线服务
-
设置知识库(不设置不会参考)
-
输入提问内容
-
发问

大家可以看到deepseek已经把结果整理了,并告诉了我们参考了哪些资料。
满血版
差别就是大模型的选择,在模型服务里配置下在线的deepseek服务即可。
如果你的知识库有隐私数据,不要联网!不要联网!不要联网!
方案二 基于AnythingLLM搭建
下载AnythingLLM Desktop

下载以后,安装的时候,注意安装到其他磁盘,不要在c盘安装。
AnythingLLM 配置

点击左下角的设置
Ollama配置

\1. 点击 LLM首选项
\2. 选择ollama作为模型提供商
\3. 选择已安装的deepsek 模型
\4. 注意下地址,如果本地就127.0.0.1
\5. 保存
腾讯云配置(推荐,目前最稳定的)

1,选择openAi通用接口
2,配置腾讯云的大模型BASE地址 : https://api.lkeap.cloud.tencent.com/v1
3,配置获取到的APIKEY
4,输入模型:deepseek-r1
5, 设置Token context window 模型单次能够处理的最大长度(输入+输出),如果你的使用知识库建议放大,想多关联上下文也调大;
6,max tokens 模型最大生成token
apiKey申请地址
https://console.cloud.tencent.com/lkeap/api
接口地址
https://cloud.tencent.com/document/product/1772/115969
ollama show deepseek-r1:14b
Model
architecture qwen2
parameters 14.8B
context length 131072
embedding length 5120
quantization Q4_K_M
14b的最大长度是131072,ollama 默认是不用设置的。
向量库模型配置

切换使用本地ollama,也可以自带的。
1,选择ollama
2,选择对应的向量模型
3,设置分段最大长度
4,注意下url
文本分割配置

1,设置文本块大小,根据自己的文本输入。
2,设置文本块重叠(建议重叠10%~25%)
配置工作区


- 在1里点击New Thread 新建一个聊天框
- 默认会话
- 上传知识库文档

将文档拖拽到上传框。ps: 只需要拖拽一次就行了,它在聊天框能看到。不知道为什么,我这拖拽以后,没看到上传成功,然后又拖拽了几次。然后聊天框就好多份。
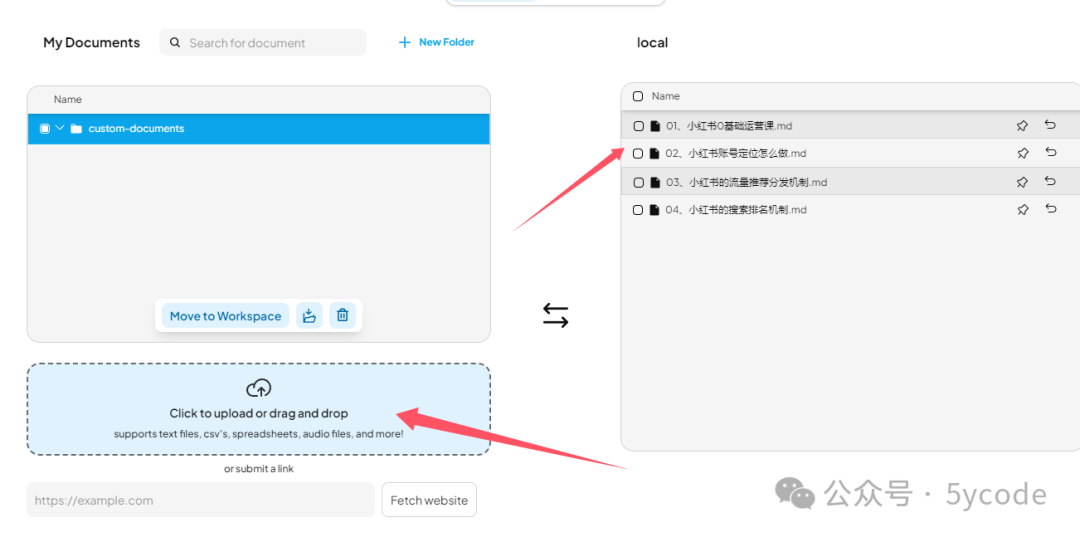

当然你可以配置远程文档,confluence、github都可以。

ps: 需要注意的是文档在工作区间内是共用的。
api功能
AnythingLLM 可以提供api访问的功能,这个可以作为公共知识库使用。

总结
整个操作下来,AnythingLLM 的体验没有cherry好。AnythingLLM就像一个包壳的web应用(后来查了下,确实是)。AnythingLLM 得具备一定的程序思维,给技术人员用的。非技术人员还是使用cherry吧。作为喜欢折腾的开发人员,我们可以结合dify使用。
最后
个人知识库+本地大模型的优点
- 隐私性很好,不用担心自己的资料外泄、离线可用
- 在工作和学习过程中对自己整理的文档,能快速找到,并自动关联
- 在代码开发上,能参考你的开发习惯,快速生成代码
DeepSeek无疑是2025开年AI圈的一匹黑马,在一众AI大模型中,DeepSeek以低价高性能的优势脱颖而出。DeepSeek的上线实现了AI界的又一大突破,各大科技巨头都火速出手,争先抢占DeepSeek大模型的流量风口。
DeepSeek的爆火,远不止于此。它是一场属于每个人的科技革命,一次打破界限的机会,一次让普通人也能逆袭契机。
DeepSeek的优点

掌握DeepSeek对于转行大模型领域的人来说是一个很大的优势,目前懂得大模型技术方面的人才很稀缺,而DeepSeek就是一个突破口。现在越来越多的人才都想往大模型方向转行,对于想要转行创业,提升自我的人来说是一个不可多得的机会。
那么应该如何学习大模型
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
大模型岗位需求越来越大,但是相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把都打包整理好,希望能够真正帮助到大家。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【
保证100%免费】
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 2051
2051

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









