




情绪识别在各种对话场景中具有广泛的应用价值。例如,在社交媒体中,可以通过对评论进行情感分析来了解用户的情绪态度;在人工客服中,可以对客户的情绪进行分析,以更好地满足其需求。
此外,情绪识别还可以应用于聊天机器人,通过实时分析用户的情绪状态,生成基于用户情感的回复,从而提供更加个性化的交互体验。对话情感识别(Emotion Recognition in Conversation)是一个分类任务,旨在识别出一段对话序列里面每句话的情感标签。
图1给出了一个简单的示例.对话中的话语情绪识别并不简单等同于单个句子的情绪识别,需要综合考虑对话中的背景、上下文、说话人等信息。
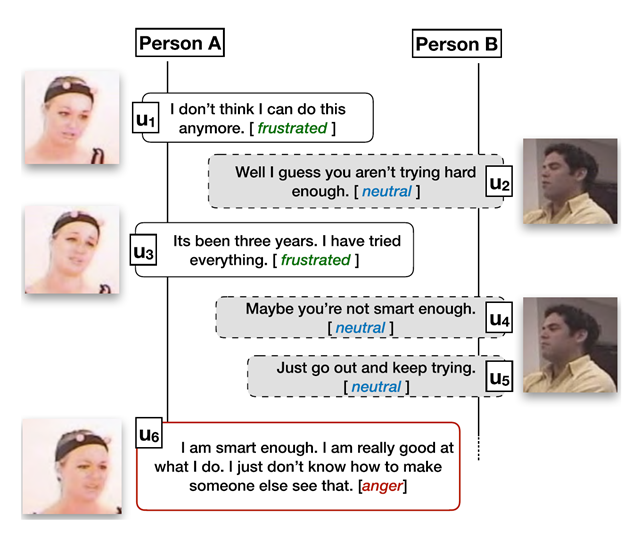 图1.对话情绪识别示例
图1.对话情绪识别示例
长期以来,由于ERC任务强依赖于上下文的理解,基于Roberta的方法即便是在2023年也有接近SOTA的性能,基于Prompt的模型微调方法虽然有但不是主流,在测试集上表现总不如传统方法粗暴有用.所以对话情感识别任务领域一直呈现单句话语特征微调和人物交互细致建模两方面的割裂发展。单句话语特征微调致力于在Glove和RoBERTa的模型上微调并抽取出单句的话语特征,而人物交互细致建模则更加注重于如何去设计话语间,人物间的相互影响来实现精准的情绪识别。
ChatGPT问世以后,几乎所有的NLP任务都在往LLM范式迁移,但ERC任务始终没有进展,一方面研究者们并没有找到好的Instruction框架来激发模型的能力,另外一方面一些用LLM做ERC的浅尝辄止尝试而得到的较差的结果让人们普遍觉得用十亿级别的语言模型来得到一个比小模型差的多的结果实在是大炮打蚊子——小题大作。

表1: ChatGPT在ERC任务的性能测试
而我们近期的研究则较好地解决了上述两个问题,并且在三个经典榜单上都取得了较大的提升,今天有幸与大家分享我们的方案以及思考。

Paper: https://arxiv.org/abs/2309.11911
Code: https://github.com/LIN-SHANG/InstructERC
InstructERC:以生成式视角重构ERC任务
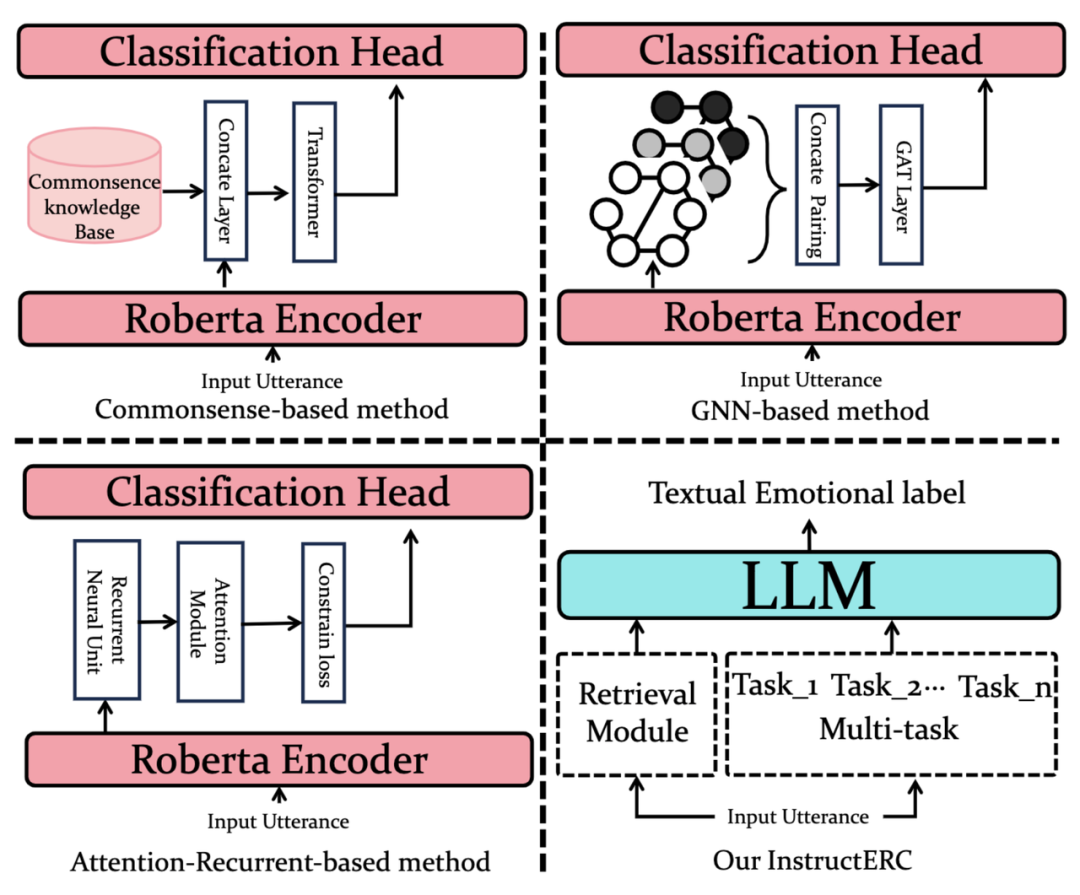 图2: ERC模型范式变迁
图2: ERC模型范式变迁
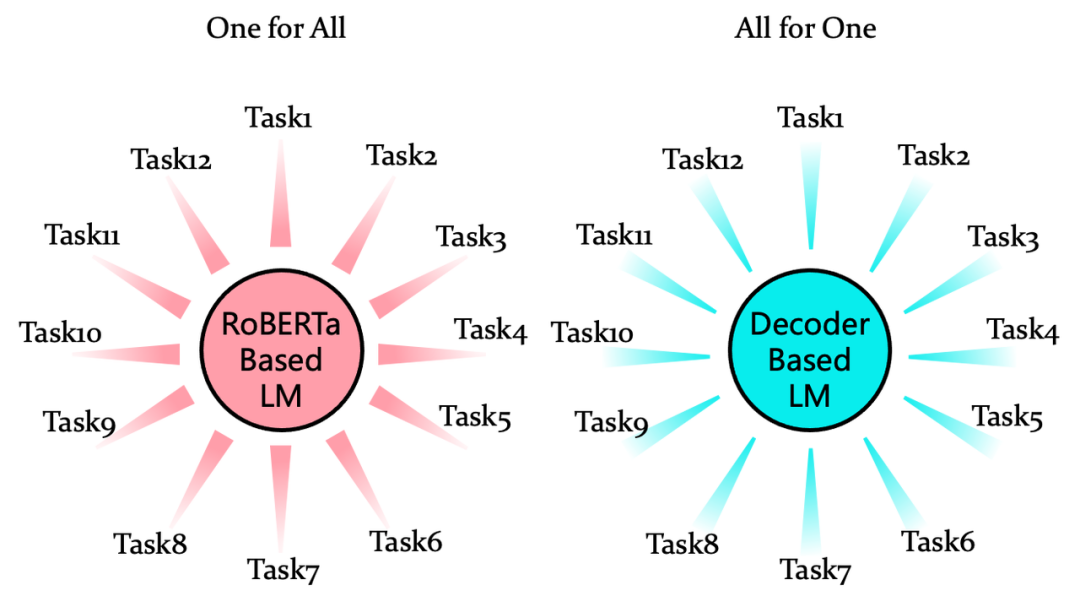 图3: RoBERTa-base和Decoder-base支持下游任务的区别
图3: RoBERTa-base和Decoder-base支持下游任务的区别
由于预训练方式从Encoder到Decoder的变迁,以Prompt-tuning为代表的技术核心思想为改造下游任务形式,使之符合语言模型的训练范式以便更好的激发语言模型在下游任务上的表现能力,很多NLP任务都被统一为了Seq2Seq的结构,以生成式的方式来解决。
不破不立,对于ERC这种传统判别式任务,InstructERC率先用纯生成式的框架来重构ERC任务,具体结构如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 774
774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









