




一、下载Ollama模型
首先,我们需要下载一个叫做 Ollama 的模型,它是DeepSeek运行的基础。你可以通过以下两种方式下载:
-
官网下载:访问 Ollama官网 下载(如果你无法访问,可能需要科学上网)。
-
云盘下载:如果官网访问不便,别担心,你可以通过这个云盘链接下载安装包:
点击下载提取码:8888

二、安装Ollama模型
下载好后,你会得到一个安装包,接下来就是安装啦!
-
双击打开安装包,然后点击“Install”进行安装。
 img
img -
默认情况下,Ollama会安装到C盘,耐心等待安装完成。
 img
img
安装完毕后,打开Ollama的浏览器页面(别忘了开启梯子),然后点击 DeepSeek-R1,就能开始下一步操作了!


三、选择适合你电脑的模型
这一部是关键!选择合适的模型非常重要。模型参数越大,AI反应速度越快,但对显卡显存的要求也越高。
如果不确定显卡显存,建议用鲁大师等软件检查一下。
以下是不同模型对显卡显存的需求:
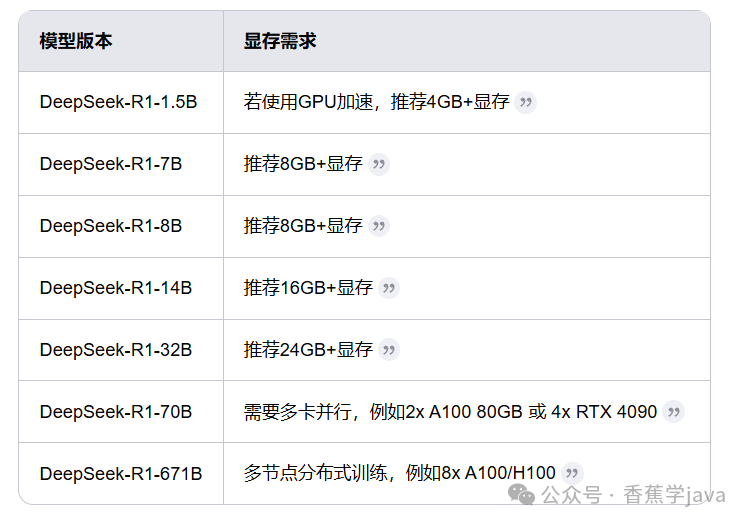
根据显卡显存选择一个合适的模型哦!
四、安装模型
假设你的电脑有8GB显存,那么可以选择 7b 模型。
-
在网页中找到 7b 模型,点击选择,然后复制页面上显示的指令。
 img
img -
按下
Win + R键,打开命令窗口,粘贴刚才复制的指令,然后按回车运行。
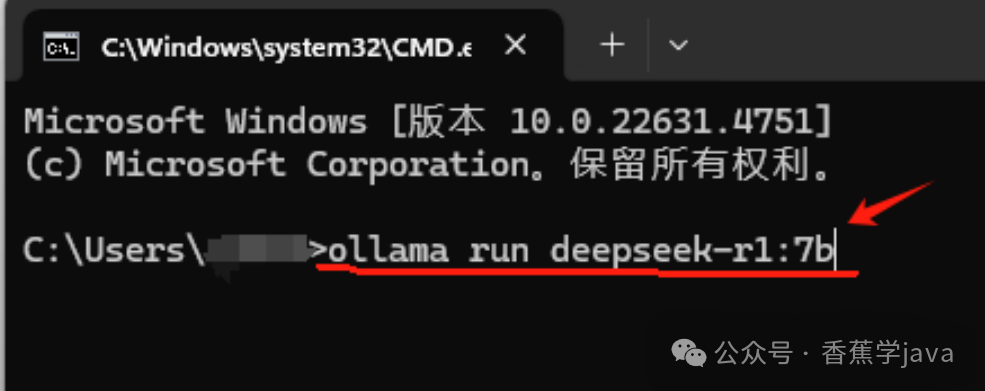
注意:安装过程中,可能会看到进度条卡住(比如99%)。别着急!只要断开网络(拔掉网线或关闭WiFi),再重新连接,就能顺利完成安装了。 友情提示:如果下载太慢,可以尝试使用游戏加速器,找到DeepSeek加速,开启加速后重新下载即可


五、安装ChatBox,让AI对话更有趣
模型安装完成后,我们还需要安装一个叫 ChatBox 的工具,用来与AI进行对话。
-
访问 ChatBox官网 下载并安装。
-
如果你不方便访问官网,也可以通过网盘链接下载:点击下载提取码:8888
 img
img -
安装完成后,启动ChatBox,进入应用界面。选择 “使用自己的API Key或本地模型”。
 img
img -
选择 “使用Ollama API”,进入设置界面,选择刚才安装好的 7b 模型。


-
根据需要设置回复字数限制以及AI的想象力等参数。
 img
img
六、设置AI身份角色,让对话更有个性
为了让AI对话更有趣,你可以给它设定个性化的身份角色。例如,让它扮演一个幽默的助手,或者一个严肃的专家。这样,你的对话就更有趣啦!
-
设置好AI角色后,点击保存,就能开始和AI聊天啦!


七、自由发挥,享受AI的乐趣
到此,DeepSeek的本地部署就完成了!你可以开始和AI对话啦,看看它的表现。如果觉得某个模型太卡,或者想尝试其他模型,删除当前模型并重新安装新模型也非常简单。
删除命令:
ollama rm deepseek-r1:7b
然后重新下载其他版本的模型就好了!
八、总结
跟着这个教程一步步来,你就能顺利在Windows上完成DeepSeek的本地部署。快去试试吧,享受与AI聊天的乐趣!😊
DeepSeek无疑是2025开年AI圈的一匹黑马,在一众AI大模型中,DeepSeek以低价高性能的优势脱颖而出。DeepSeek的上线实现了AI界的又一大突破,各大科技巨头都火速出手,争先抢占DeepSeek大模型的流量风口。
DeepSeek的爆火,远不止于此。它是一场属于每个人的科技革命,一次打破界限的机会,一次让普通人也能逆袭契机。
DeepSeek的优点

掌握DeepSeek对于转行大模型领域的人来说是一个很大的优势,目前懂得大模型技术方面的人才很稀缺,而DeepSeek就是一个突破口。现在越来越多的人才都想往大模型方向转行,对于想要转行创业,提升自我的人来说是一个不可多得的机会。
那么应该如何学习大模型
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
大模型岗位需求越来越大,但是相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把都打包整理好,希望能够真正帮助到大家。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【
保证100%免费】
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 1260
1260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









