 Perceiver-Prompt改善构音障碍语音识别
Perceiver-Prompt改善构音障碍语音识别




为促进最新研究成果的传播与交流,CCF语音对话与听觉专委在专委会微信公众号启动论文导读栏目,定期分享最新语音、对话与听觉相关研究方向论文。本期分享一篇发表在INTERSPEECH2024上的构音障碍语音识别方面的文章。本导读论文栏目持续征稿中,欢迎踊跃投稿,投稿方式请参见文末指南。
【论文标题】Perceiver-Prompt: Flexible Speaker Adaptation in Whisper for Chinese Disordered Speech Recognition
【论文作者】江怡聪1,王天资2,谢旭荣1,刘娟3,孙伟1,燕楠3,陈辉1,王岚3,刘循英2,田丰1
【论文单位】1中国科学院软件研究所,2香港中文大学,3中国科学院深圳先进技术研究院
【作者邮箱】jiangyicong231@mails.ucas.ac.cn; twang@se.cuhk.edu.hk; xurong@iscas.ac.cn
【论文亮点】
本文提出了一种基于P-tuning的说话人自适应方法——Perceiver-Prompt,用于Whisper模型的构建,以完成构音障碍语音识别任务。通过采用不同的配置和训练方法,这种方法能够生成具有说话人自适应能力的Prompt,从而应对不同程度的构音障碍以及不同的语音任务。在我们构建的中文构音障碍语音数据集上,利用Perceiver-Prompt微调后的Whisper,相较于Conformer、TDNN以及使用/不使用i-vector进行微调的Whisper,在所有配置下最高降低了13.04%的相对字符错误率。并且据我们所知,这是首次将P-tuning应用于大规模语音模型Whisper的说话人自适应方法。
【引言】
言语障碍语音识别对于改善患有例如构音障碍等疾病个体的生活质量具有深远的影响。构音障碍语音识别面临着诸多挑战,包括数据有限、构音障碍和非构音障碍说话者之间存在实质差异、以及由于疾病导致的说话者之间的差异显著。本文提出了Perceiver-Prompt,这是一种利用P-Tuning在大规模语音模型Whisper上进行说话人自适应的方法。我们首先使用LoRA对Whisper进行微调,然后集成一个基于可训练Perceiver的Prompt编码器,从可变长度的输入中生成固定长度的说话人Prompt,以提高模型对中文构音障碍语音的识别能力。在我们自行构建的中文构音障碍语音数据集上的实验结果显示,Perceiver-Prompt能够持续改善识别性能,相较于微调后的Whisper,字符错误率(CER)能够相对减少高达13.04%。
【研究背景】
尽管语音识别技术已经取得了显著进展,但对障碍语音识别技术的研究仍然至关重要,因为这对于改善患有构音障碍等疾病个体的生活质量具有深远意义。构音障碍是一种由神经损伤引起的神经-运动障碍,影响了言语产生过程中需要的肌肉。患者通常表现为发音不清、语速变化不定以及言语节奏紊乱。此外,由于构音障碍患者自身的残疾或行动不便,很难进行大规模的数据采集。这些因素共同导致了:(1)训练数据不足;(2)构音障碍患者与非患者之间存在显著差异;(3)由于疾病的影响,不同说话者之间也存在较大变异。
为应对这些挑战,许多研究选择使用构音障碍患者的数据来训练专门的自动语音识别模型。时频深度特征、LHUC、i-vector等方法都通过适应构音障碍患者的语音特性来实现构音障碍语音识别的性能提升。
Whisper[1]、HuBERT[2]、Wav2Vec 2.0[3]等模型利用大规模数据进行预训练,从正常语音数据中学习通用语音表征,一定程度上弥补了构音障碍语音数据的不足。微调这些预训练模型已成为一种趋势。然而,在大规模预训练模型(如Whisper)上的说话人自适应仍是一个相对未被深入研究的领域。
为了填补这部分的空白,我们提出了Perceiver-Prompt。据我们所知,这是第一个在大规模语音模型 Whisper上应用P-Tuning进行说话人自适应的工作。其灵活性在我们自行构建的构音障碍语音数据集上得到了验证,在各种配置和训练任务下均展现了优秀的性能。
【研究方法】
一、基线方法
1.大规模预训练模型Whisper与微调方法LoRA
Whisper是一种大规模预训练语音模型,基于68万小时多语言、多任务的监督数据训练而成,采用端到端的Transformer编码器-解码器结构。
LoRA是一种大模型微调方法,旨在利用低秩矩阵编码模型微调参数,不显著增加推理时间且更易于优化。
尽管Whisper在多场景中表现出色,其在处理构音障碍语音数据时仍性能不足。因此我们使用LoRA在自行构建的中文构音障碍数据集上对Whisper进行微调,以提升Whisper在构音障碍语音识别任务中的适应性。
2. P-tuning
将离散或连续的Prompt作为额外输入集成到模型中可提升性能,P-tuning引入了独立的Prompt编码器用于生成连续的Prompt嵌入作为额外输入,从而取得更优效果。
我们利用P-tuning来实现说话人自适应,将说话人信息与构音障碍特征编码为Prompt输入模型,帮助模型更好地适应任务。
二、Perceiver-Prompt
1.使用Perceiver作为Prompt****编码器
要在构音障碍语音识别任务中实现基于P-Tuning的说话人自适应,需要为Whisper增加Prompt编码器,以处理复杂的时间序列语音数据,向量化说话人特征生成Prompt。Perceiver是这一任务的理想选择,其优势在于无需特定领域假设即可生成Prompt,并能处理任意形式的输入。Perceiver生成的固定长度嵌入向量可在输入数据的两端进行拼接,并且能够通过改变自身的相关参数实现不同场景下的障碍语音识别。此外,Perceiver还能在线生成说话人Prompt,实现推理阶段的高效自适应。Perceiver如图1左侧绿色部分所示。
2.基于Perceiver-Prompt****的说话人自适应
我们所提出的Perceiver-Prompt方法利用P-Tuning来进行灵活的配置,进而实现说话人自适应。总的来说,包含说话人信息的Prompt是通过Perceiver生成并且经过线性变换后得到的。
Perceiver的输入是来自同一说话人的若干历史语句经过Whisper后得到的词嵌入向量,而线性变换则用来讲说话人Prompt映射到与输入语音对应的词嵌入向量相同的特征空间中,随后将其按照不同的位置(如输入语音的首端、末端或者两端)与输入词嵌入向量拼接,形成新的词嵌入序列以实现说话人自适应,如图1右侧蓝色部分所示。
具体来说,以拼接在输入的末端为例,处理过程如下所示:
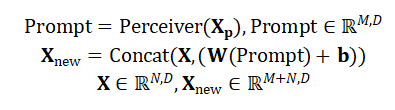
其中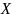 表示长度为
表示长度为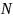 维度为
维度为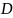 的嵌入序列,
的嵌入序列,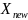 表示新的长度为
表示新的长度为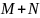 维度为的嵌入序列,而
维度为的嵌入序列,而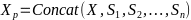 ,其中
,其中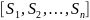 表示来自同一说话人的历史语句。在推理阶段,Perceiver-Prompt通过输入目标说话人的历史语句生成Prompt,用于实现基于Whisper的说话人自适应。
表示来自同一说话人的历史语句。在推理阶段,Perceiver-Prompt通过输入目标说话人的历史语句生成Prompt,用于实现基于Whisper的说话人自适应。
在实际的使用过程中,Perceiver可以被放置在Whisper的梅尔对数频谱特征层或者Whisper的Encoder之前。更重要的是,Perceiver-Prompt还可以利用说话人识别或者障碍严重程度分类与回归等辅助信息进行监督训练,帮助模型在不同的情况下获得更好的障碍语音识别性能。
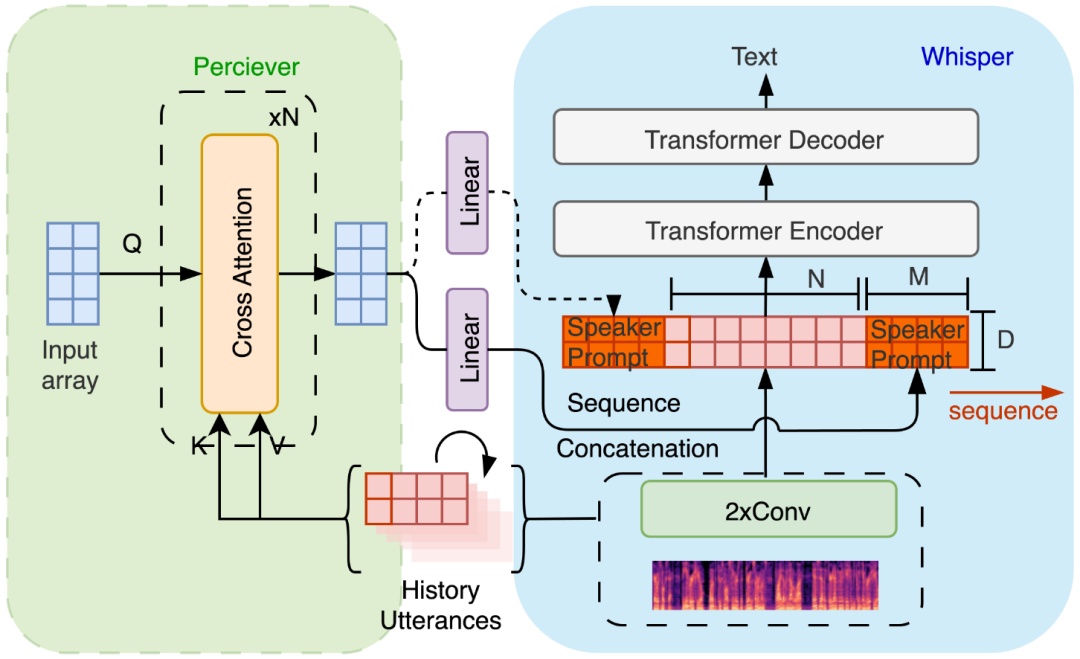
图1 Perceiver-Prompt的框架图与灵活的Prompt拼接方式,包括可选择性添加的来自相同说话人的语音数据
三、实验结果与分析
1.实验设置
数据集: 我们按照[4]中的方法构建了构音障碍语音数据集,包含从64名不同程度构音障碍患者(约31小时)和20名健康参与者(约18小时)收集的中文语音数据。收集任务包括汉字、单词和句子的阅读任务,任务要求参与者完成相关阅读任务并录制语音。
此外,我们还收集了患者的Frenchay构音障碍评估(FDA)量表信息,根据分数{135, 90, 70}/145将其分为四个严重程度级别。训练集包含53名患有不同程度构音障碍的患者和20名健康参与者的语音数据,而其余11名患者用作测试。在后续实验中,我们将评估模型在不同FDA严重成都和各种语音任务下的性能,其中F.1代表构音障碍的最高严重程度,而F.4则代表最不严重的程度。另外,T.1表示字识别任务,T.2表示词识别任务,T.3表示句子识别任务。
Whisper: 我们选择Whisper-medium作为实验基础,其在性能与计算资源之间达成了良好平衡。ESPnet [5]提供的配方为使用LoRA微调Whisper-medium提供了相应的设置,编码器和解码器均由24个残差注意力块堆叠而成,每个块包含多头注意力和前馈网络。LoRA的微调目标为注意力模块中的“query”、“key”、“value”和“att.out”等组件,LoRA的秩设置为8。在Whisper中,所有音频都重采样为16,000 Hz,并使用80通道对数幅度梅尔频谱表示,计算时采用25毫秒的窗口和10毫秒的步长。
2.实验结果与分析
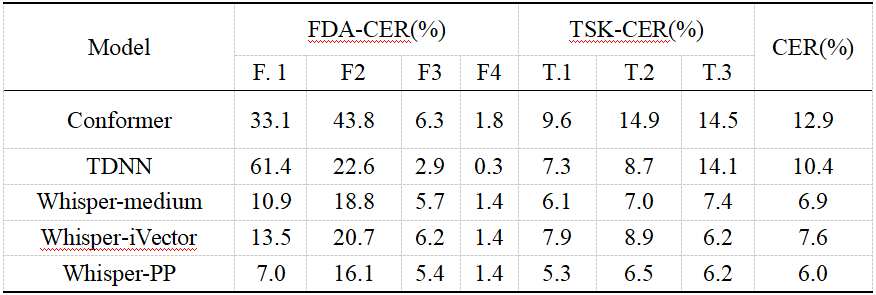
尽管Whisper在一个相当大的数据集上进行了预训练,并且在大多数任务中能够直接表现出优秀的性能,但它并不能直接用于构音障碍语音识别。我们直接对未经过微调的Whisper-medium和Whisper-large进行了推理,分别获得了141.9%和87.9%的字符错误率(CER)。推理结果显示,CER如此之高是因为对构音障碍语音数据集预测句子结束的困难。因此,后续使用的所有Whisper系统均使用LoRA微调了构音障碍语音数据。我们还采用了最先进的端到端Conformer和TDNN作为对比,这些系统均未进行预训练。同时,i-vector作为一种有效且广泛使用的说话人特征提取方法,也被纳入比较。
结果如表1所示,我们的方法与基线模型Whisper-medium相比,CER相对减少了13.04%(绝对值减少了0.9%),且优于其它方法。对于具有较高构音障碍程度的语音(F.1, F.2),我们的方法仍表现出最佳性能,特别是对于最严重的F.1,CER相对减少达35.78%(绝对值减少了3.9%)。
表1 Conformer、TDNN、经过微调的Whisper-medium、使用i-vector (Whisper-iVector) 进行说话人自适应的Whisper-medium以及应用了我们提出的Perceiver-Prompt的Whisper (Whisper-PP) 的性能。
3. Perceiver-Prompt****的灵活性分析
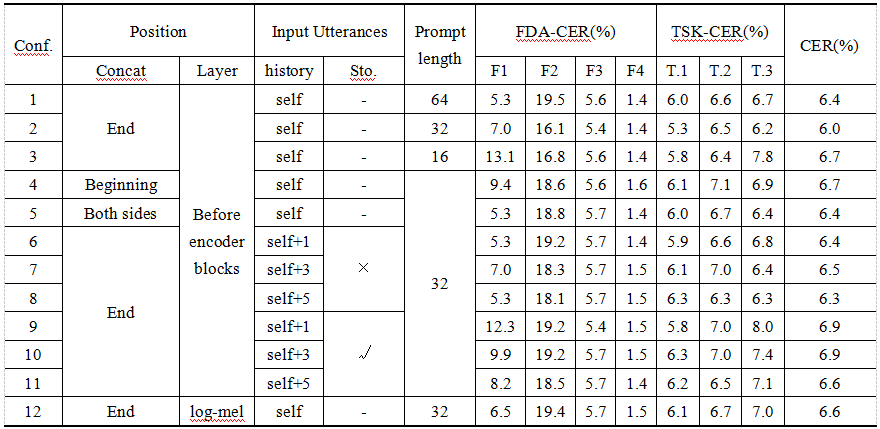
Perceiver-Prompt在多种配置下展现了良好的灵活性和性能,实验结果如表2所示。通过调整配置,我们的方法可以适用于不同的任务和障碍程度。例如,使用来自同一说话人的5个历史语句(Conf.8)生成的说话人提示,F.1程度的CER最低为5.3%,相较于未自适应的Whisper相对减少了51.38%。句识别任务中,系统Conf.2的表现最佳,CER为6.2%。总体而言,Perceiver-Prompt在各种配置下均优于基线模型,最低CER为6.0%,字、词和句识别任务的最低字错误率分别为5.3%、6.3%和6.2%。
表2 Perceiver-Prompt在各种配置和训练方法下的表现。在所有配置下模型都相比之前取得了更好的效果,并且在特定场景下进行有针对性的调整可以带来性能的提高。“self”表示当前的话语。“Sto.”指的是随机性地选择来自同一说话人的数据。
4.使用附加信息进行联合训练
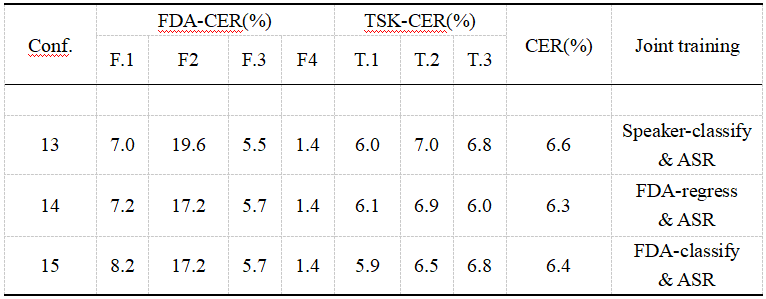
我们将FDA和说话人标签引入,利用监督学习提供的额外信息帮助Perceiver-Prompt更好地适应构音障碍语音识别任务。我们利用多层感知器(MLP)完成了三种训练,在训练过程中使用不同的监督方式:(1)对每个语音样本进行说话人分类,(2)对每个语音样本进行FDA评分回归,以及(3)对每个语音样本的FDA严重程度进行分类,将正常语音视为第五类。表3展示了不同方法联合训练的结果,结果表明联合训练能取得理想的性能,在利用FDA回归时,句子识别任务的性能尤为优越,CER仅为6.0%。
表3不同联合训练方法下的模型表现
通过t-SNE分析处理后的说话人Prompt如图2所示,表明Perceiver-Prompt生成的说话人Prompt在一定程度上能够区分不同说话人和各种FDA严重程度。更多历史信息的引入增强了说话人区分能力,但这并不一定保证在构音障碍语音识别任务中的性能提升。
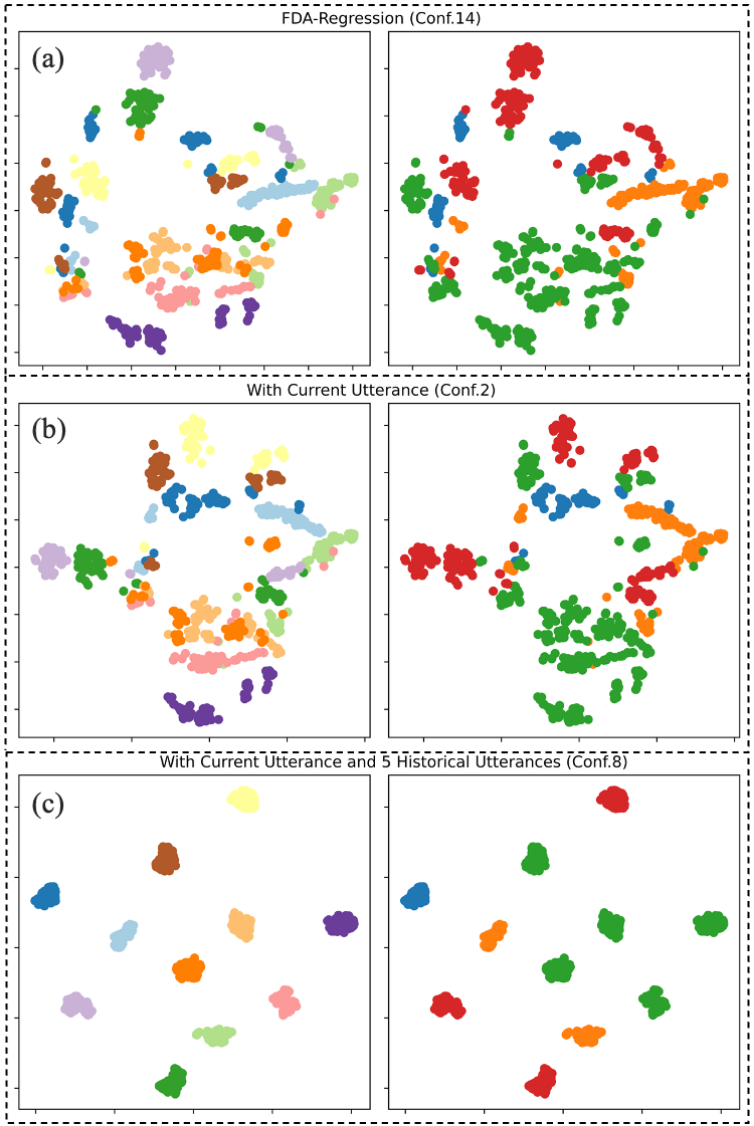
图2 三个子图(a)、(b)和© 分别代表Conf.14、Conf.2和Conf.8 的t-SNE分析结果。左栏代表说话人的t-SNE分析,不同颜色表示不同的说话人。右栏代表FDA 严重级别的t-SNE分析,不同颜色表示不同的FDA 严重程度。
【结论】
本文提出了Perceiver-Prompt,一种基于P-tuning的说话人自适应方法,旨在改善构音障碍语音识别的性能。通过采用联合训练和结合多个历史语句等方法和配置,该方法能够生成适应不同构音障碍严重程度或不同语音任务的Prompt。在我们的中文构音障碍语音数据集中,应用Perceiver-Prompt的Whisper相较于Conformer、TDNN以及使用/不使用i-vector的微调后的Whisper最高相对降低了13.04%的CER。根据我们的了解,这是首次将P-tuning应用于大规模语音模型Whisper的说话人自适应方法。
【论文链接】 https://arxiv.org/abs/2406.09873
【参考文献】
[1] A. Radford, J. W. Kim, T. Xu, G. Brockman, C. Mcleavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” in Proceedings of the 40th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, Eds., vol. 202. PMLR, 23–29 Jul 2023, pp. 28 492–28 518.
[2] W.-N. Hsu, B. Bolte, Y.-H. H. Tsai, K. Lakhotia, R. Salakhutdinov, and A. Mohamed, “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,” 2021.
[3] A. Baevski, H. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” 2020.
[4] J. Liu, X. Du, S. Lu, Y.-M. Zhang, H. An-ming, M. L. Ng, R. Su, L. Wang, and N. Yan, “Audio-video database from subacute stroke patients for dysarthric speech intelligence assessment and preliminary analysis,” Biomedical Signal Processing and Control, vol. 79, p. 104161, 2023.
[5] S. Watanabe, T. Hori, S. Karita, T. Hayashi, J. Nishitoba, Y. Unno, N. Enrique Yalta Soplin, J. Heymann, M. Wiesner, N. Chen, A. Renduchintala, and T. Ochiai, “ESPnet: End-to-end speech processing toolkit,” in Proceedings of Interspeech, 2018, pp. 2207–2211.
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 2131
2131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









