 AI大模型学习与本地部署解决方案
AI大模型学习与本地部署解决方案




ollama官网:https://ollama.com/
ollama项目地址:https://github.com/ollama/ollama

dify官网:https://dify.ai/
dify项目地址:https://github.com/langgenius/dify
粗略教程:下载ollama→ollama下载大模型(qwen2)→下载docker(win)→下载dify源码(github)→启动docker拉取镜像→docker启动dify→打开浏览器使用dify
大部分教程也跟上述一样,**我主要是解决一下粉丝遇到的问题(90%概率遇到),附解决方案,**看完上面那篇再回来~
\1. 下载ollama肯定没问题,怎么下载大模型呢,在官网搜索模型点进去有下载代码,复制。电脑win+R,输入cmd回车,输入
ollama pull qwen2.5:7b
运行完就完成了,卡的话可以开vpn,记得【启用Tun模式】
\2. docker拉取镜像出现问题。试了改镜像源,无果。也可以试试改镜像源啦
解决办法是,开v2ray/clash,而且要开tun模式,使用新加坡/美国节点,跑得通说明没问题,电信容易遇到cloudflare验证问题,换移动重试。
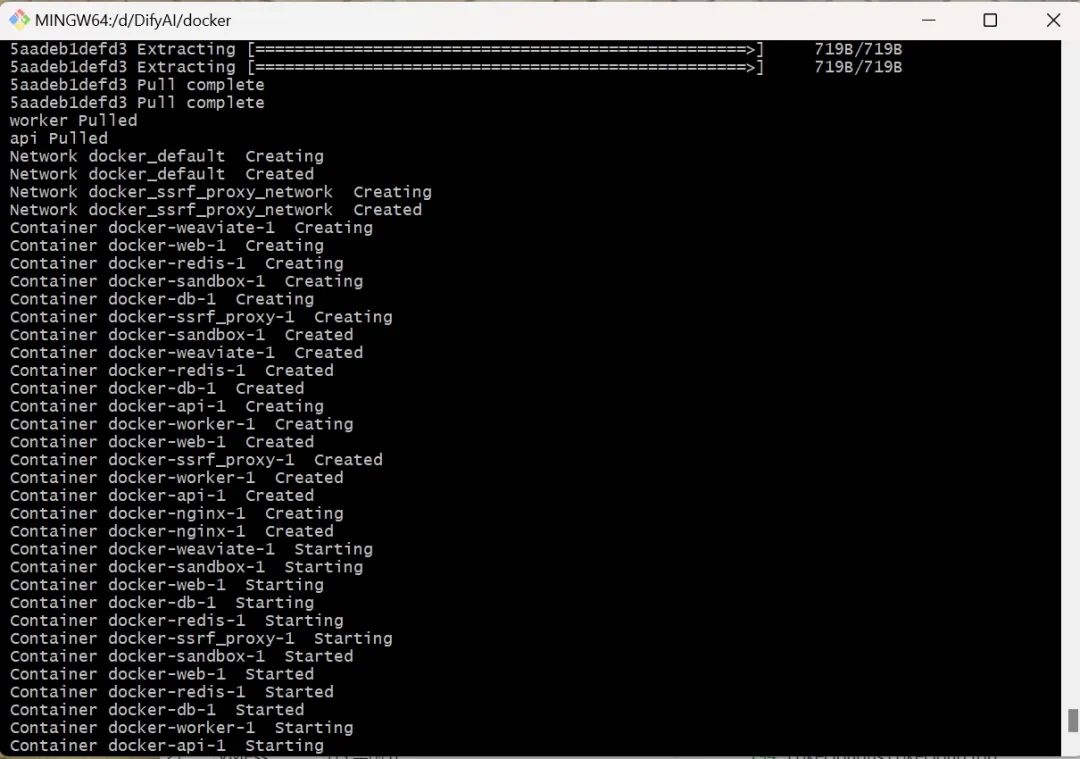
成功了就这样。然后就能顺利打开dify了。
\3. dify上传文件到知识库提示“排队中”,见于首次部署后上传文件遇到。看下图文件路径 【文件后缀名记得打开】
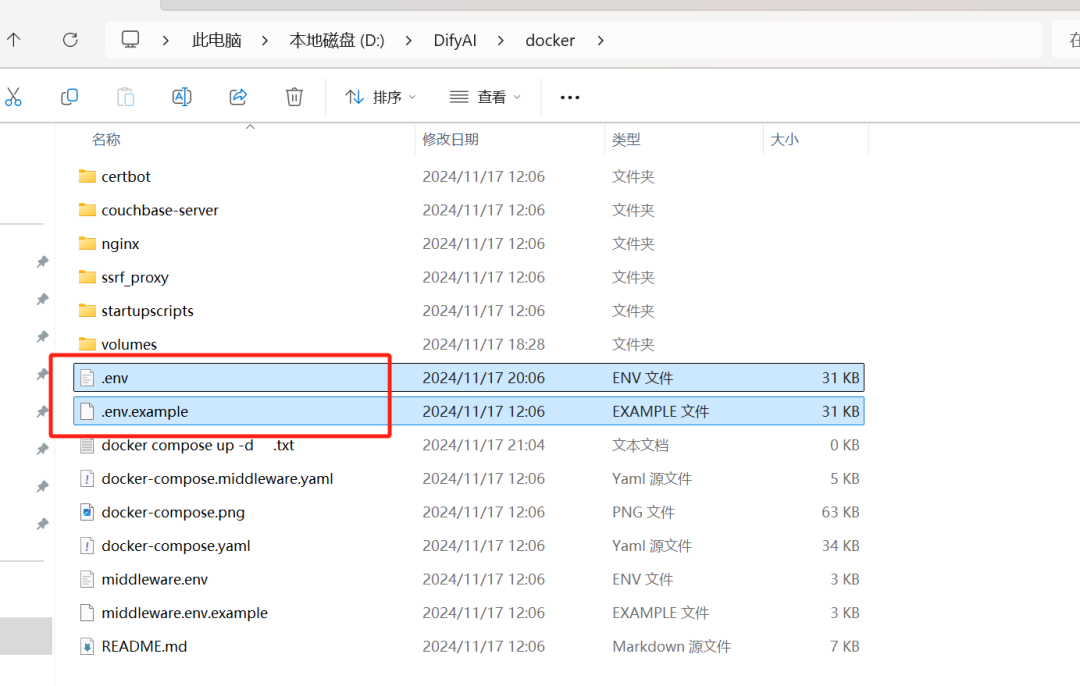
解决办法:文件路径看上图,把【.env.exemple】,复制一份,改文件后缀名为【.env】,然后打开文件
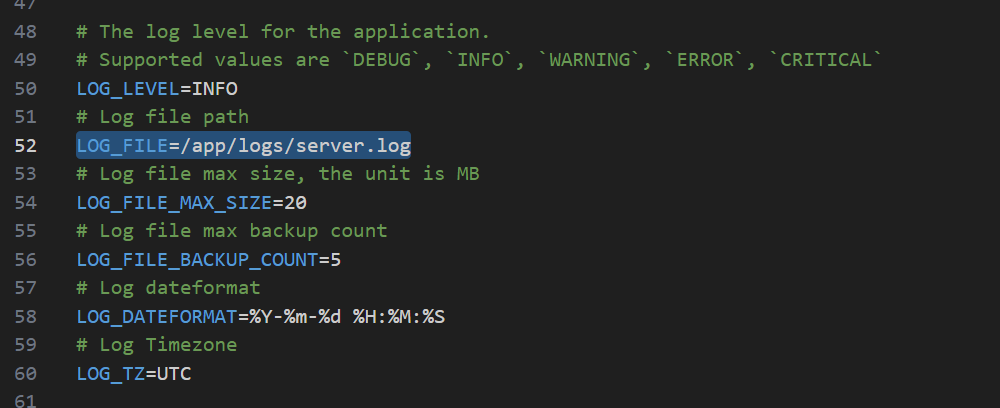
LOG_FILE=/app/logs/server.log
加上,然后回到docker界面,重新运行docker compose up -d,解决!
\4. 模型推荐
embed模型推荐下面这个,即把文本转化为向量数据的,同样ollama下载
推理模型可以选择Qwen2.5或者llama3或者gemma,我用的qwen2.5。然后就是模型大小,正常电脑就选择7b,8b这样的,大的比较难带动,体积也大。
dify是我目前用的一个本地大模型解决方案,感觉是比anything好一点的,anything唯一好处就是下载什么的都很快,然后就没别的好处了
小白可以上b站搜教程,一大把,写这期主要也是**分享一下目前有这么一些东西,本地部署知识库,**乍一听还是很唬人的,但是要真到达高度可用的阶段,恐怕还是有很长的路要走啊
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 897
897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









