



在当今数字化时代,数据就是新的石油,是驱动企业决策、学术研究和创新发展的核心资源。然而,海量的数据分散在各个角落,如何高效地收集这些数据,成为了许多人面临的难题。今天,就让我们一起探索批量爬取数据的奥秘,解锁数据宝藏的秘钥!
🌐 为什么需要批量爬取数据?
在商业领域,企业需要收集市场数据、竞争对手信息、消费者评价等,以便进行精准营销、优化产品策略。在学术研究中,研究人员需要大量的数据来支持他们的假设和模型。无论是市场分析师、数据科学家还是普通的研究者,批量爬取数据都是一种高效获取信息的手段。
🛠️ 批量爬取数据的工具与技术
1. Python:数据爬取的瑞士军刀
Python 是目前最流行的数据爬取语言之一,它拥有强大的库和框架,如 Requests、BeautifulSoup、Scrapy 等,可以帮助我们轻松地发送网络请求、解析网页内容并提取数据。
-
Requests:用于发送 HTTP 请求,获取网页内容。
-
BeautifulSoup:用于解析 HTML 和 XML 文档,提取所需数据。
-
Scrapy:一个强大的爬虫框架,支持大规模数据爬取,具有自动处理请求、数据提取、数据存储等功能。
2. Selenium:模拟浏览器的神器
Selenium 是一个自动化测试工具,但它也可以用于数据爬取。它可以模拟真实用户的行为,如点击、输入、滚动等,非常适合处理动态加载的网页数据。
3. API 爬取:高效且稳定
许多网站提供了 API 接口,允许开发者以编程方式访问数据。通过调用 API,我们可以快速获取结构化的数据,避免了网页解析的复杂性。例如,Twitter、GitHub 等都提供了丰富的 API,方便开发者获取数据。
💡 批量爬取数据的步骤
1. 确定目标
在开始爬取之前,首先要明确你的目标是什么,需要从哪些网站获取哪些数据。这一步非常重要,因为它将决定你后续的爬虫设计和数据处理方式。
2. 分析网页结构
使用浏览器的开发者工具(如 Chrome DevTools)分析目标网页的结构,找到数据所在的 HTML 元素。如果是动态加载的数据,还需要查看网络请求,找到数据的来源。
3. 编写爬虫代码
根据分析结果,使用合适的工具编写爬虫代码。如果是静态网页,可以使用 Requests 和 BeautifulSoup;如果是动态网页,可以使用 Selenium;如果有 API 接口,直接调用 API 即可。
4. 数据存储
爬取到的数据需要存储起来,常见的存储方式有:
-
CSV 文件:适合存储结构化数据,方便后续分析。
-
数据库:如 MySQL、MongoDB 等,可以存储大量数据,并支持复杂查询。
-
云存储:如 AWS S3、阿里云 OSS 等,适合存储大规模数据。
5. 遵守法律法规
在爬取数据时,一定要遵守相关法律法规和网站的使用条款。未经授权的数据爬取可能会导致法律风险,甚至被封禁 IP 地址。
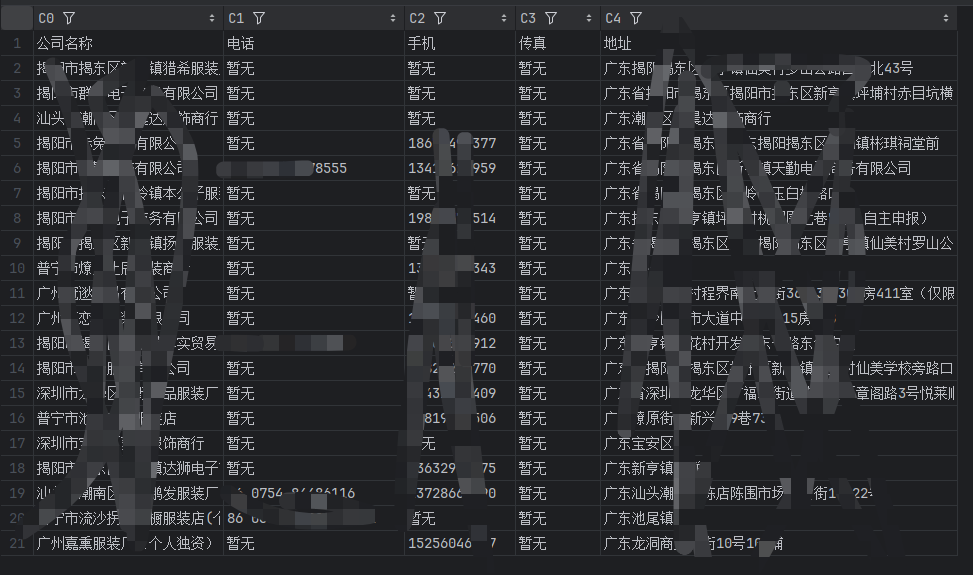
示例应用场景:
批量爬取很多供应商公司的联系方式和地址

















 2061
2061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









