



 该文详细介绍了如何下载并使用Yolox模型,包括从GitHub获取源码,通过百度网盘链接下载预训练模型,修改训练配置如数据集和类别,处理训练时的库冲突问题,以及训练后模型的测试和应用到图像或摄像头视频上。
该文详细介绍了如何下载并使用Yolox模型,包括从GitHub获取源码,通过百度网盘链接下载预训练模型,修改训练配置如数据集和类别,处理训练时的库冲突问题,以及训练后模型的测试和应用到图像或摄像头视频上。
1.首先给出yolox原模型的下载地址:
https://github.com/bubbliiiing/yolox-pytorch
百度网盘链接给出自己完整的模型(包括数据集以及权重文件):
链接:https://pan.baidu.com/s/1JNjB42u9eGNhRjr1SfD_Tw
提取码:otq0
2.训练模型:修改模型里面的数据集以及一些参数
1.选择配置好的深度学习环境
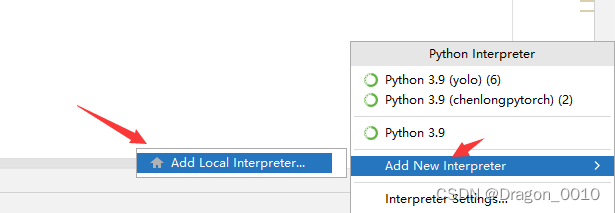
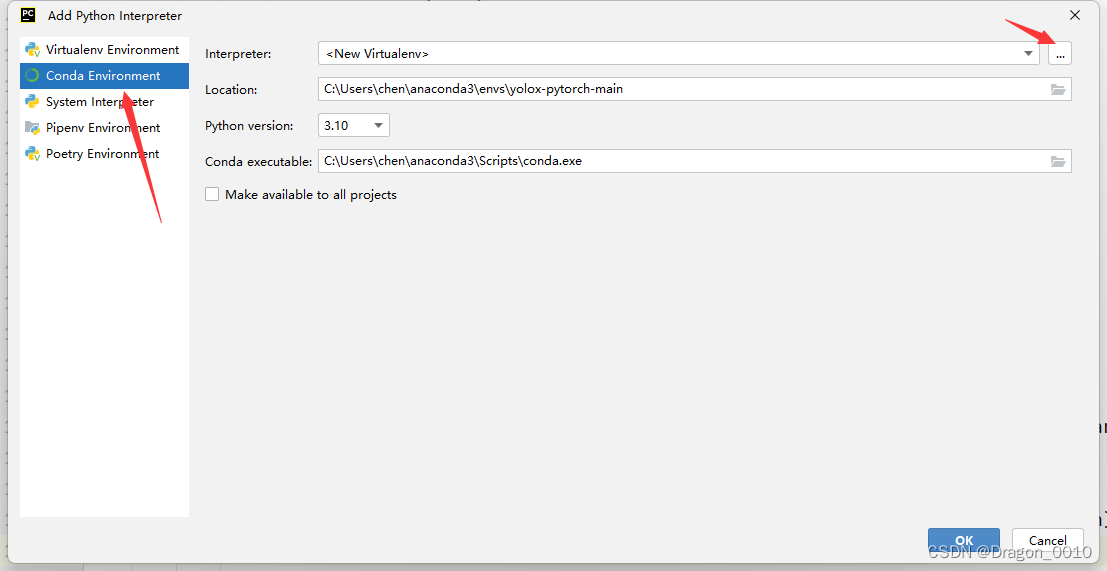
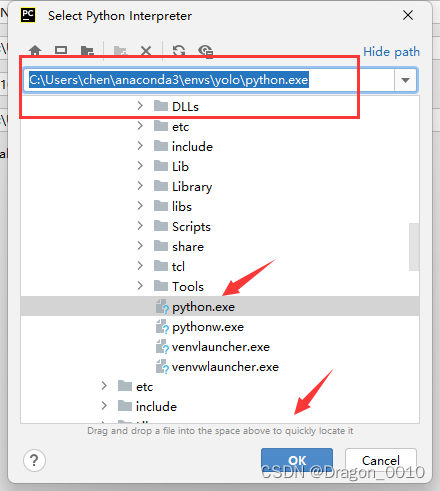
2.修改train.py里面的classes_path,将自己想要分类的类别填充进去

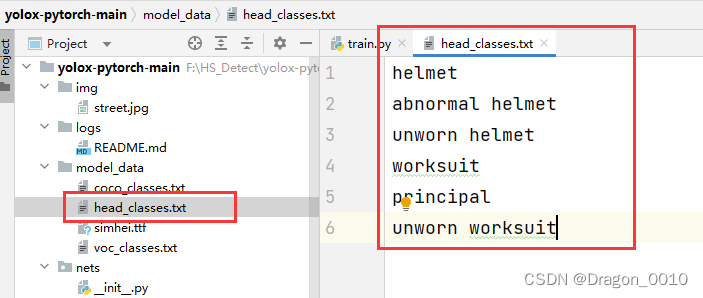
3.修改权重文件
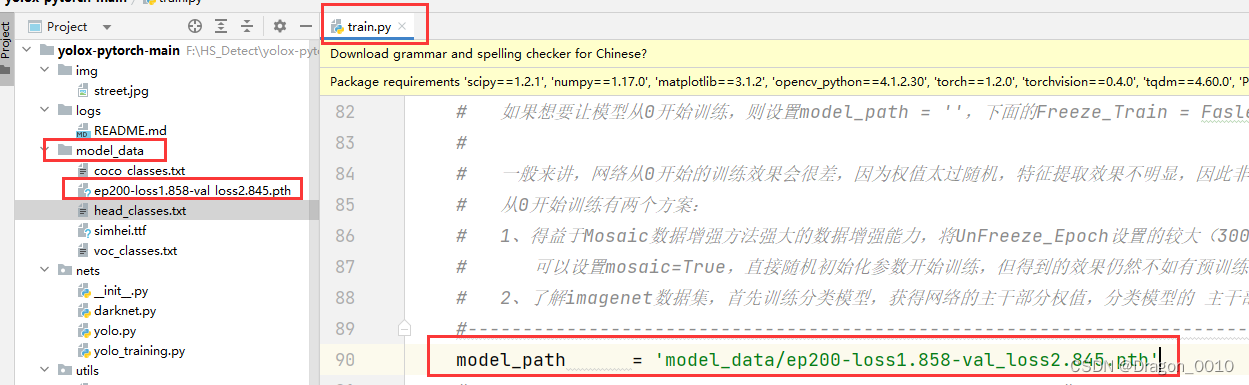
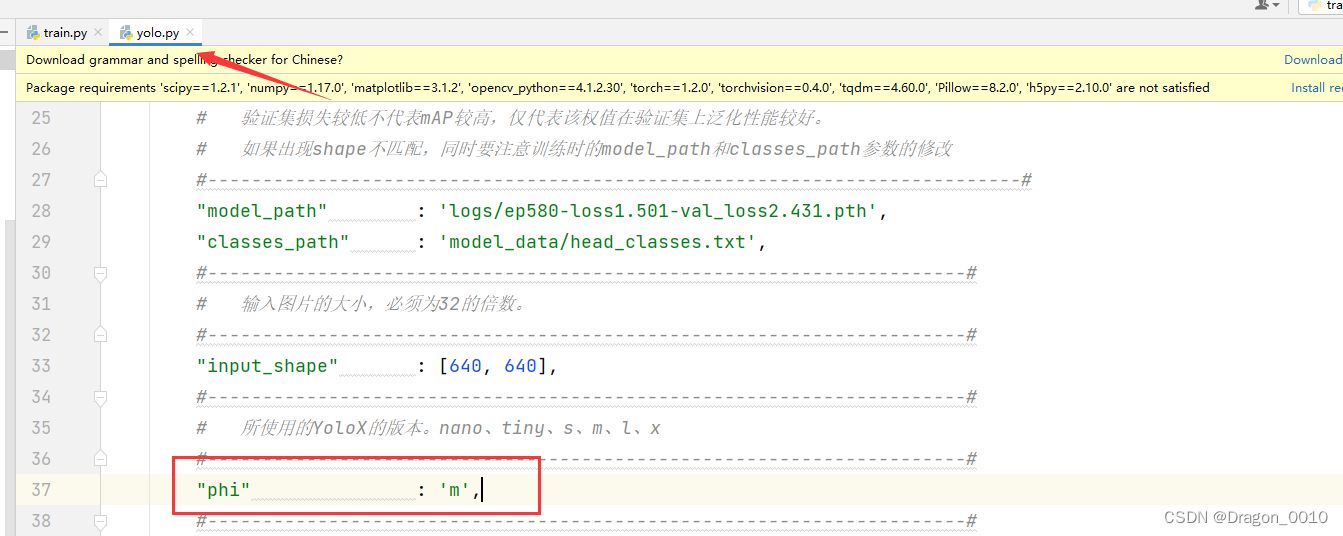
如果使用yolox_m作为初始权重来训练,需要将phi的值修改为m
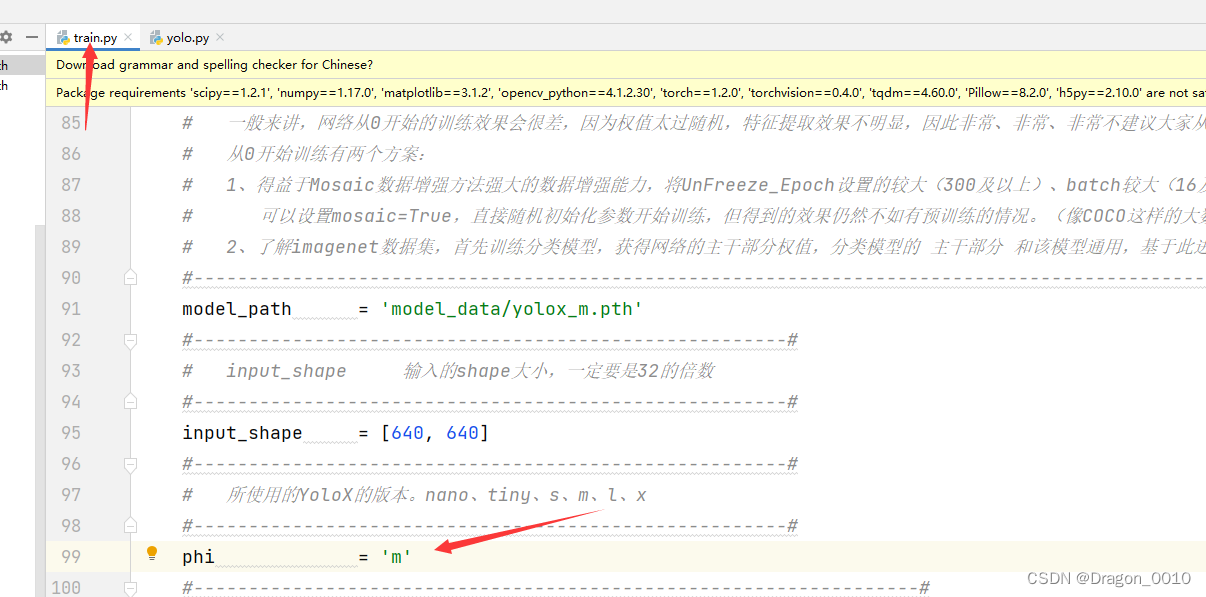
4.修改冻结阶段和非冻结阶段的epoch 和batch_size,不启用冻结阶段
batch_size设置为8,因为设置为16之后发现爆显存了
epoch设置为600
5.划分训练集和测试集
为了省去不必要的麻烦,将自己的数据集名称改为VOC2007,放在VOCdevkit文件夹下面
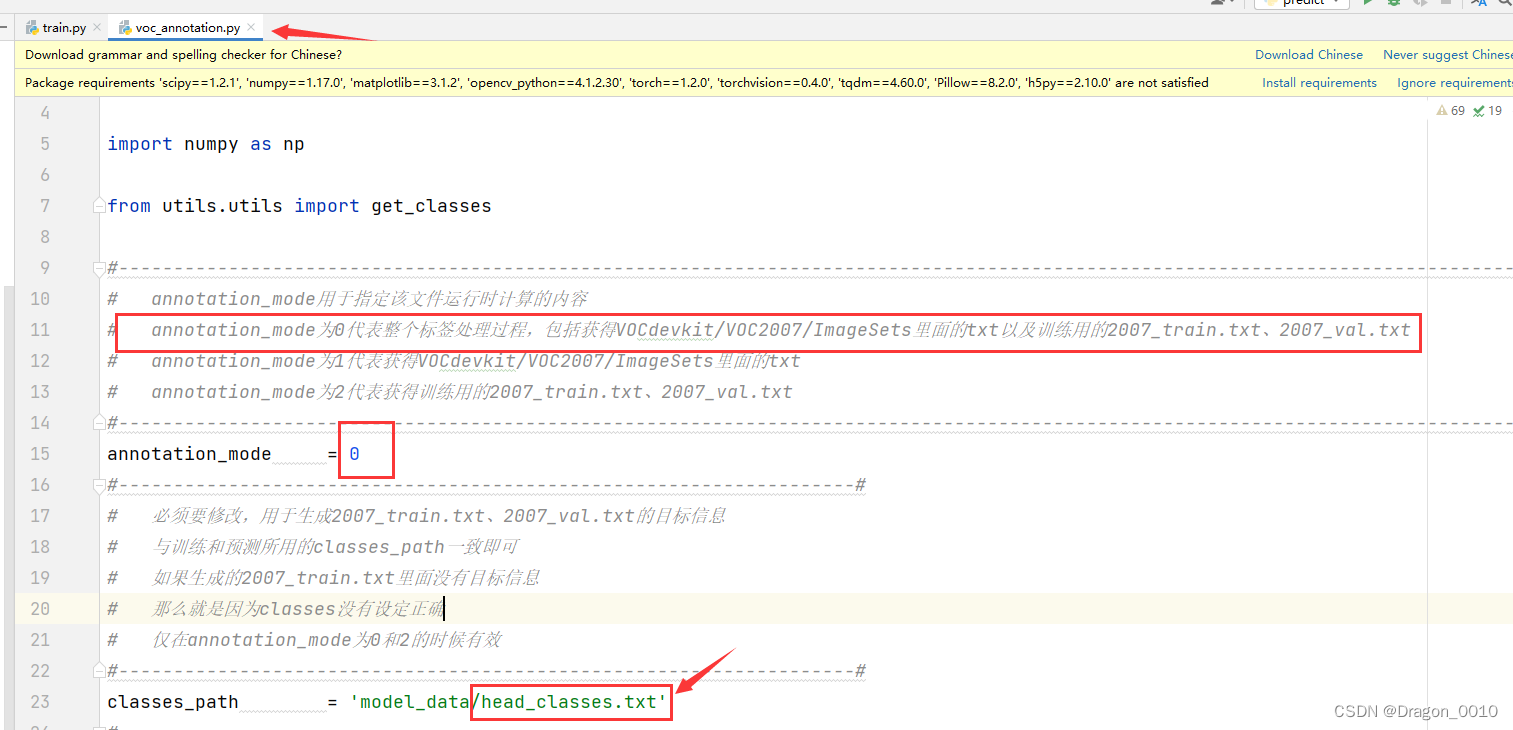
然后运行voc_annotation.py
会生成这些文件
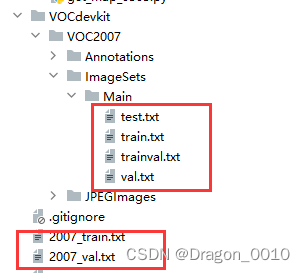
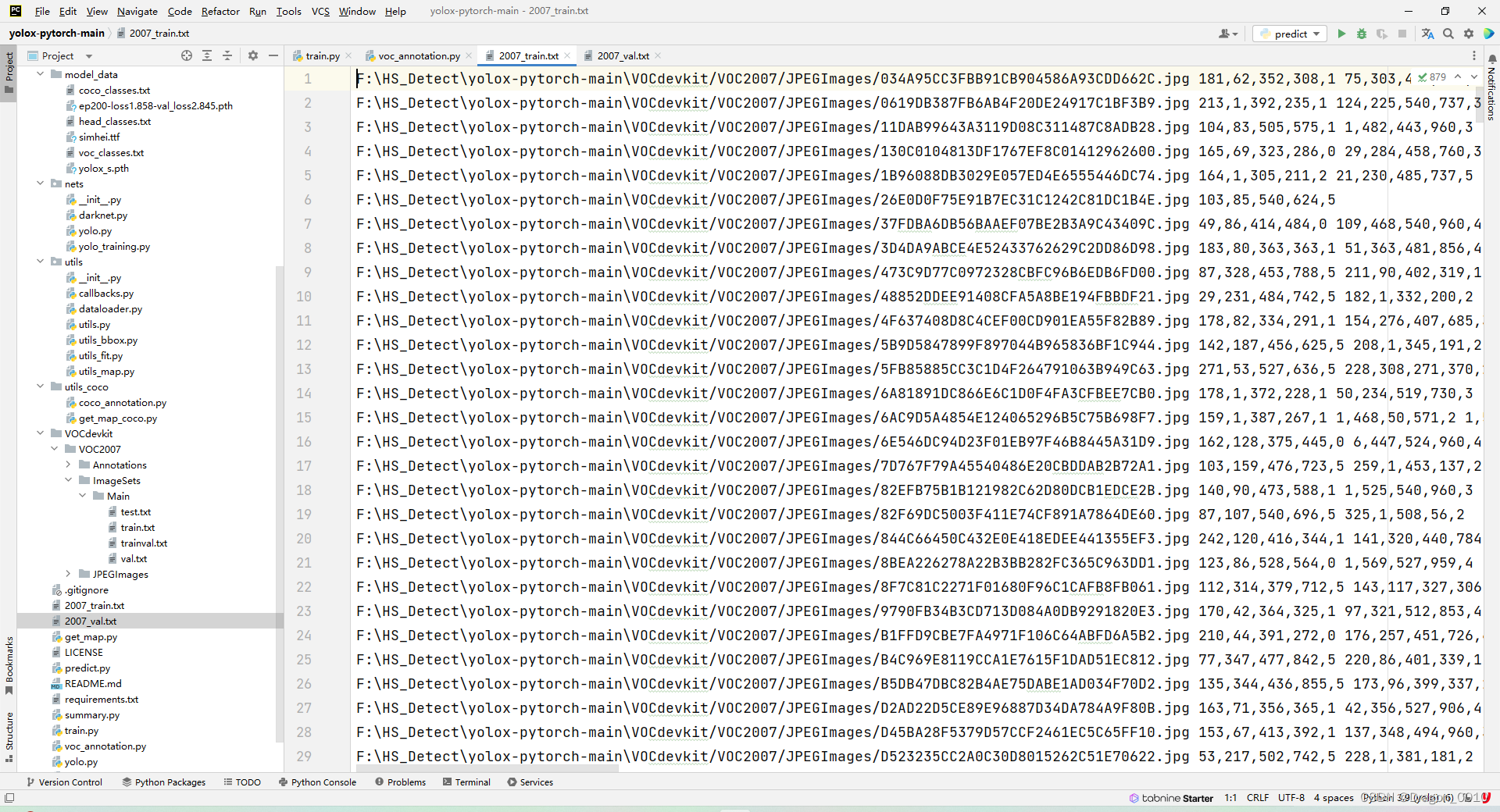
里面是图片的路径,以及标注框的坐标
6.在训练中遇到报错:Initializing libiomp5md.dll, but found libiomp5md.dll already
解决办法:
在训练代码的开头加上这一行代码:
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"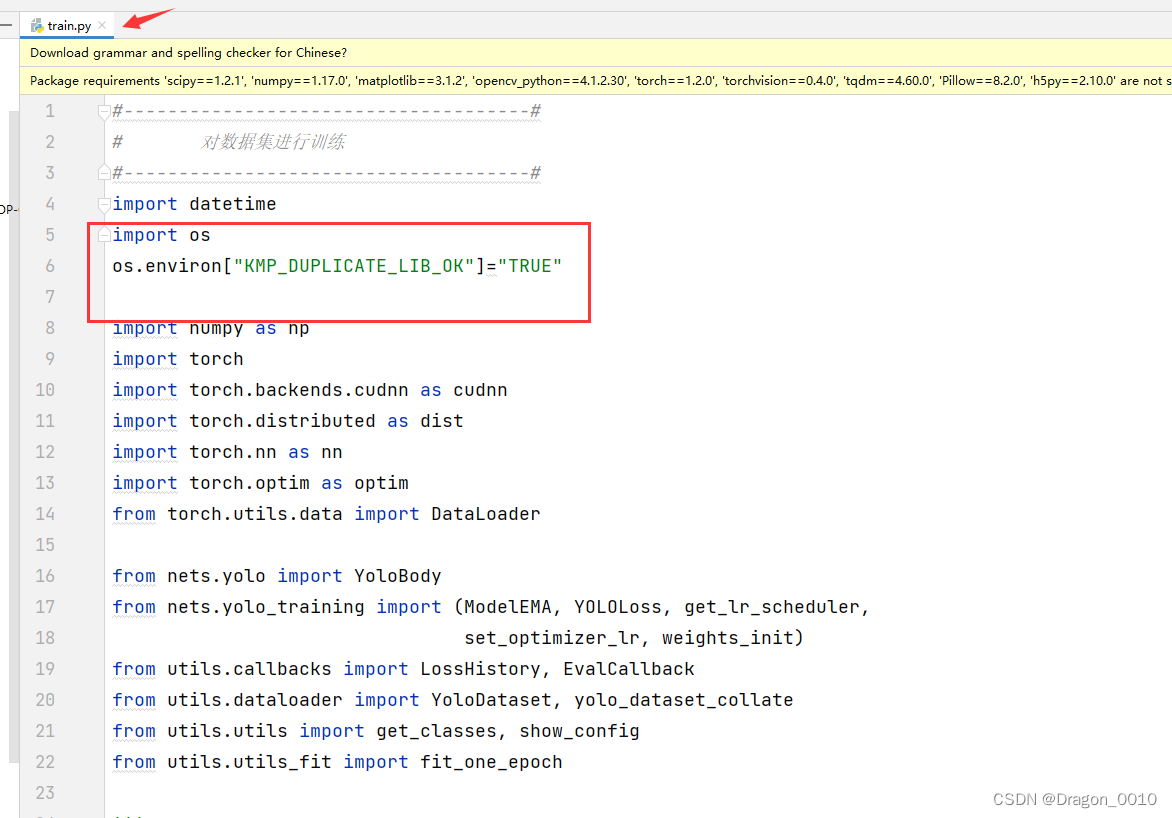
7.运行train.py,开始训练
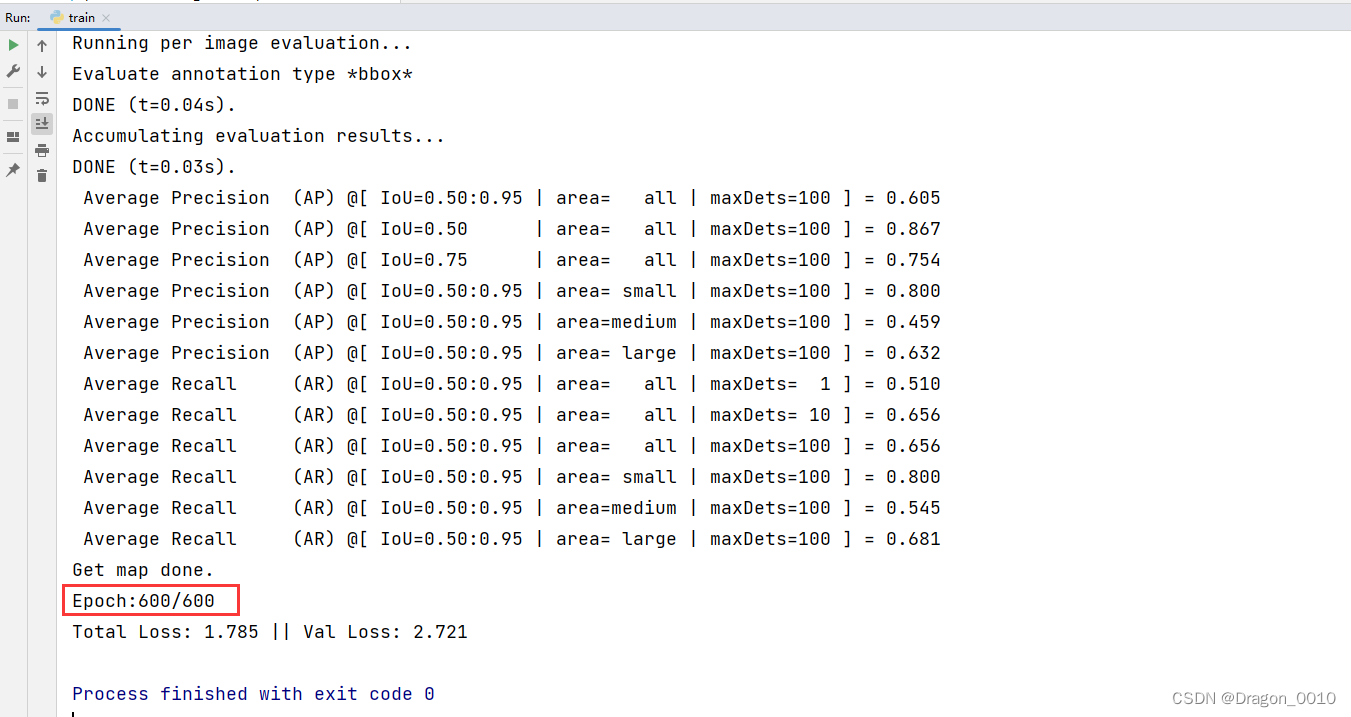
8.得到训练结果和权重文件
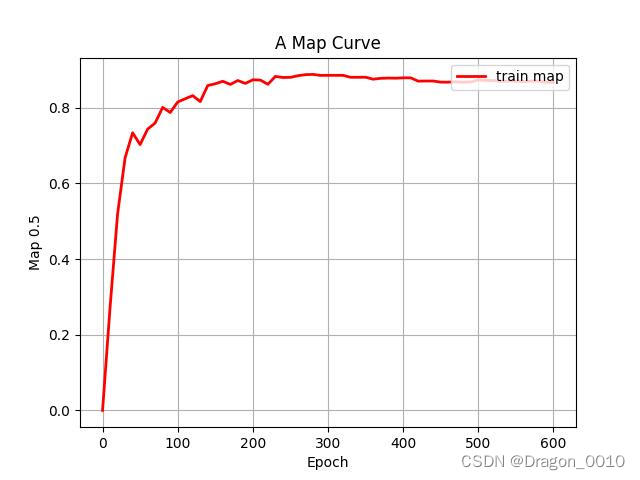
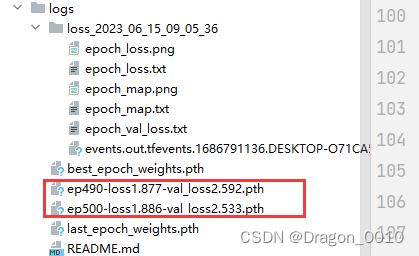
2.将训练好的模型来进行测试
1.在yolo.py里面修改分类路径以及损失最小的模型权重文件的路径
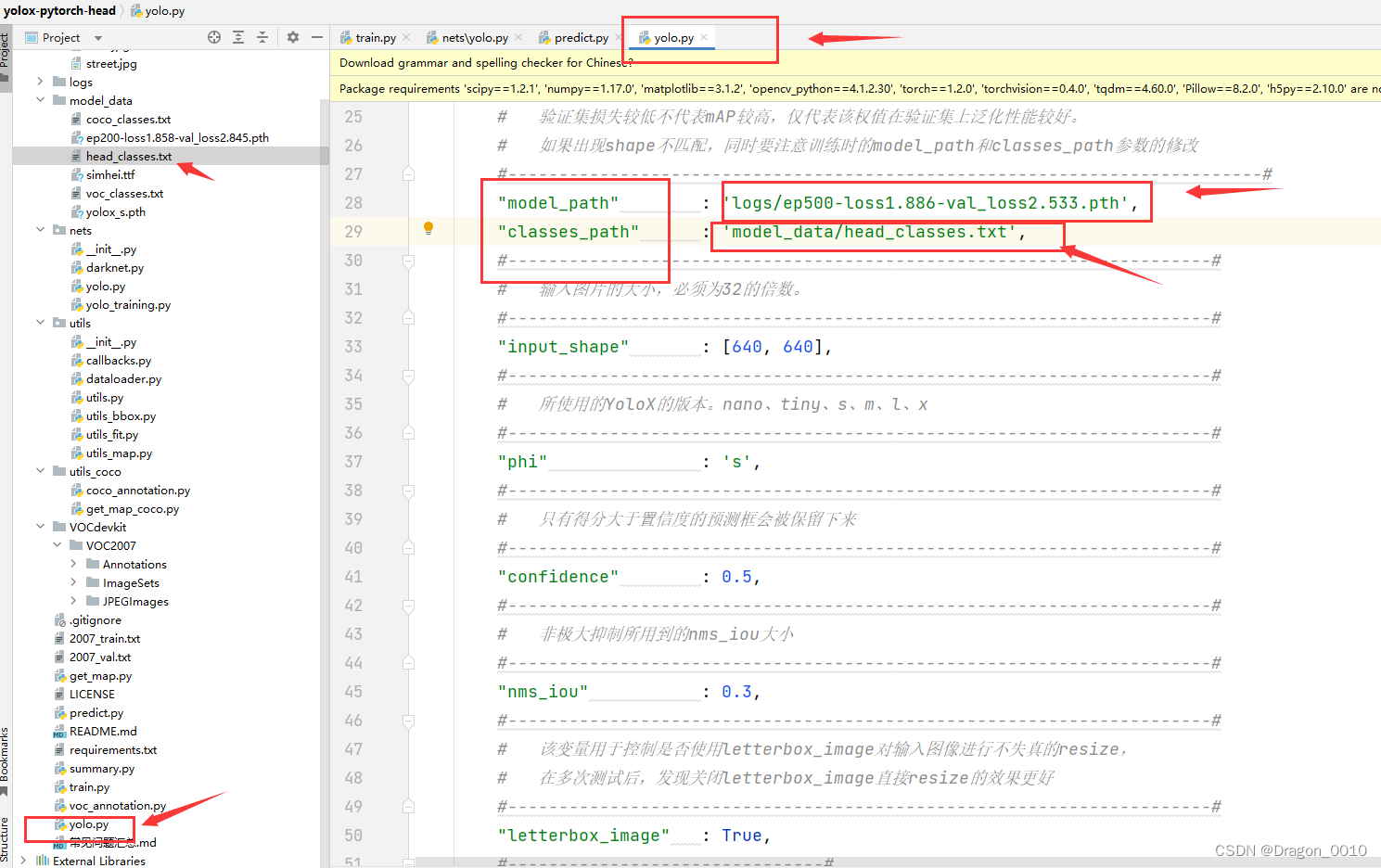
2.如果在训练的时候修改了phi,比如说训练使用的是yolox_m权重,那么测试的时候也要修改成对应的phi
3.遇到报错:No module named 'onnx',有包没有导入
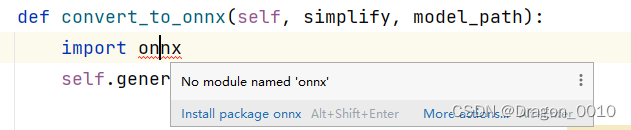
直接点这个Install package onnx

导入成功,报错解决
4.运行predict.py,输入图片路径来进行测试
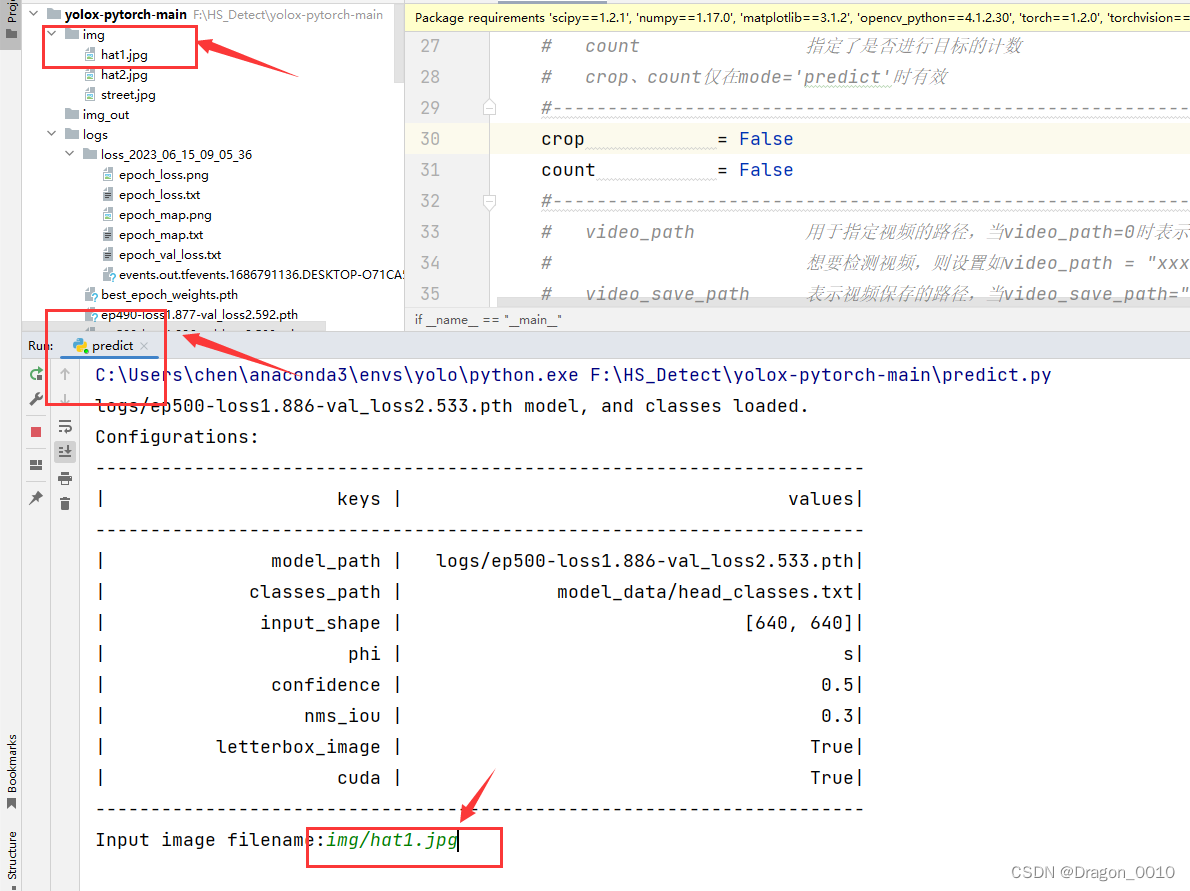
hat1.jpg
 得到测试结果
得到测试结果

hat2.jpg

得到测试结果

也可以使用摄像头或者视频来进行识别:修改一下mode的值
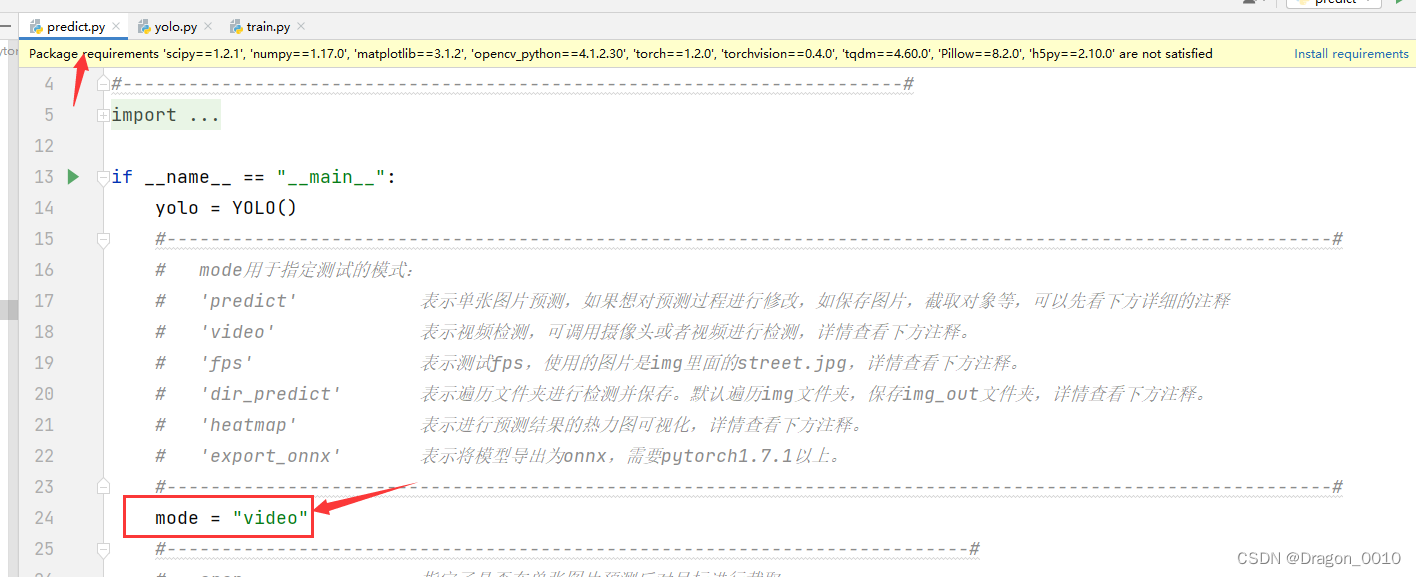
看的出来,效果还是很好的。


















 1645
1645




 到【灌水乐园】发言
到【灌水乐园】发言







