







As Sutton said in the Bitter Lesson, there’re only 2 techniques that scale indefinitely with compute: learning & search. It’s time to shift focus to the latter.
正如萨顿在《痛苦的教训》中所说,只有两种技术可以随着计算无限扩展:学习和搜索。是时候将焦点转移到后者了。
HightLight
- OpenAI o1最大的技术特征是什么:RL训练和推理,在传统COT之外隐藏了一个很长的内在COT,满足scaling law。 long internal chain of thought,LLM从 system1 -> system2
- OpenAI o1 的性能表现:理工科方面 (智力) 断崖碾压GPT4-o,达到人类竞赛选手,以及博士生水平,文科方面和o1比没有优势。
技术原理
- 在训练阶段,会通过强化学习,让o1完善其思维链并优化所使用的策略。例如:识别并纠正错误,将复杂步骤拆分为简单步骤,当前方法不work时,换一种方法。
- 在推理阶段,模型同样会在呈现给用户的cot之外,做一个更深的的所谓的long internal chain of thought,所以推理时间会更长,相当于COT套娃了,给COT再加一个COT(猜测是把MCTS搜索过程序列化了)。
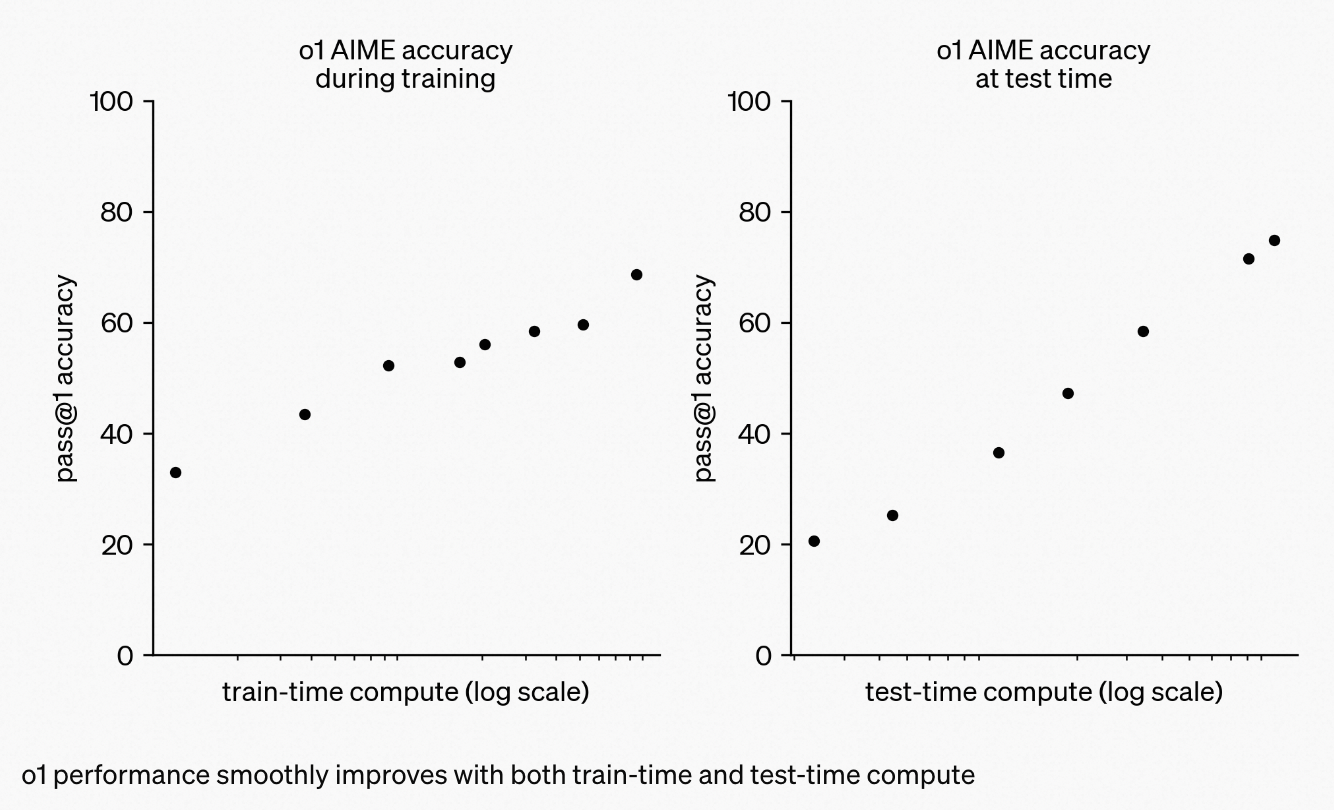
满足 Scaling Law,在训练和测试时的时间都能和性能形成对数线性关系。
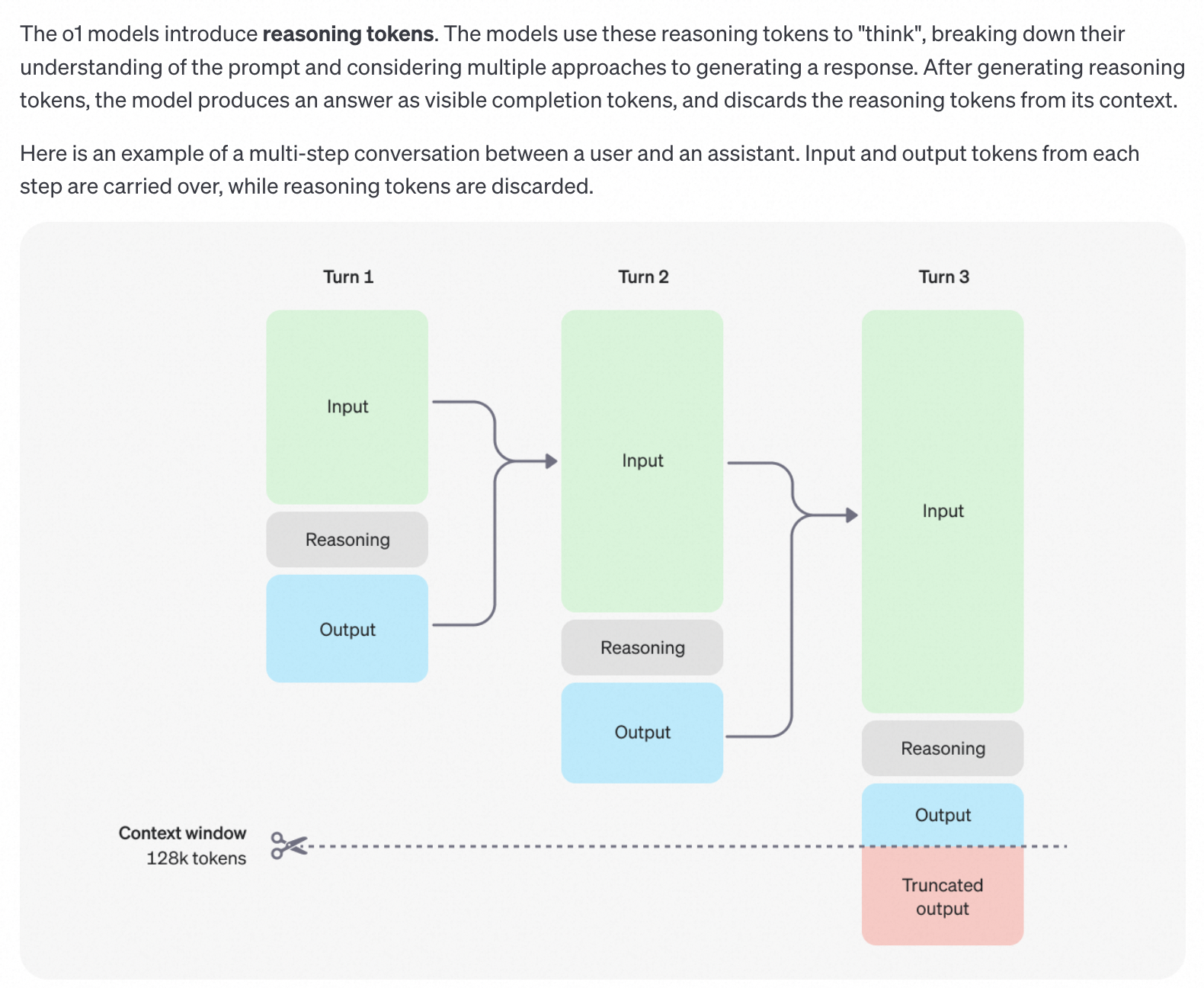
Reasoning 在o1模型中的工作原理

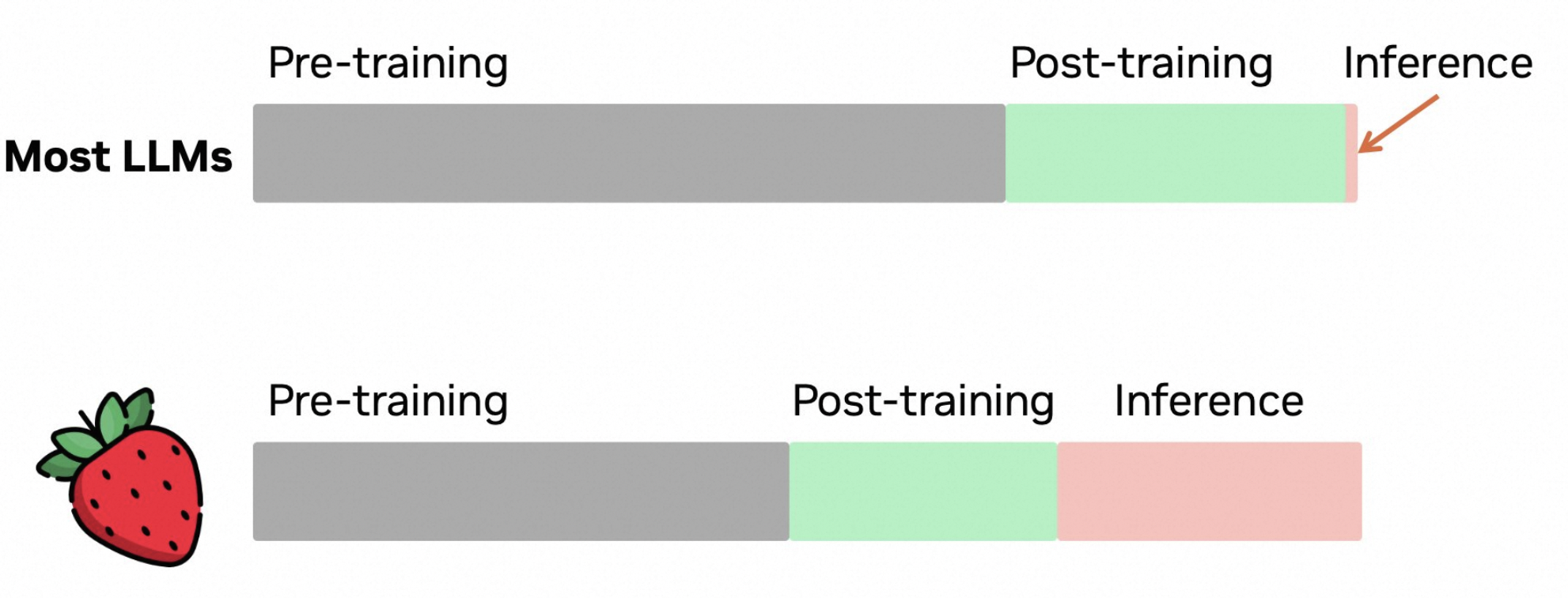
关于 inference scaling law, two recently papers:
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling. Brown et al. finds that DeepSeek-Coder increases from 15.9% with one sample to 56% with 250 samples on SWE-Bench, beating Sonnet-3.5.
布朗等人。发现 DeepSeek-Coder 在 SWE-Bench 上从 1 个样本的 15.9% 提高到 250 个样本的 56%,击败了 Sonnet-3.5。Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters. Snell et al. finds that PaLM 2-S beats a 14x larger model on MATH with test-time search.
斯内尔等人。发现 PaLM 2-S 通过测试时搜索在数学上击败了 14 倍大的模型
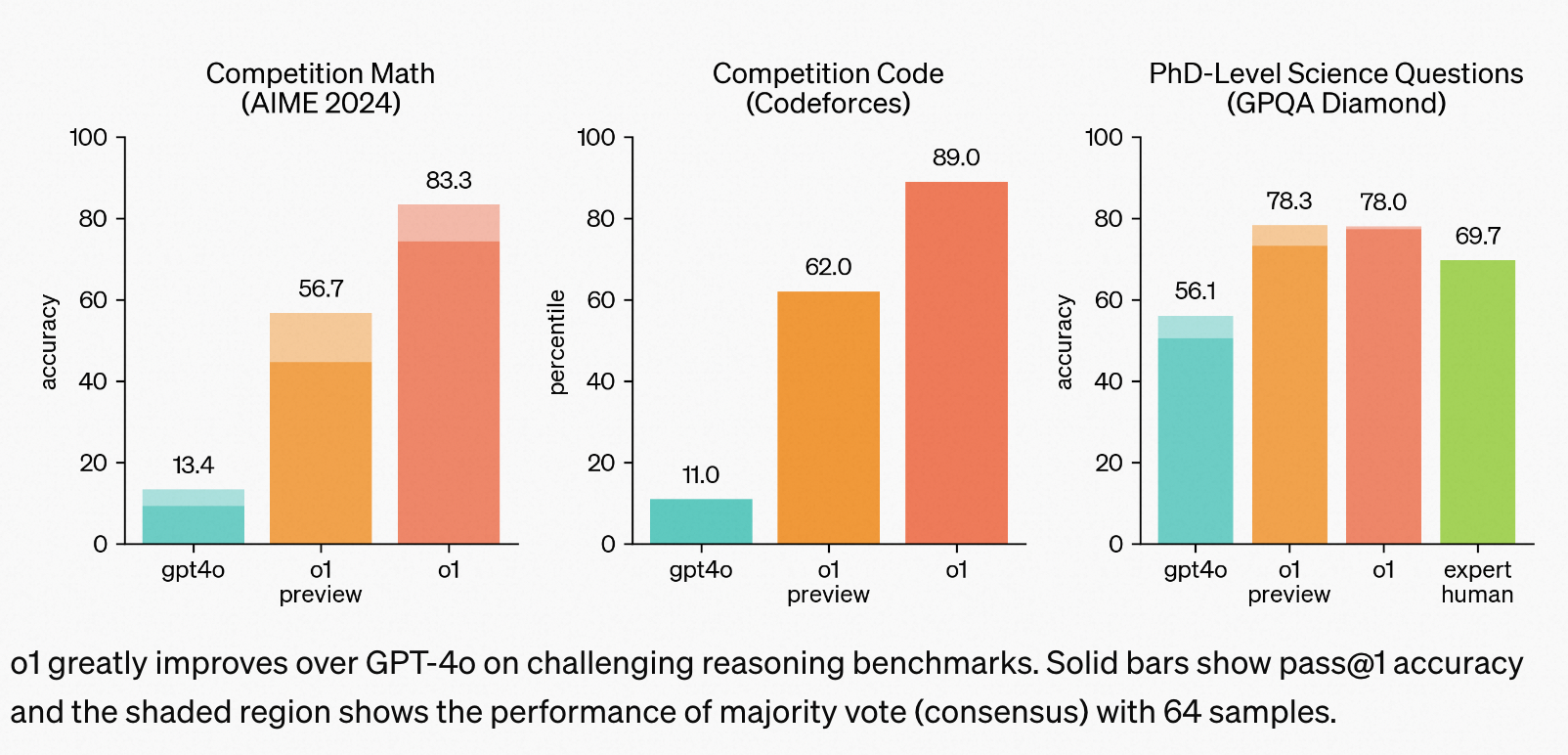
性能表现
- 在全美高中生数学竞赛AIME上,o1能达到74分(GPT4-o仅有12分),如果采样1000次,结合reward model加权投票能到93分,能排进全国前500名,超过USA Mathematical Olympiad的晋级分数线;
- 在GPQA,一个关于物理,化学和生物的智力测试上,OpenAI招募了一群相关领域有博士学位的专家和o1同台竞技, o1能够在GPQA-diamond questions.上超过这群专家。
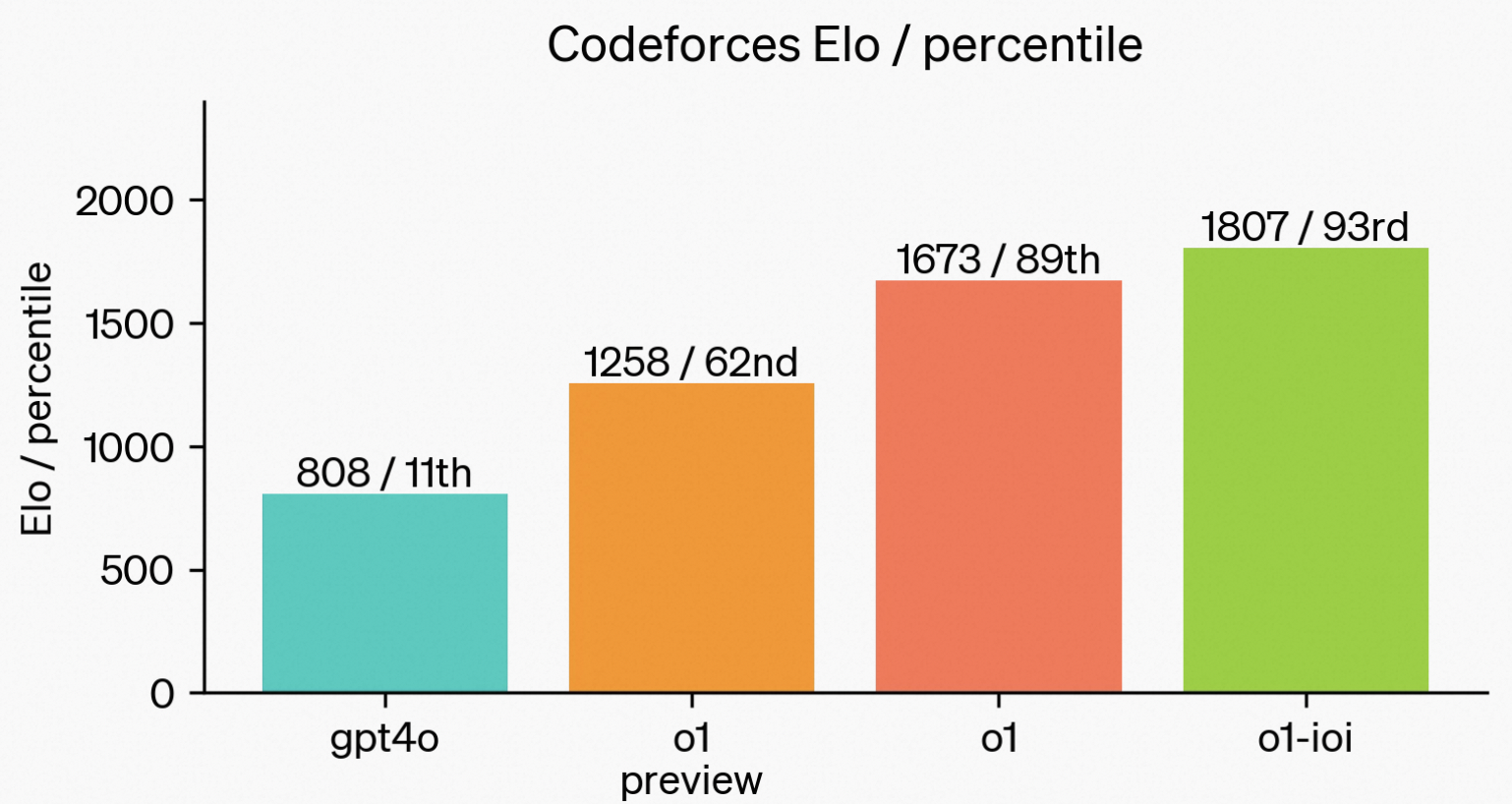
- OpenAI在o1的基础上加强了模型的代码能力,以o1为初始化又训了一个o1-IOI,获得216分的分数,在放开提交次数后,o1-IOI能获得362.14,超过了金牌线。和人类顶尖选手同台竞技,在CodeForce上,打出了惊人的1807分。
Limitation
当前版本暂不支持system messages,只支持user和assistant。不过相信后面的更新会支持。

适合对象
如果你正在解决科学、编码、数学和类似领域的复杂问题,这些增强的推理能力可能特别有用。例如,医疗研究人员可以使用 o1 来注释细胞测序数据,物理学家可以使用 o1 来生成量子光学所需的复杂数学公式,各领域的开发人员可以使用 o1 来构建和执行多步骤工作流程。
测试Case

Reference
[1]. https://openai.com/index/introducing-openai-o1-preview/
[2]. https://openai.com/index/learning-to-reason-with-llms/
[3]. https://cookbook.openai.com/examples/o1/using_reasoning_for_data_validation
[4]. https://cookbook.openai.com/examples/o1/using_reasoning_for_routine_generation
[5]. https://platform.openai.com/docs/guides/reasoning


















 289
289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









