



 本文详细介绍了HTTP协议的基本概念,包括GET和POST的区别,以及如何使用Python的requests库进行各种HTTP请求,如GET、POST、PUT和DELETE等。同时,文章还深入探讨了如何处理请求参数、响应内容、状态码、Cookie和Session,以及如何处理超时异常。
本文详细介绍了HTTP协议的基本概念,包括GET和POST的区别,以及如何使用Python的requests库进行各种HTTP请求,如GET、POST、PUT和DELETE等。同时,文章还深入探讨了如何处理请求参数、响应内容、状态码、Cookie和Session,以及如何处理超时异常。
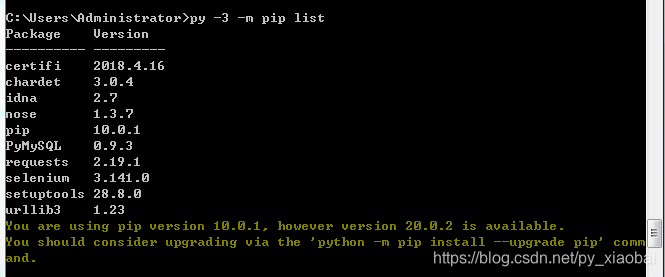
requests包安装
py -3 -m pip install requests
py -3 -m pip list
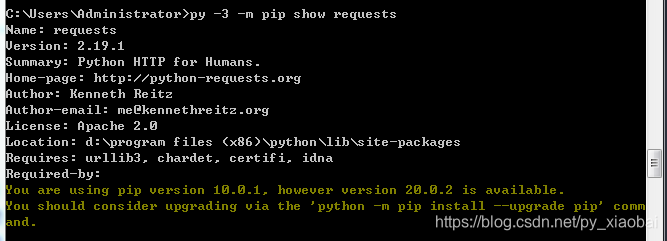
py -3 -m pip show requests
http协议:
客户端(浏览器、使用cmd):发送请求包---->>网站服务器返回给客户端服务器一个响应包
请求包:
首部:header(可以为空)
主体:body(可以为空)
响应包:
首部:header(可以为空)
主体:body(可以为空)
get和post的区别:
- Get是不安全的,因为在传输过程,数据被放在请求的URL中;Post的所有操作对用户来说都是不可见的。
- Get传送的数据量较小,这主要是因为受URL长度限制;Post传送的数据量较大,一般被默认为不受限制。
- Get限制Form表单的数据集的值必须为ASCII字符;而Post支持整个ISO10646字符集。
- Get执行效率却比Post方法好。Get是form提交的默认方法。
- Get是幂等的,post不是幂等的。(幂等:多次提交的数据对服务器的数据状态是没有任何影响的)
get
post
delete:删除数据
put:修改数据
options:服务器端支持哪些http的方法给我返回一下
head:只返回请求的头信息
http各种方法的请求方法:
#GET请求,通常用于获取数据,从服务器上拿数据,也可以存数据
requests.get('https://github.com')
#POST请求
requests.post('http://httpbin.org/post')
#PUT请求
requests.put('http://httpbin.org/put')
#DELETE请求
requests.delete('http://httpbin.org/delete')
#HEAD请求
requests.head('http://httpbin.org/get')
#OPTIONS请求
requests.options('http://httpbin.org/get')
>>> import requests
>>> c
>>> r.url
'https://github.com/Ranxf'
>>> r.text[:20]
'\n\n<!DOCTYPE html>\n<h'
>>>
>>>> r.headers
{'Date': 'Sun, 09 Feb 2020 10:41:48 GMT', 'Content-Type': 'text/html; charset=ut
f-8', 'Transfer-Encoding': 'chunked', 'Server': 'GitHub.com', 'Status': '200 OK'
, 'Vary': 'X-Requested-With, Accept-Encoding, Accept, Accept-Encoding', 'ETag':
'W/"5ad38663c15caa9cfcf463fe19cccf4c"', 'Cache-Control': 'max-age=0, private, mu
st-revalidate', 'Set-Cookie': '_octo=GH1.1.1687964200.1581244908; domain=.github
.com; path=/; expires=Tue, 09 Feb 2021 10:41:48 -0000, logged_in=no; domain=.git
hub.com; path=/; expires=Tue, 09 Feb 2021 10:41:48 -0000; secure; HttpOnly, _gh_
sess=cnhKK2w2bVJsWW9HUVNidE5ZK0FwN0NleTlaZW9UekNyVU1Qb25WcjdVWVRRYnhiT0hzVGZBYVp
wU0JSb1dYREg1eWNLVk5ZbTRLdEVzSml1MUI0VmJEcjJLbWFUZ1l4LzBmR0owK1ZaUm9KZHZQRUVJdko
1OVo4ZDlOQ1g1V3YrVGtmdDEwUFB2b2s2WUMyK3Y3U1hnPT0tLU9Bd2RLdDRhaGErL0VNZmdxWS8yOHc
9PQ%3D%3D--130089f14b4931a02776950c580e10c7545d2a6b; path=/; secure; HttpOnly',
'Strict-Transport-Security': 'max-age=31536000; includeSubdomains; preload', 'X-
Frame-Options': 'deny', 'X-Content-Type-Options': 'nosniff', 'X-XSS-Protection':
'1; mode=block', 'Referrer-Policy': 'origin-when-cross-origin, strict-origin-wh
en-cross-origin', 'Expect-CT': 'max-age=2592000, report-uri="https://api.github.
com/_private/browser/errors"', 'Content-Security-Policy': "default-src 'none'; b
ase-uri 'self'; block-all-mixed-content; connect-src 'self' uploads.github.com w
ww.githubstatus.com collector.githubapp.com api.github.com www.google-analytics.
com github-cloud.s3.amazonaws.com github-production-repository-file-5c1aeb.s3.am
azonaws.com github-production-upload-manifest-file-7fdce7.s3.amazonaws.com githu
b-production-user-asset-6210df.s3.amazonaws.com wss://live.github.com; font-src
github.githubassets.com; form-action 'self' github.com gist.github.com; frame-an
cestors 'none'; frame-src render.githubusercontent.com; img-src 'self' data: git
hub.githubassets.com identicons.github.com collector.githubapp.com github-cloud.
s3.amazonaws.com *.githubusercontent.com; manifest-src 'self'; media-src 'none';
script-src github.githubassets.com; style-src 'unsafe-inline' github.githubasse
ts.com", 'Content-Encoding': 'gzip', 'X-GitHub-Request-Id': '1360:020A:823483:B7
1F40:5E3FE1EA'}
给get请求传参数:
>>> url_params = {'q':'gloryroad'} #字典传递参数,如果值为None的键不会被添加到url中
>>> r = requests.get('https://cn.bing.com/search',params = url_params)
>>> print(r.url)
https://cn.bing.com/search?q=gloryroad
响应的内容:
r.encoding #获取当前的编码
r.encoding = ‘utf-8’ #设置编码
r.text #以encoding解析返回内容。字符串方式的响应体,会自动根据响应头部的字符编码进行解码
r.content #以字节形式(二进制)返回。字节方式的响应体,会自动为你解码gzip和defate压缩
r.header #以字典对象存储服务器响应头,但是这个字典比较特殊,字典键不区分大小写,若键不存在则返回None
r.status_code #响应状态码
r.raw #返回原始响应体,也就是urllib的response对象,使用r.raw.read()
r.ok #查看r.ok的布尔值可以知道是否登陆成功
#特殊方法#
r.json() #Requests中内置的JSON解码器,以json形式返回,前提返回的内容确保是json格式的,不然解析出错会抛异常
r.raise_for_status() #失败请求(非200响应)抛出异常
>>> type(r.text)
<class 'str'>
>>> type(r.content) #解码后的
<class 'bytes'>
>>> r.status_code
200
>>> r.raw
<urllib3.response.HTTPResponse object at 0x02C7F110>
>>> r.raw.read()
b''
>>> r.ok
True
>>> r.json
<bound method Response.json of <Response [200]>>
>>> r.raise_for_status()
>>>
>>> requests.get("http://httpbin.org/get?name=gemey&age=22")
<Response [200]>
>>> response = requests.get("http://httpbin.org/get?name=gemey&age=22")
>>> response.text
'{\n "args": {\n "age": "22", \n "name": "gemey"\n }, \n "headers": {\n
"Accept": "*/*", \n "Accept-Encoding": "gzip, deflate", \n "Host": "ht
tpbin.org", \n "User-Agent": "python-requests/2.19.1", \n "X-Amzn-Trace-Id
": "Root=1-5e4a0156-3abe8a28d1e5a3c87aa706c6"\n }, \n "origin": "113.132.8.37"
, \n "url": "http://httpbin.org/get?name=gemey&age=22"\n}\n'
>>> data ={'name':'tom','age':20}
>>> response = requests.get("http://httpbin.org/get",params=data)
>>> response.url
'http://httpbin.org/get?name=tom&age=20'
>>> data ={'name':'tom','age':28}
>>> response = requests.post("http://httpbin.org/post",params=data)
>>> response.text
'{\n "args": {\n "age": "28", \n "name": "tom"\n }, \n "data": "", \n
"files": {}, \n "form": {}, \n "headers": {\n "Accept": "*/*", \n "Accep
t-Encoding": "gzip, deflate", \n "Content-Length": "0", \n "Host": "httpbi
n.org", \n "User-Agent": "python-requests/2.19.1", \n "X-Amzn-Trace-Id": "
Root=1-5e4a0a94-c1ea24a77596c462f3372956"\n }, \n "json": null, \n "origin":
"113.132.8.37", \n "url": "http://httpbin.org/post?name=tom&age=28"\n}\n'
>>>
>>> session = requests.Session()
>>> session.get('http://httpbin.org/cookies/set/number/12345')
<Response [200]>
>>> session.get('http://httpbin.org/cookies')
<Response [200]>
>>> result = session.get('http://httpbin.org/cookies')
>>> result.text
'{\n "cookies": {\n "number": "12345"\n }\n}\n'
cookie和session的区别:
cookie存在客户端,是明文保存的,一般有有效期,会对应不同域名,对应不同域名下的不同目录。可以保存认证信息,也可以不保存,可以被浏览器禁止,cookie关闭了,session就不能使用了,如果还想使用session,在url里面加sessionid=xxx,明文的sessionid被别人拿到会暴露你的登录状态是不安全的。
session存在服务器端,通常是用于保存认证信息。
持续保持同一会话(使用相同的cookie)
#coding:utf-8
import requests
session = requests.Session()#保持同一会话的核心
session.get('http://httpbin.org/cookies/set/number/12345')
response = session.get('http://httpbin.org/cookies')
print(response.text)
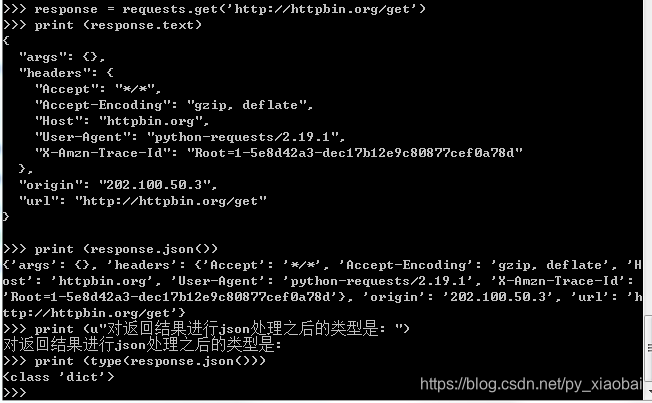
返回json格式结果处理
#coding:utf-8
import requests
response = requests.get('http://httpbin.org/get')
print (response.text) #返回的是Unicode型的数据
print (response.json()) #response.json()方法同json.loads(response.text)
print (u"对返回结果进行json处理之后的类型是: ")
print (type(response.json()))
服务返回结果用法
#coding:utf-8
import requests
response = requests.get('http://www.baidu.com')
print (response.status_code) # 打印状态码
print (response.url) # 打印请求url
print (response.headers) # 打印头信息
print (response.cookies) # 打印cookie信息
print (response.text) #以文本形式打印网页源码
print (response.content) #以字节流形式打印
超时异常
import urllib.request
response=urllib.request.urlopen('http://httpbin.org/get',timeout=0.1) #设置超时时间为0.1秒,将抛出异常
print(response.read())
#运行结果
#urllib.error.URLError: <urlopen error timed out>
import urllib.request
from urllib import error
import socket
try:
response=urllib.request.urlopen('http://httpbin.org/get',timeout=0.1)
print(response.read())
except error.URLError as e:
if isinstance(e.reason, socket.timeout): # 判断对象是否为类的实例
print(e.reason) # 返回错误信息
#运行结果
#timed out
Urllib
urllib是python内置的HTTP请求库,无需安装即可使用,它包含了4个模块:
request:它是最基本的http请求模块,用来模拟发送请求
error:异常处理模块,如果出现错误可以捕获这些异常
parse:一个工具模块,提供了许多URL处理方法,如:拆分、解析、合并等
robotparser:主要用来识别网站的robots.txt文件,然后判断哪些网站可以爬
Urllib2:(python3以后已经合并成了urllib库)
python 3.x中urllib库和urilib2库合并成了urllib库。。
其中urllib2.urlopen()变成了urllib.request.urlopen()
urllib2.Request()变成了urllib.request.Request()
小知识:
嵌套的字典怎么取想要的值。
比如想取{“datas”:{“lines”:{“code”:“00”}},“data1”:{“line1”:{“code”:“00”}}}这个字典的第一个code对应的键值对。用
{“datas.lines.code”:“00”}
>>> {"datas":{"lines":{"code":"00"}},"data1":{"line1":{"code":"00"}}}
{'datas': {'lines': {'code': '00'}}, 'data1': {'line1': {'code': '00'}}}
>>>
>>> {"datas.lines.code":"00"}
{'datas.lines.code': '00'}
关联的接口数据依赖处理格式:
REQUEST_DATA = {“register->1->username”:“zhangsan”}
{“request”:
["response->register->1->username,“register->1->password”]
}
{“request”:
{“username”:“register->1”,“password”:“register->1”}
}
{
“request”:[“username”,“password”],
“response”:[“code”,“userid”]
}
{“register”:{“1”:{‘userid’:48},
“2”:{“userid”:50}}
}

















 910
910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









