




 本文探讨了多种优化卷积神经网络(CNN)在图像分类任务中的表现的策略,包括Nesterov加速梯度、大批次训练、低精度训练、ResNet结构改进、余弦学习率衰减、标签平滑及知识蒸馏等方法。
本文探讨了多种优化卷积神经网络(CNN)在图像分类任务中的表现的策略,包括Nesterov加速梯度、大批次训练、低精度训练、ResNet结构改进、余弦学习率衰减、标签平滑及知识蒸馏等方法。
论文地址:Bag of Tricks for Image Classification with Convolutional Neural Networks
这篇文章提出了一些分类网络的小trick
1、Optimizer
Nesterov Accelerated Gradient (NAG)
Y. E. Nesterov. A method for solving the convex programming problem with convergence rate o (1/kˆ 2). In Dokl.Akad. Nauk SSSR, volume 269, pages 543–547, 1983. 2
2、large batch
文章中提出,large batch能够提高训练效果,但是会降低训练速度
Linear scaling learning rate:线性调整学习率
learning rate warmup:在训练开始时,进行学习率的wramup,先让学习率从小增大到1,已稳定学习,稳定后,再将学习率减少,优化学习
zero y:将resblock中的batch norm中的参数y初始化为0
no bias decay:
3、low-precision training
将网络中的tensor数据类型从float32修改为float16,降低数据精度,但不会损失网络准确率
4、resnet architecture
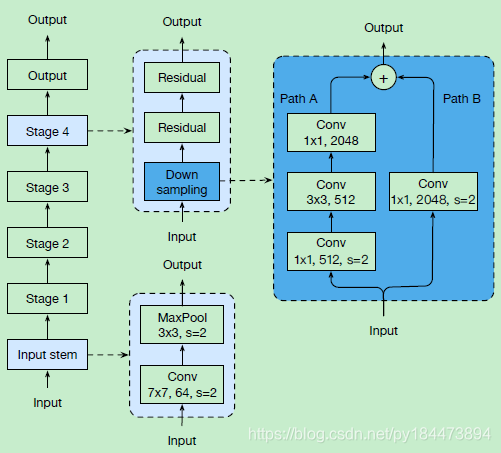
上图为原始的resnet,称为resnet-A,蓝线中为一个原始res down sampling block
可以看到下采样是使用1*1卷积操作的,但是stride=2的1*1卷积会损失掉原始feature map的四分之三的数据
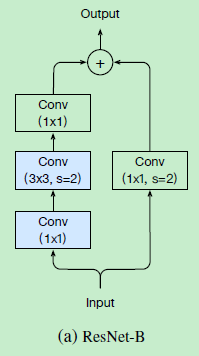
所以就想要把这点进行改进,将stride=2的卷积更换为3*3的进行,就成为了resnet-B,如下图所示
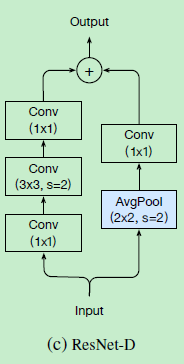
本文呢,看到skip-conn还依然使用了stride=2的1*1卷积,依然会损失四分之三的数据,然后本文就再这个1*1卷积之前,加入了一个stride=2的avgpool,成为resnet-D,如下图所示
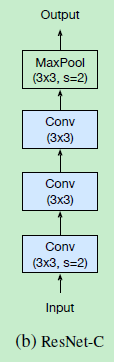
还有一种结构呢,就是原始的第一层下采样卷积是直接使用stride=2的7*7进行的,但是7*7卷积可以用两个2*2卷积代替,所以就提出了resnet-C结构,如下图所示
5、cosine learning rate decay
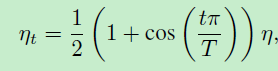 在warmup之后,使用该公式进行学习率的调整,n为初始学习率
在warmup之后,使用该公式进行学习率的调整,n为初始学习率
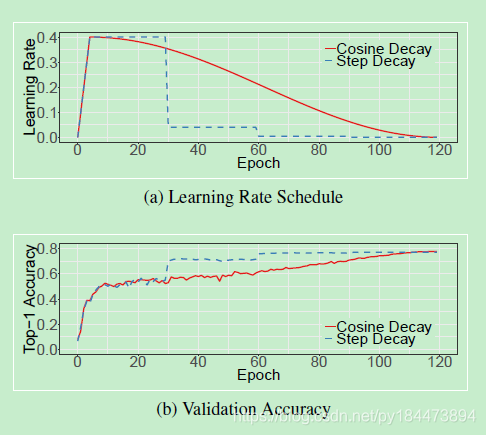
这是cosine decay与step decay的一个对比图
6、label smooth
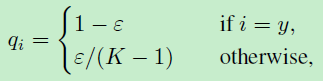 使用该公式代替原始的0,1label
使用该公式代替原始的0,1label
最终的交叉熵优化公式为
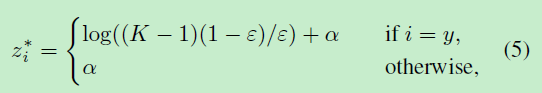
7、knowledge distillation
使用resnet-152作为teacher model,增加distillation loss在softmax的输出上进行teacher model和student model的penalize

















 3388
3388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









