




CPU或GPU的cache与芯片纳米级别和APP或服务性能之间的关系
目录
4.1、当cpu硬件无L1缓存时,开启缓存使用的是磁盘还是内存
4.2、IC芯片纳米级别与CPU或GPU的cache速度是什么关系
喜欢的,就收藏并点个赞,鼓励我继续技术的原创写作及经验分享:
1、引言
在购买和选用云服务器时,人们往往会忽视“L1缓存”、“L2缓存”、“L3缓存”或者是否CPU硬件存在“L1缓存”,而云平台的服务和运营商在销售产品时通常不会为你公开这种级别的参数。这导致了服务程序的运行性能的差异。
然而,开发人员往往也忽略了这种差异,从而导致服务的计算性能和并发性能的差异。
2、测试案例
服务程序向ms sql server数据库fetch请求(假设以不分页来替代分页并发)20*1024行记录,每行记录约10kb,共200M数据。
如果cpu有硬件缓存,在应用程序开启了cache及异步请求时,这些数据将在你觉察不到的时间内(毫秒级别,1秒以内)向你返回数据:
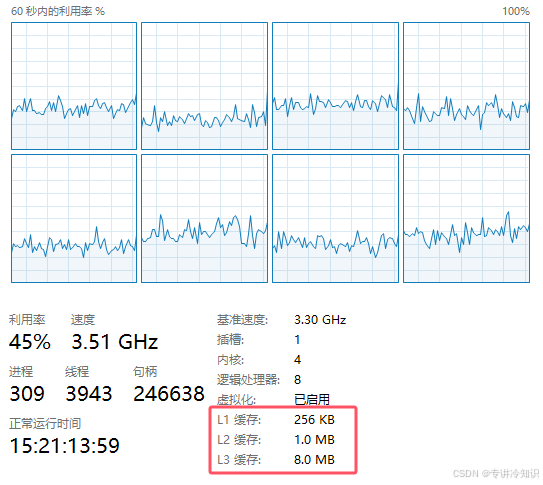
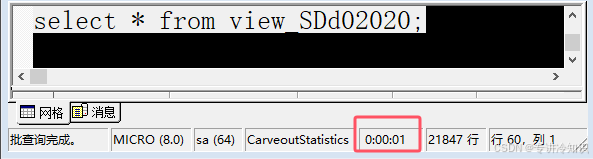
但是如果你的服务器是无cache缓存的,那么同样的数据,你的应用可能会在3~4秒内(秒级)从数据库平台获取到数据(其中数据库平台本身可能在1~3秒内拿到数据):
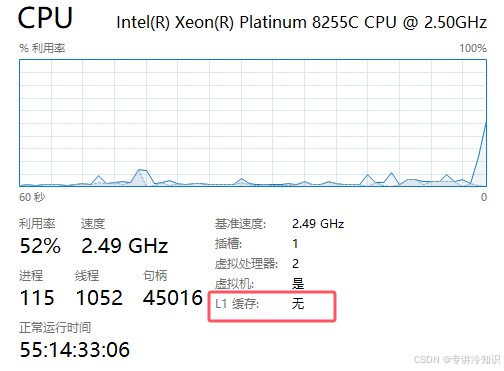
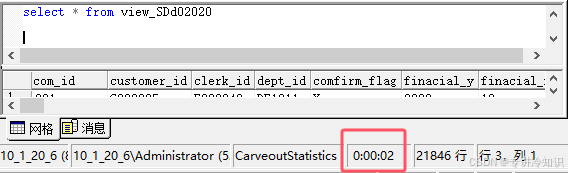
3、用户体验
这种微妙的差异,会严重影响客户端用户的体验,尤其在并发用户环境下。
并发用户越多,后面请求的用户就会进入请求队列,从而让用户感觉“一直在转圈等待”的状态。
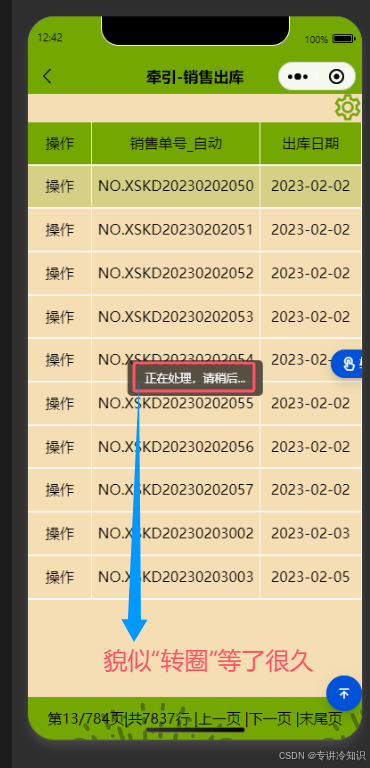
在软件的实际用户应用中,并非所有用户都能消费得起高配云服务器,所以,应用本身的优化及其重要,否则定会影响销售。
4、原理
4.1、当cpu硬件无L1缓存时,开启缓存使用的是磁盘还是内存
当CPU硬件无L1缓存时,CPU会直接使用内存来读取数据。L1缓存是CPU内部的一级缓存,用于存储访问最频繁的数据,以提高访问速度。当CPU没有L1缓存时,CPU会直接从内存中读取数据,因为内存的速度虽然比L1缓存慢,但仍然比硬盘(磁盘)快几个数量级。
4.1.1、CPU、内存和硬盘的速度对比
◆L1缓存:速度最快,通常访问时间在几个纳秒内。
◆内存:速度较慢,但仍然比硬盘快几个数量级,访问时间在几十到几百纳秒之间。
◆硬盘:速度最慢,访问时间在毫秒级别。
4.1.2、缓存的作用和重要性
缓存的主要作用是减少CPU访问主存的次数,从而加快数据访问速度。没有L1缓存时,CPU需要从更慢的内存中读取数据,这会导致访问速度变慢,影响整体性能。尽管如此,内存仍然比硬盘快得多,因此即使没有L1缓存,系统的整体性能仍然会比使用硬盘直接读取数据要好。
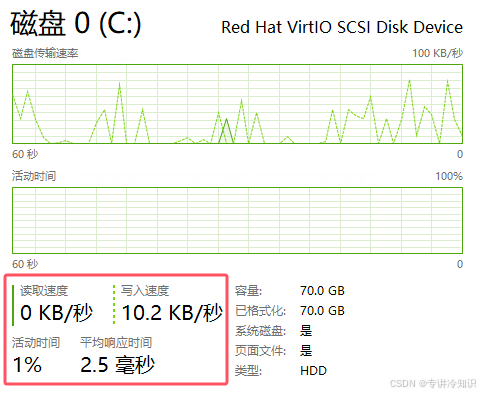
云服务器内存很昂贵,当内存耗尽,操作系统将会自动启用“磁盘缓存”,速度大打折扣:
4.2、IC芯片纳米级别与CPU或GPU的cache速度是什么关系
芯片纳米级别与CPU或GPU的cache速度之间存在密切关系,主要体现在以下几个方面:
首先,芯片的纳米级别技术直接影响CPU或GPU的cache速度。纳米级别的降低意味着晶体管尺寸的减小,这使得在相同面积上可以集成更多的晶体管和更小的电路,从而提升了芯片的集成度和处理速度。更小的晶体管尺寸可以减少信号延迟,提高数据传输速度,进而提升cache的访问速度和处理效率。
其次,cache的设计和实现也受到芯片纳米级别技术的影响。随着纳米级别的降低,制造工艺的进步使得cache的设计可以更加精细,能够在更小的空间内实现更高的存储密度和更快的访问速度。例如,现代CPU和GPU中的L1、L2、L3缓存就是基于这种技术实现的,它们分别负责不同的数据存储和访问速度,以满足不同的性能需求。
最后,芯片纳米级别技术的发展推动了cache技术的进步。随着工艺的不断进步,cache的制造工艺也在不断优化,能够在更小的空间内实现更高的存储密度和更快的访问速度。例如,2纳米及以下的芯片制程技术使得缺陷检测和制造变得更加复杂,但也为cache技术的进一步提升提供了可能。
4.3、开发服务器往往选择低配云服务器
开发服务器往往选择低配云服务器,以发现和规避“低性能障碍”的“坑”。
5、解决之道
若为低配CPU云服务器,则请注意:
5.1、服务端应用
◆若启用cache,应合理设置其buffer数值;
cache开得越大,意味着内存buffer就越大,并发内存的消耗就越大;同时需要获取数据并回应客户端后,尽快代码“被动释放内存”的耗用,否则会被“系统主动释放内存”耗用,通常在同一个api被再次请求之前,它会一直“持有内存”。
◆勿“同步请求”和“同步计算”,改用“异步模式”;
◆内存不够用的情形,尽量避免“多核多线程”带来的磁盘I/O开销,而改用“单核心”队列模式,以避免并发死机;
◆合理设置和运用“网络超时”;
◆若需与三方应用服务(比如数据库平台服务)交互,注意“分页请求”等技术;
◆若需与数据库平台服务交互,注意尽量使用“存储过程”技术而非直接使用select语句;
“存储过程”的特点是:
●首次执行慢。因为它需要完成一次内部编译。
●后续能被内部缓存,执行快数量级。一次编译,后续复用。
●一旦执行一次“无条件查询”,所有数据均被缓存。后续查询,只是查询条件对它的“过滤”。
●能被来自并发客户端所“共享缓存”。
换句话说,并非每个客户端请求都从新编译或重新占用一次内存或磁盘的缓存。
●“共享缓存”一直存在,除非重启数据库服务或重启操作系统。
◆“分布式应用服务”:尽量使用http技术实现分布式,而非直接使用socket访问数据库;
换句话说,尽量使每个分布式节点中,分布式应用服务与数据库服务在同一台云服务器设备中,而让分布式应用服务之间通过http技术请求和响应。调度服务仅仅向客户端回复请求指向令牌Token,调度服务相当于一个负载均衡器和Token代理,客户端根据Token去请求分布式节点应用服务。
直接socket访问数据库,会带来诸如sql注入等安全开销和tcp持久连接的并发性能开销等技术层面的麻烦处理。
5.2、客户端应用
◆严格控制“并发请求”,无论http还是socket;
◆控制“分页请求”包的大小(即分页size);
◆使用“流技术”分片请求大包(1M以上的包),比如大的多媒体数据 。
喜欢的,就收藏并点个赞,鼓励我继续技术的原创写作及经验分享:
论提升人机交互设计体验之-浏览器Disk Cache磁盘缓存及其协商缓存、及原生App和浏览器实现缓存的差异-优快云博客
多线程并发http任务的设计_maxconnectionsperserver-优快云博客
浅谈服务器http并发数的影响因素_服务器最大能同时支持多少个请求跟什么有关-优快云博客
微信小程序scroll-view吸顶css样式化表格的表头及iOS上下滑动表头的颜色覆盖、z-index应用及性能分析_微信小程序吸顶-优快云博客


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











