




 本文深入探讨了BeyondPartModels论文中的两大创新:PCB网络和RPP方法。PCB通过修改ResNet结构,引入更精细的部位划分,而RPP则优化了平均池化过程,解决了均匀分割中的异常值问题,实现更准确的人体部位特征提取。
本文深入探讨了BeyondPartModels论文中的两大创新:PCB网络和RPP方法。PCB通过修改ResNet结构,引入更精细的部位划分,而RPP则优化了平均池化过程,解决了均匀分割中的异常值问题,实现更准确的人体部位特征提取。
论文名称:Beyond Part Models Person Retrieval with Refined Part Pooling
预备知识:关于outlier和inlier
https://blog.youkuaiyun.com/daigualu/article/details/73866250
懒得翻译了。。先说说梗概,此文章两个贡献,第一个是PCB网络(Part Level Basline),第二个是RPP方法(Refined Part Pooling)
先说PCB,结构如下图,backbone网络取的是ResNet(在试了许多网络以后),相当于ResNet稍微更改了几个部分
更改的部分有:1.把averge pooling改成了RPP方法,2.结尾的下采样rate改小了(实验证明更好),3.最后的分类器没有共享权值(实验证明更好),4.卷积出来的tensorT(如图)被分为6个部分(作者说实验证明6个部分效果最好)
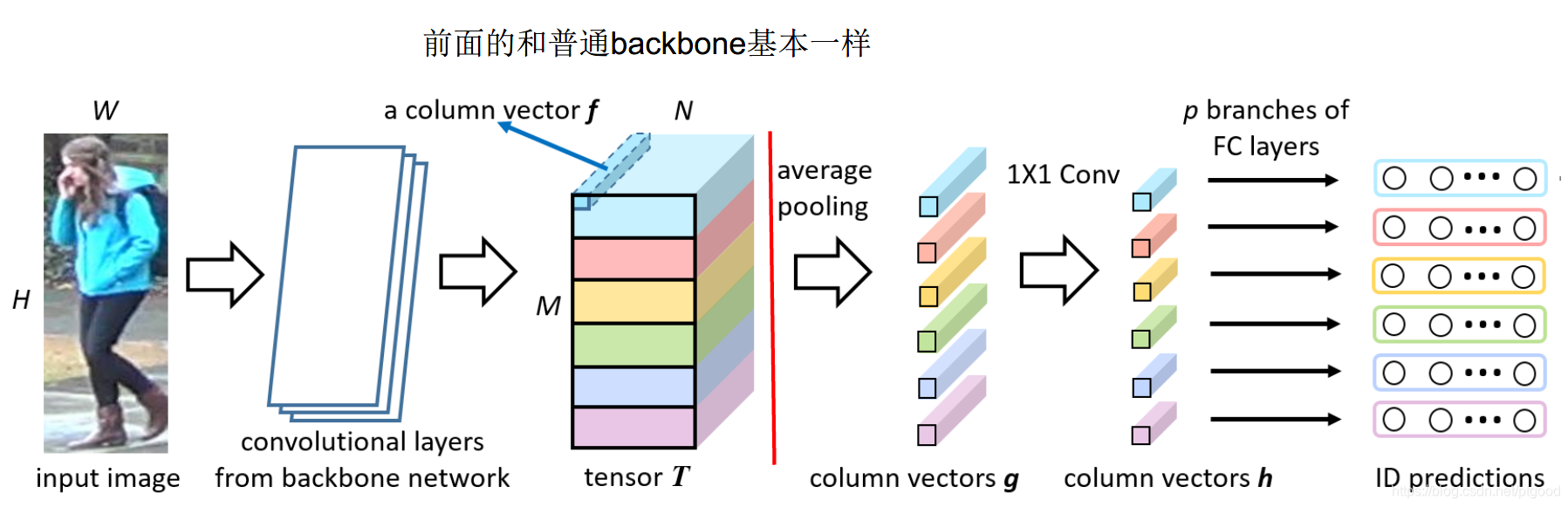
说说RPP,RPP是解决uniform partition会有outlier值的,或者说解决partition不精确的问题,也使得原本的粗暴分割加上变成'soft partition',出来的效果是这样子的
具体做法是把原来的AP(averge pooling)替换为RPP,用softmax分类器,预测T内的每个特征column在部位Parti上的概率
P(Parti | f)的大小。最终每个部位的采样是从全部列向量f(column vector)乘以权重P(也就是前面说的在部位Part上的概率大小)来计算的,
2019年1月11日10:38:20,正在看代码。后续把网络结构贴出来
以下是代码中PCB的结构,调用了torchvision.nn.models中的resnet50的结构,至于是否更改了resnet50的结构,还没看,下面这张图也没画完全,如下链接是解析pytorch中resnet结构,后续需要移植这个网络到其他地方
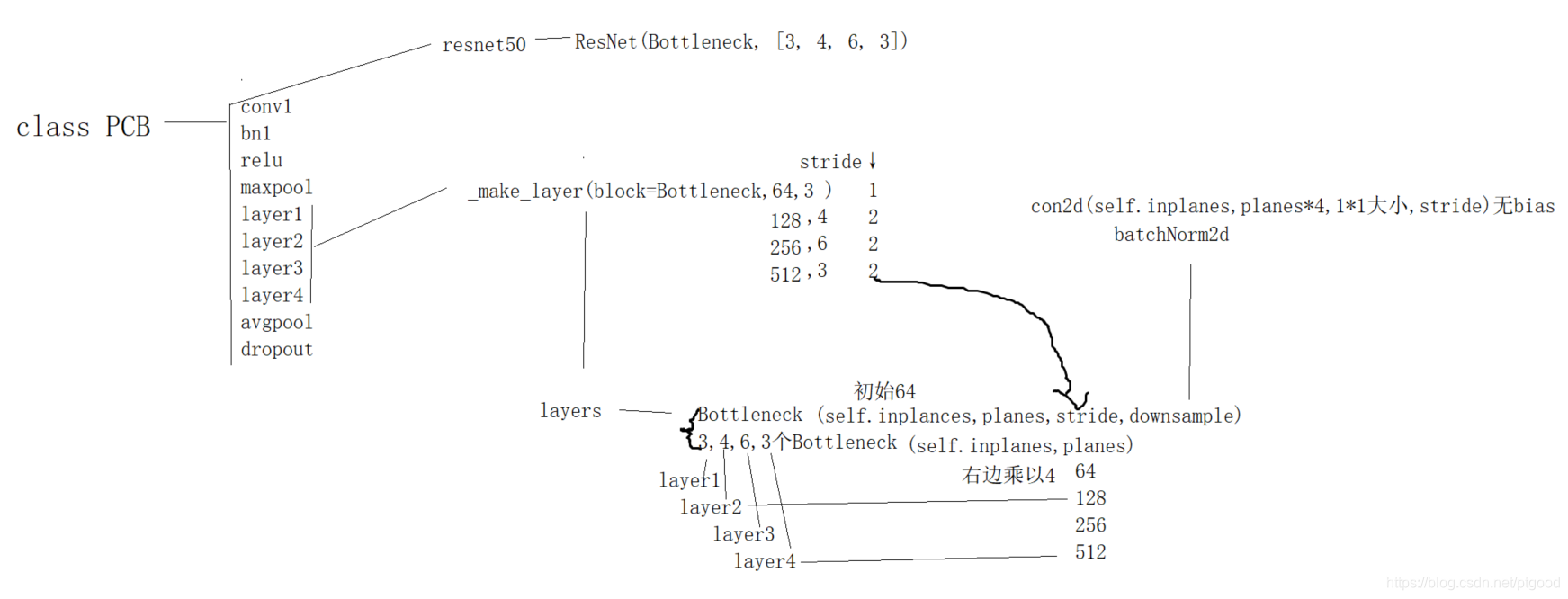
将Resnet网络更改成PCB结构在代码中的体现就是
class PCB(nn.Module):
def __init__(self, class_num ):
super(PCB, self).__init__()
self.part = 6 # We cut the pool5 to 6 parts
model_ft = models.resnet50(pretrained=True)
self.model = model_ft
#4.将averge pooling改成切分pooling成self.part=6块的特征g
self.avgpool = nn.AdaptiveAvgPool2d((self.part,1))#
self.dropout = nn.Dropout(p=0.5)
# 2.remove the final downsample
self.model.layer4[0].downsample[0].stride = (1,1)
self.model.layer4[0].conv2.stride = (1,1)
# 4.和3.define 6 classifiers,6个分类器,送给6个part使用
for i in range(self.part):
name = 'classifier'+str(i)
setattr(self, name, ClassBlock(2048, class_num, droprate=0.5, relu=False, bnorm=True, num_bottleneck=256))pytorch的resnet50大概封装成这样
def forward(self, x):
x = self.model.conv1(x)
x = self.model.bn1(x)
x = self.model.relu(x)
x = self.model.maxpool(x)
x = self.model.layer1(x)
x = self.model.layer2(x)
x = self.model.layer3(x)
x = self.model.layer4(x)至于resnet原本的结构:resnet50结构,emmm..pytorch中的resnet50实现把后面的几层封装成bottleneck,纯粹靠代码一层层阅读有点麻烦
还对训练和测试的网络差别弄不太懂:与训练的网络不同,PCB_test网络中没有dropout层,没有6个部位特征classifier

















 699
699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









