



传统方式:
按照文章的顺序查询关键字,这样的查询效率太低.
倒排索引:
根据关键字索引查询文章.
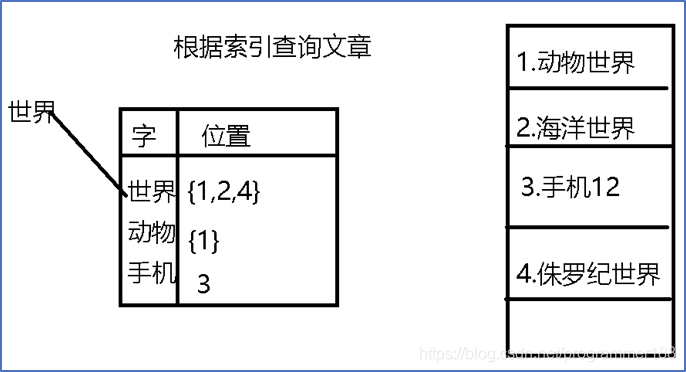
一、根据索引检索
- Lucene会为全部的文章根据中文分词器将文章进行分词处理.
- 之后为分词创建索引,保存到具体的索引文件夹中
- 根据倒排索引的概念,通过用户给定的关键字先匹配索引文件.之后根据全文检索,返回给用户所有满足条件的document
1.Directory directory //索引对象
2.Analyzer analyzer //中文分词器对象
3.IndexWriterConfig conf //输出配置文件对象
4.IndexWriter writer //索引输入对象
5.Document document //add各种标题文章
6.IndexSearcher indexSearcher //索引we
7.Query query
8.TopDocs docs
1=FSDirectory.open(new File(“./index”));
2=new IKAnalyzer(); //中文分词器对象
3=new IndexWriterConfig(Version.LUCENE_4_10_2,2);
4=1+3 //新建对象参数传入
4.addDocument(5);
6=new IndexSearcher(IndexReader.open(1));
7=new TermQuery(new Term("title", “标题”));
8=6.search(7,前十条记录);
for(ScoreDoc doc:8.scoreDocs){
int index = doc.doc;
5=6.doc(index);
//得到5可以进行get操作
}
二、spring整合solr
control类
1.String keyWord
2.DubboSearchService searchService
3.List<Item> itemList
4.Model model
1=new String(1.getBytes(“ISO-8859-1”),”UTF-8”);
3=2.findItemListByKey(1);
4.addAttribute(“itemList”,3);
4.addAttribute(“query”,1);
service类:
1.SolrQuery query //set入起始位置和每页行数
2.QueryResponse response
3.List<Item> itemList
2=httpSolrServer.query(1);
3=2.getBeans(Item.class);

















 912
912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









