




 本文探讨了深度学习中Batch Normalization的重要性,解释了Internal Covariate Shift问题及其对训练的影响。Batch Normalization通过在神经网络中引入可学习的归一化层,解决了训练速度慢和模型泛化能力下降的问题,允许使用更高的学习率和减少对dropout的依赖。此外,它还可以减少L2权重衰减系数并替代局部响应归一化层。
本文探讨了深度学习中Batch Normalization的重要性,解释了Internal Covariate Shift问题及其对训练的影响。Batch Normalization通过在神经网络中引入可学习的归一化层,解决了训练速度慢和模型泛化能力下降的问题,允许使用更高的学习率和减少对dropout的依赖。此外,它还可以减少L2权重衰减系数并替代局部响应归一化层。

关注微信公众号【Microstrong】,我现在研究方向是机器学习、深度学习,分享我在学习过程中的读书笔记!一起来学习,一起来交流,一起来进步吧!
本文同步更新在我的微信公众号中,公众号文章地址:https://mp.weixin.qq.com/s/o_Gwa11BauT60U7S1--3fQ
本文同步更新在我的知乎中:
深度学习中的Batch Normalization - Microstrong的文章 - 知乎https://zhuanlan.zhihu.com/p/36222443
1.为什么需要Batch Normalization
Batch Normalization就是在神经网络的训练过程中对每层的输入数据进行预处理。对输入数据预处理方法有很多,比如常用Z-score、白化等。
1.1 传统神经网络如何使用Normalization
传统的神经网络中,只是在输入层之前或在输出层之后对  进行标准化处理(减去均值,除标准差),让数据处于均值为0、方差为1的分布中,以降低样本间的差异性。过程如图1所示。
进行标准化处理(减去均值,除标准差),让数据处于均值为0、方差为1的分布中,以降低样本间的差异性。过程如图1所示。
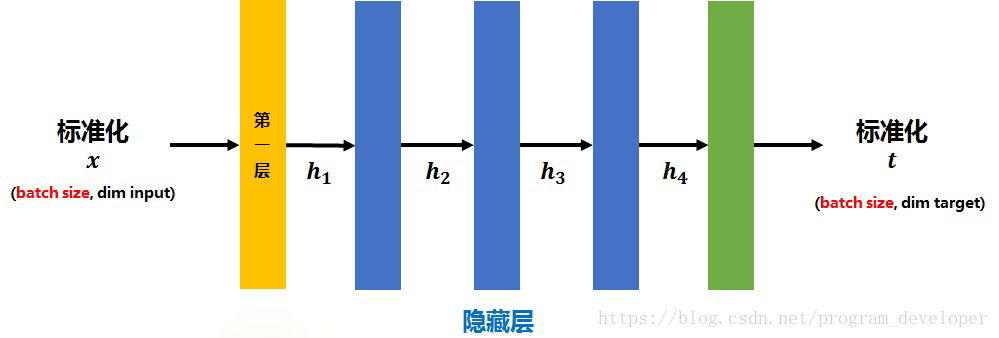
图1:传统网络的Normalization
思考一个问题:为什么传统的神经网络在训练开始之前,要对输入的数据做Normalization?
原因在于神经网络学习过程本质上是为了学习数据的分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另一方面,一旦在mini-batch梯度下降训练的时候,每批训练数据的分布不相同,那么网络就要在每次迭代的时候去学习以适应不同的分布,这样将会大大降低网络的训练速度,这也正是为什么我们需要对所有训练数据做一个Normalization预处理的原因。
那么传统神经网络中使用Normalization的缺点是什么呢?
对于深度网络的训练是一个复杂的过程,只要网络的前面几层参数发生微小的改变,那么后面几层网络就会被积累放大发生更大的变动。一旦网络某一层的输入数据的分布发生改变,那么这一层网络就需要去适应学习这个新的数据分布,所以如果训练数据的分布发生变化,那么将会影响网络的训练速度。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 604
604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









