




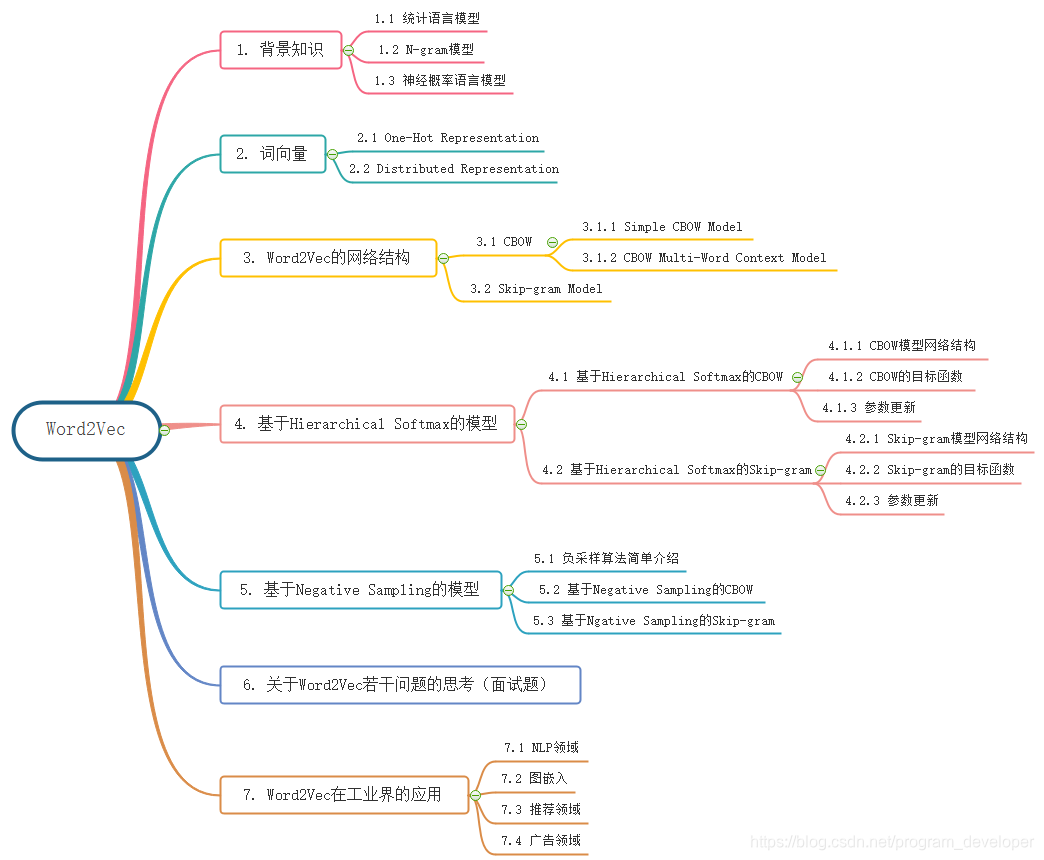
本文概览:
1. 背景知识
Word2Vec是语言模型中的一种,它是从大量文本预料中以无监督方式学习语义知识的模型,被广泛地应用于自然语言处理中。
Word2Vec是用来生成词向量的工具,而词向量与语言模型有着密切的关系。因此,我们先来了解一些语言模型方面的知识。
1.1 统计语言模型
统计语言模型是用来计算一个句子的概率的概率模型,它通常基于一个语料库来构建。那什么叫做一个句子的概率呢?假设 W=(w1,w2,...,wT)W = (w_{1}, w_{2}, ..., w_{T})W=(w1,w2,...,wT) 表示由TTT个词 w1,w2,...,wTw_{1},w_{2},...,w_{T}w1,w2,...,wT 按顺序构成的一个句子,则 w1,w2,...,wTw_{1},w_{2},...,w_{T}w1,w2,...,wT 的联合概率为:
p(W)=p(w1,w2,...,wT) p(W) = p(w_{1},w_{2},...,w_{T}) p(W)=p(w1,w2,...,wT)
p(W)p(W)p(W)被称为语言模型,即用来计算这个句子概率的模型。利用Bayes公式,上式可以被链式地分解为:
p(W)=p(w1)p(w2∣w1)p(w3∣w1,w2)...p(wT∣w1,w2,...,wT−1)(1) p(W) = p(w_{1})p(w_{2}|w_{1})p(w_{3}|w_{1},w_{2})...p(w_{T}|w_{1},w_{2},...,w_{T-1}) \tag{1} p(W)=p(w1)p(w2∣w1)p(w3∣w1,w2)...p(wT∣w1,w2,...,wT−1)(1)
其中的条件概率 p(w1),p(w2∣w1),...,p(wT∣w1,w2,...,wT−1)p(w_{1}),p(w_{2}|w_{1}),...,p(w_{T}|w_{1},w_{2},...,w_{T-1})p(w1),p(w2∣w1),...,p(wT∣w1,w2,...,wT−1) 就是语言模型的参数,若这些参数已经全部算得,那么给定一个句子WWW,就可以很快地计算出相应地概率p(W)p(W)p(W)了。
看起来好像很简单,是吧?但是,具体实现起来还是有点麻烦。例如,先来看看模型参数的个数。刚才是考虑一个给定的长度为T的句子,就需要计算T个参数。不防假设语料库对应词典DDD的大小(即词汇量)为NNN,那么,如果考虑长度为TTT的任意句子,理论上就有NTN^{T}NT种可能,而每种可能都要计算TTT个参数,总共就需要计算 TNTTN^{T}TNT 个参数。当然,这里只是简单估算,并没有考虑重复参数,但这个量级还是有点吓人。此外,这些概率计算好后,还得保存下来,因此,存储这些信息也需要很大的内存开销。
此外,这些参数如何计算呢?常见的方法有n-gram模型、决策树、最大熵模型、最大熵马尔可夫模型、条件随机场、神经网络等方法。本文只讨论n-gram模型和神经网络两种方法。
1.2 N-gram模型
考虑 p(wk∣w1,...,wk−1)p(w_{k}|w_{1},..., w_{k-1})p(wk∣w1,...,wk−1) 的近似计算。利用Bayes公式,有:
p(wk∣w1,...,wk−1)=p(w1,...,wk)p(w1,...,wk−1) p(w_{k}|w_{1},...,w_{k-1}) = \frac{p(w_{1},...,w_{k})}{p(w_{1},...,w_{k-1})} p(wk∣w1,...,wk−1)=p(w1,...,wk−1)p(w1,...,wk)
根据大数定理,当语料库足够大时, p(wk∣w1,...,wk−1)p(w_{k}|w_{1},...,w_{k-1})p(wk∣w1,...,wk−1) 可以近似地表示为:
p(wk∣w1,...,wk−1)≈count(w1,...,wk)count(w1,...,wk−1)(2) p(w_{k}|w_{1},...,w_{k-1}) \approx \frac{count(w_{1},...,w_{k})}{count(w_{1},...,w_{k-1})} \tag{2} p(wk∣w1,...,wk−1)≈count(w1,...,wk−1)count(w1,...,wk)(2)
其中, count(w1,...,wk)count(w_{1},...,w_{k})count(w1,...,wk) 表示词串 w1,...,wkw_{1},...,w_{k}w1,...,wk 在语料中出现的次数, count(w1,...,wk−1)count(w_{1},...,w_{k-1})count(w1,...,wk−1) 表示词串 w1,...,wk−1w_{1},...,w_{k-1}w1,...,wk−1 在语料中出现的次数。可想而知,当kkk很大时, count(w1,...,wk)count(w_{1},...,w_{k})count(w1,...,wk) 和 count(w1,...,wk−1)count(w_{1},...,w_{k-1})count(w1,...,wk−1) 的统计将会多么的耗时。
从公式(1)可以看出:一个词出现的概率与它前面的所有词都相关。如果假定一个词出现的概率只与它前面固定数目的词相关呢?这就是n-gram模型的基本思想,它做了一个n−1n-1n−1阶的Markov假设,认为一个词出现的概率就只与它前面的n−1n-1n−1个词相关,即,
p(wk∣w1,...,wk−1)≈p(wk∣wk−n+1,...,wk−1) p(w_{k}|w_{1},...,w_{k-1}) \approx p(w_{k}|w_{k-n+1},...,w_{k-1}) p(wk∣w1,...,wk−1)≈p(wk∣wk−n+1,...,wk−1)
于是,公式(2)就变成了
p(wk∣w1,...,wk−1)≈count(wk−n+1,...,wk)count(wk−n+1,...,wk−1)(3) p(w_{k}|w_{1},...,w_{k-1}) \approx \frac{count(w_{k-n+1},...,w_{k})}{count(w_{k-n+1},...,w_{k-1})} \tag{3} p(wk∣w1,...,wk−1)≈count(wk−n+1,...,wk−1)count(wk−n+1,...,wk)(3)
以n=2n = 2n=2为例,就有
p(wk∣w1,...,wk−1)≈count(wk−1,...,wk)count(wk−1) p(w_{k}|w_{1},...,w_{k-1}) \approx \frac{count(w_{k-1},...,w_{k})}{count(w_{k-1})} p(wk∣w1,...,wk−1)≈count(wk−1)count(wk−1,...,wk)
这样简化,不仅使得单个参数的统计变得更容易(统计时需要匹配的词串更短),也使得参数的总数变少了。
那么,n-gram中的参数nnn取多大比较合适呢?一般来说,n的选取需要同时考虑计算复杂度和模型效果两个因素。
表1:模型参数数量与n的关系
| n | 模型参数的数量 |
|---|---|
| 1(unigram) | 2×1052 \times 10^{5}2×105 |
| 2(bigram) | 4×10104 \times 10^{10}4×1010 |
| 3(trigram) | 8×10158 \times 10^{15}8×1015 |
| 4(4-gram) | 16×102016 \times 10^{20}16×1020 |
在计算复杂度方面,表1给出了n-gram模型中模型参数数量随着nnn的逐渐增大而变化的情况,其中假定词典大小N=200000N=200000N=200000(汉语的词汇量大大致是这个量级)。事实上,模型参数的量级是NNN的指数函数( O(Nn)O(N^{n})O(Nn) ),显然nnn不能取得太大,实际应用中最多是采用n=3n=3n=3的三元模型。
在模型效果方面,理论上是nnn越大,效果越好。现如今,互联网的海量数据以及机器性能的提升使得计算更高阶的语言模型(如n>10n>10n>10)成为可能,但需要注意的是,当nnn大到一定程度时,模型效果的提升幅度会变小。例如,当nnn从111到222,再从222到333时,模型的效果上升显著,而从333到444时,效果的提升就不显著了(具体可以参考吴军在《数学之美》中的相关章节)。事实上,这里还涉及到一个可靠性和可区别性的问题,参数越多,可区别性越好,但同时单个参数的实例变少从而降低了可靠性,因此需要在可靠性和可区别性之间进行折中。
另外,n-gram模型中还有一个叫做平滑化的重要环节。回到公式(3),考虑两个问题:
- 若 count(wk−n+1,...,wk)=0count(w_{k-n+1},..., w_{k}) = 0count(wk−n+1,...,wk)=0 , 能否认为 p(wk∣w1,...,wk−1)p(w_{k} | w_{1},...,w_{k-1})p(wk∣w1,...,wk−1) 就等于000呢?
- 若 count(wk−n+1,...,wk)count(w_{k-n+1},..., w_{k})count(wk−n+1,...,wk) = count(wk−n+1,...,wk−1)count(w_{k-n+1}, ..., w_{k-1})count(wk−n+1,...,wk−1) ,能否认为 p(wk∣w1,...,wk−1)p(w_{k}|w_{1},...,w_{k-1})p(wk∣w1,...,wk−1) 就等于111呢?
显然不能,但这是一个无法回避的问题,哪怕你的预料库有多么大。平滑化技术就是用来处理这个问题的,这里不展开讨论。
总结起来,n-gram模型是这样一种模型,其主要工作是在语料中统计各种词串出现的次数以及平滑化处理。概率值计算好之后就存储起来,下次需要计算一个句子的概率时,只需找到相关的概率参数,将它们连乘起来就好了。
然而,在机器学习领域有一种通用的解决问题的方法:对所考虑的问题建模后先为其构造一个目标函数,然后对这个目标函数进行优化,从而求得一组最优的参数,最后利用这组最优参数对应的模型来进行预测。
对于统计语言模型而言,利用最大似然,可把目标函数设为:
∏w∈Cp(w∣Context(w)) \prod_{w \in C}^{} p(w|Context(w)) w∈C∏p(w∣Context(w))
其中,CCC表示语料(Corpus),Context(w)Context(w)Context(w)表示词www的上下文,即www周边的词的集合。当Context(w)Context(w)Context(w)为空时,就取 p(w∣Context(w))=p(w)p(w|Context(w))= p(w)p(w∣Context(w))=p(w) 。特别地,对于前面介绍的n-gram模型,就有 Context(wi=wi−n+1,...,wi−1)Context(w_{i} = w_{i-n+1},...,w_{i-1})Context(wi=wi−n+1,...,wi−1) 。
当然,实际应用中常采用最大对数似然,即把目标函数设为
L=∑w∈Clogp(w∣Context(w))(4) L = \sum_{w \in C}^{}{log p(w|Context(w))} \tag{4} L=w∈C∑logp(w∣Context(w))(4)
然后对这个函数进行最大化。
从公式(4)可见,概率 p(w∣Context(w))p(w|Context(w))p(w∣Context(w)) 已被视为关于www和Context(w)Context(w)Context(w)的函数,即:
p(w∣Context(w))=F(w,Context(w),θ) p(w|Context(w)) = F(w, Context(w), \theta) p(w∣Context(w))=F(w,Context(w),θ)
其中 θ\thetaθ 为待定参数集。这样一来,一旦对公式(4)进行优化得到最优参数集 θ∗\theta^{ *}θ∗ 后,FFF也就唯一被确定了,以后任何概率p(w∣Context(w))p(w|Context(w))p(w∣Context(w))就可以通过函数 F(w,Context(w),θ∗)F(w, Context(w), \theta^{ *})F(w,Context(w),θ∗) 来计算了。与n-gram相比,这种方法不需要事先计算并保存所有的概率值,而是通过直接计算来获取,且通选取合适的模型可使得 θ\thetaθ 中参数的个数远小于n-gram中模型参数的个数。
很显然,对于这样一种方法,最关键的地方就在于函数FFF的构建了。下一小节将介绍一种通过神经网络来构造FFF的方法。之所以特意介绍这个方法,是因为它可以视为Word2Vec中算法框架的前身或者说基础。
1.3 神经概率语言模型
本小节介绍 Bengio 等人于2003年在论文《A Neural Probabilistic Language Model》中提出的一种神经概率语言模型。该论文首次提出用神经网络来解决语言模型的问题,虽然在当时并没有得到太多的重视,却为后来深度学习在解决语言模型问题甚至很多别的nlp问题时奠定了坚实的基础,后人站在Yoshua Bengio的肩膀上,做出了更多的成就。包括Word2Vec的作者Tomas Mikolov在NNLM的基础上提出了RNNLM和后来的Word2Vec。文中也较早地提出将word表示一个低秩的向量,而不是One-Hot。word embedding作为一个language model的副产品,在后面的研究中起到了关键作用,为研究者提供了更加宽广的思路。值得注意的是Word2Vec的概念也是在该论文中提出的。
什么是词向量呢?简单来说就是,对词典DDD中的任意词www,指定一个固定长度的实值向量 v(w)∈ℜmv(w) \in \Re ^{m}v(w)∈ℜm , v(w)v(w)v(w) 就称为 www 的词向量,mmm为词向量的长度。关于词向量的进一步理解将放到下一节来讲解。
既然是神经概率语言模型,其中当然要用到神经网络了。 下图给出了神经网络的结构示意图。模型一共三层,第一层是映射层,将nnn个单词映射为对应word embeddings的拼接,其实这一层就是MLP的输入层;第二层是隐藏层,激活函数用tanhtanhtanh;第三层是输出层,因为是语言模型,需要根据前nnn个单词预测下一个单词,所以是一个多分类器,用SoftmaxSoftmaxSoftmax。整个模型最大的计算量集中在最后一层上,因为一般来说词汇表都很大,需要计算每个单词的条件概率,是整个模型的计算瓶颈。
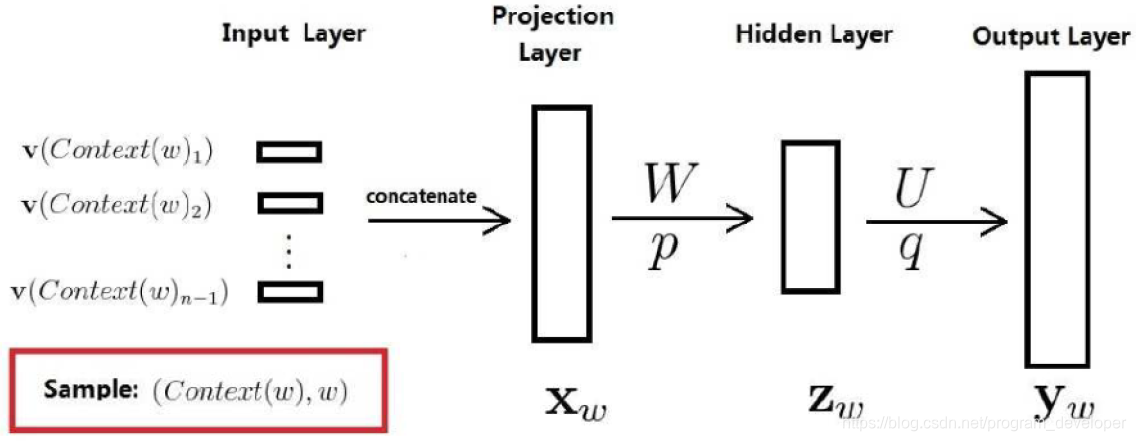
经过上面步骤的计算得到的 yw=(yw,1,yw,2,...,yw,N)Ty_{w} = (y_{w,1}, y_{w,2},...,y_{w,N})^{T}yw=(yw,1,yw,2,...,yw,N)T 只是一个长度为NNN的向量,其分量不能表示概率。如果想要 ywy_{w}yw 的分量 yw,iy_{w,i}yw,i 表示当上下文为 Context(w)Context(w)Context(w) 时下一个词恰为词点DDD中第iii个词的概率,则还需要做一个Softmax归一化,归一化后,$ p(w|Context(w))$ 就可以表示为:
p(w∣Context(w))=eyw,iw∑i=1Neyw,i(5) p(w|Context(w)) = \frac{e^{y_{w,i_{w}}}}{ \sum_{i=1}^{N}{e^{y_{w,i}}}} \tag{5} p(w∣Context(w))=∑i=1Neyw,ieyw,iw(5)
其中 iwi_{w}iw 表示词www在词典DDD中的索引。
这里,需要注意的是需要提前初始化一个word embedding矩阵,每一行表示一个单词的向量。词向量也是训练参数,在每次训练中进行更新。这里可以看出词向量是语言模型的一个副产物,因为语言模型本身的工作是为了估计给定的一句话有多像人类的话,但从后来的研究发现,语言模型成了一个非常好的工具。
Softmax是一个非常低效的处理方式,需要先计算每个单词的概率,并且还要计算指数,指数在计算机中都是用级数来近似的,计算复杂度很高,最后再做归一化处理。此后很多研究都针对这个问题进行了优化,比如层级softmax、softmax tree。
当然NNLM的效果在现在看来并不算什么,但对于后面的相关研究具有非常重要的意义。论文中的Future Work提到了用RNN来代替MLP作为模型可能会取得更好的效果,在后面Tomas Mikolov的博士论文中得到了验证,也就是后来的RNNLM。
与n-gram模型相比,神经概率语言模型有什么优势呢?主要有以下两点:
- 词语之间的相似性可以通过词向量来体现。
举例来说,如果某个(英语)语料中 S1="Adogisrunningintheroom"S_{1} = "A dog is running in the room"S1="Adogisrunningintheroom"出现了100001000010000次,而 S2="Acatisrunningintheroom"S_{2} ="A cat is running in the room"S2="
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 711
711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









