




数据库实战第二弹
目录
- 前言
- 准备实战数据库
- 进行查询语句实战
- 不熟的sql语句
前言
这是第二次进行数据库的实战演习,本次难度跟之前第一次的时候相比有一定的升级,之前是查单表,今天是双表联查。跟数据库实战第一弹一样的是,数据库内容均属虚构,如有雷同,纯属巧合。
准备实战数据库
#创建数据库work2
create database work2;
#选中数据库work2
use work2;
#创建employee员工表:
create table employee(emp_id int auto_increment primary key,
emp_name varchar(50),
age int,
dep_id int)engine = innodb,charset = 'utf8';
#创建department表
create table department(dep_id int,dep_name varchar(100));
#为employee表添加数据
insert into employee(emp_name,age,dep_id) values ('alan',19,200),('tom',26,201),('jack',30,201),('alice',24,202),('robin',40,200),('natasha',28,204);
#为department表添加数据
insert into department values (200,'hr'),(201,'it'), (202,'sale'),(203,'fd');
进行查询语句实战
- 查询所有人所在的部门名称
select A.emp_name as 姓名, B.dep_name as 部门 from employee as A join department as B on A.dep_id = B.dep_id;

- 查询tom在哪个部门上班
select A.emp_name as 姓名,B.dep_name as 部门 from employee as A left join department as B on A.dep_id=B.dep_id where A.emp_name="TOM";

- 查询哪些人在it部门办公
select A.emp_name as 姓名,B.dep_name as 部门 from employee as A join department as B on A.dep_id=B.dep_id where B.dep_name="it";

- 查询每个部门有多少个人
select count(A.emp_name) as 人数 ,B.dep_name as 部门 from employee as A join department as B on A.dep_id=B.dep_id group by dep_name;

- 查询哪个员工目前所在的部门还没有成立
select A.emp_name as 员工 ,B.dep_name as 部门 from employee as A left join department as B on A.dep_id=B.dep_id where B.dep_id is NULL;

- 查询哪个部门是没有员工的
select A.emp_name as 员工 ,B.dep_name as 部门 from employee as A right join department as B on A.dep_id=B.dep_id where A.emp_name is NULL; ;

- 查询每个部门员工的平均年龄
select avg(A.age) as 平均年龄 ,B.dep_name as 部门 from employee as A join department as B on A.dep_id=B.dep_id group by dep_name;
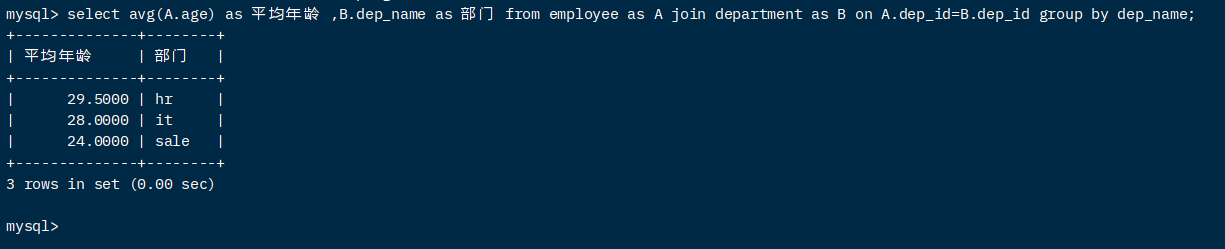
- 查询哪个部门的年龄总和最高
select sum(A.age) as 总和年龄 ,B.dep_name as 部门 from employee as A join department as B on A.dep_id=B.dep_id group by dep_name limit 1;

- 查询it部门年龄最小的员工是谁
select A.emp_name as 名字, A.age as 年龄 ,B.dep_name as 部门 from employee as A join department as B on A.dep_id=B.dep_id order by age limit 1;

不熟悉的sql语句
- left join &right join&join 的区别
- JOIN(即 INNER JOIN,内连接)
作用:只返回两个表中匹配条件的记录。
特点:只有当两个表中都存在符合连接条件(如 A.id = B.id)的记录时,才会被包含在结果中。
示例:
若员工表(A)和部门表(B)通过 dep_id 连接,内连接只会返回 “有对应部门的员工” 和 “有对应员工的部门”。 - LEFT JOIN(左连接,LEFT OUTER JOIN 的简写)
作用:以左侧表为基准,返回左侧表的所有记录,以及右侧表中匹配条件的记录。
特点:
若右侧表中没有匹配的记录,右侧表的字段会显示为 NULL。
左侧表的记录无论是否有匹配,都会被保留。
示例:
左连接员工表(左)和部门表(右)时,会返回 “所有员工”,包括那些 “没有对应部门” 的员工(部门字段为 NULL)。 - RIGHT JOIN(右连接,RIGHT OUTER JOIN 的简写)
作用:以右侧表为基准,返回右侧表的所有记录,以及左侧表中匹配条件的记录。
特点:
若左侧表中没有匹配的记录,左侧表的字段会显示为 NULL。
右侧表的记录无论是否有匹配,都会被保留。
示例:
右连接员工表(左)和部门表(右)时,会返回 “所有部门”,包括那些 “没有员工” 的部门(员工字段为 NULL)。
- JOIN(即 INNER JOIN,内连接)
| 连接类型 | 保留的记录 | 不匹配时的处理 |
|---|---|---|
| JOIN(内连接) | 两表中都匹配的记录 | 不匹配的记录全部排除 |
| LEFT JOIN | 左表所有记录 + 右表匹配的记录 | 右表不匹配的字段为 NULL |
| RIGHT JOIN | 右表所有记录 + 左表匹配的记录 | 左表不匹配的字段为 NULL |
可以简单理解为:内连接取 “交集”,左 / 右连接取 “左表 / 右表全部 + 交集”。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









