




在现代系统架构中,我们常常既希望:
- PostgreSQL 担任主数据存储;
- Redis 提供高速缓存;
- Elasticsearch 提供模糊搜索和全文索引。
但如何让这三者实时同步数据,既可靠又简单?
本文将带你从原理到实现,构建一个轻量级、高性能、可扩展的同步方案。
一、问题背景
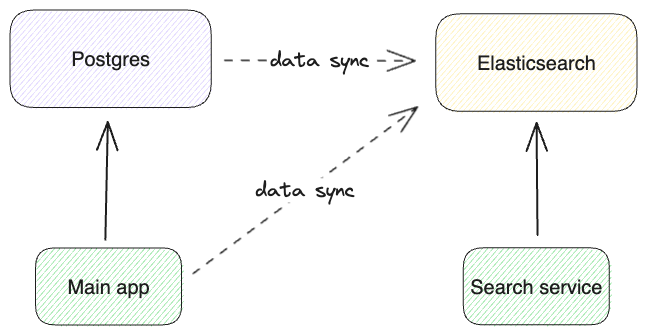
在中大型业务系统中,我们常见这样的三层数据结构:
| 系统 | 职责 | 特点 |
|---|---|---|
| PostgreSQL | 结构化主数据存储 | 强一致、可靠 |
| Redis | 高频访问缓存 | 高速读写 |
| Elasticsearch | 搜索/模糊查询 | 支持全文匹配、分词 |
理想状态下,当 PostgreSQL 中的数据发生变化时:
- Redis 缓存应立即更新;
- Elasticsearch 索引应保持一致。
但如果数据量大、变更频繁,人工同步或定时同步就会滞后。
这时我们需要一种轻量但实时的方案。
二、常见同步方案对比
| 方案 | 实时性 | 实现复杂度 | 运维成本 | 适用场景 |
|---|---|---|---|---|
| 定时扫描 + 更新时间字段 | 分钟级 | ⭐ | ⭐ | 简单系统 |
| Kafka / Debezium CDC | 毫秒级 | ⭐⭐⭐⭐ | ⭐⭐⭐ | 大型分布式系统 |
| Trigger + LISTEN/NOTIFY + Worker | 秒级 | ⭐⭐ | ⭐⭐ | ✅ 中小系统首选 |
📌 本文选用第三种方案:
PostgreSQL Trigger + LISTEN/NOTIFY + 异步 Worker 实时同步
它无需额外组件,延迟可低至 1 秒以内,兼顾可靠性与简洁性。
三、系统架构设计
同步流程如下图所示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2737
2737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











