






本文将详细介绍ES索引管理相关的API。
ES索引管理API主要包含如下API:
- Create Index
创建索引。 - Delete Index
删除索引。 - Get index
获取索引。 - indices Exists Index
判断索引是否存在 - Open/Close Index
打开或关闭索引,使用close index api会使索引处于关闭状态,此时无法对该索引进行读、写,但索引数据不会被删除。 - Shrink Index
收缩索引。收缩索引API允许您将现有索引收缩为具有较少主碎片的新索引(下文为们称之为目标索引)。伸缩后的索引主分片的个数必须是原分片的公约数,举例说明,如果原先索引的个数为15,那伸缩后的索引主分片数量可以是3、5、1。 - Split Index
拆分索引。将一个索引的主分片个数扩容,详情下文讲解。 - Rollover Index
翻转索引,有点类似于log4j记录日志的方式,例如,按日志文件大小超过多少后,创建一个新的文件一样。
1、创建索引
创建索引,通常创建索引API包含3个部分:索引配置、索引映射、索引别名,例如:
PUT test
{
"settings" : { //@1
"number_of_shards" : 1
},
"mappings" : { // @2
"_doc" : {
"properties" : {
"field1" : { "type" : "text" }
}
}
},
"aliases" : { // @3
"alias_1" : {},
"alias_2" : {
"filter" : {
"term" : {"user" : "kimchy" }
},
"routing" : "kimchy"
}
}
}
代码@1:索引的配置属性。请详细参考如下博文:
代码@2:定义映射,有点类似于关系型数据库中的定义表结构,详情请参考:映射参数详解、映射字段类型。
代码@3:为索引指定别名设置。
对应的JAVA示例代码:
public static void createSuggestMapping() {
RestHighLevelClient client = EsClient.getClient();
try {
CreateIndexRequest request = new CreateIndexRequest("suggest_mapping_001");
XContentBuilder jsonBuilder = XContentFactory.jsonBuilder()
.startObject()
.startObject("properties")
.startObject("context")
.field("type", "text")
.field("analyzer", "ik_smart")
.field("search_analyzer", "ik_smart")
.endObject()
.endObject()
.endObject();
request.mapping("_doc", jsonBuilder);
System.out.println(client.indices().create(request, RequestOptions.DEFAULT));
} catch (Throwable e) {
e.printStackTrace();
} finally {
EsClient.close(client);
}
}
2、查找/删除/打开/关闭索引
查找、删除、打开与关闭索引的使用方法与创建索引类似,都是通过RestHighLevelClient#indices()对应的方法来实现。
2.1 类图
接下来从Request类图入手,展示上述API重点的参数。

-
MasterNodeReadRequest
masterNodeTimeout:查找、连接masterNode的超时时间,默认为30s。 -
AcknowledgedRequest
ackTimeout、timeout:请求超时时间。 -
DeleteIndexRequest、GetIndexRequest、OpenIndexRequest、CLoseIndexRequest公共属性:
1、private String[] indices
上述API待操作的索引,即可以同时删除、查找、打开或关闭多个索引。
2、private IndicesOptions indicesOptions
索引操作选项。
2.2 IndicesOptions(索引操作选项)
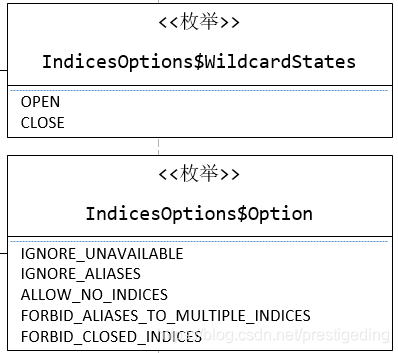
IndicesOptions$Option定义操作选项:
IndicesOptions$WildcardStates枚举类型主要定义通配符的作用范围,例如OPEN,表示处于打开状态的索引,而CLOSE表示处于关闭状态的索引。
IndicesOptions$Option定义操作选项:
- IGNORE_UNAVAILABLE
可忽略不可用的索引。 - IGNORE_ALIASES
忽略别名。 - ALLOW_NO_INDICES
允许索引不存在。 - FORBID_ALIASES_TO_MULTIPLE_INDICES
禁止操作多个索引或别名。 - FORBID_CLOSED_INDICES
禁止操作关闭状态的索引,如果有这个选项,则API只能对OPEN状态的索引进行操作。
IndicesOptions针对上面进行组合,默认给出了一些常量组合:
- STRICT_EXPAND_OPEN
(EnumSet.of(Option.ALLOW_NO_INDICES), EnumSet.of(WildcardStates.OPEN))
主要代表如下几层意义:
1、如果是指定索引,则索引必须存在。
2、通配符匹配的范围为OPEN状态的索引。
3、如果使用通配符来查找索引,未匹配到任何索引不会抛出异常。 - LENIENT_EXPAND_OPEN
(EnumSet.of(Option.ALLOW_NO_INDICES, Option.IGNORE_UNAVAILABLE), EnumSet.of(WildcardStates.OPEN))
主要代表如下几层意义:
1、允许索引不存在,指定一个不存在的索引,也不会抛出异常。
2、通配符作用范围为OPEN状态的索引。
3、如果使用通配符来查找索引,未匹配到任何索引不会抛出异常。 - STRICT_EXPAND_OPEN_CLOSED
(EnumSet.of(Option.ALLOW_NO_INDICES), EnumSet.of(WildcardStates.OPEN, WildcardStates.CLOSED))
主要代表如下几层意义:
1、如果指定索引,该索引必须存在。
2、通配符作用范围为OPEN、CLOSED状态的索引。
3、如果使用通配符来查找索引,未匹配到任何索引不会抛出异常。 - STRICT_EXPAND_OPEN_FORBID_CLOSED
(EnumSet.of(Option.ALLOW_NO_INDICES, Option.FORBID_CLOSED_INDICES), EnumSet.of(WildcardStates.OPEN))
主要代表如下几层意义:
1、如果指定索引,该索引必须存在。
2、通配符作用范围为OPEN状态的索引。
3、如果使用通配符查找索引,未找到索引不会抛出异常。
4、禁止指定CLOSE状态的索引。 [6.4.0版本测试,这条规则未生效] - STRICT_SINGLE_INDEX_NO_EXPAND_FORBID_CLOSED
(EnumSet.of(Option.FORBID_ALIASES_TO_MULTIPLE_INDICES, Option.FORBID_CLOSED_INDICES), EnumSet.noneOf(WildcardStates.class))。
主要代表如下几层意义:
1、指定的索引或别名必须存在。
2、不允许使用通配符。
3、不允许一个别名解析出多个索引的情况。
上面是对IndicesOptions中的枚举类型与默认定义的索引选项进行了一个说明,当然也可以通过IndicesOptions#fromOptions来自定义。
2.3 Java示例
删除、打开、查找,关闭等API的使用类似,下面给出一个简单的JAVA示例:
public static final void testGetIndex() {
RestHighLevelClient client = EsClient.getClient();
try {
GetIndexRequest request = new GetIndexRequest();
request.indices("suggest_mapping_001*")
//.indicesOptions(IndicesOptions.STRICT_EXPAND_OPEN)
//.indicesOptions(IndicesOptions.STRICT_SINGLE_INDEX_NO_EXPAND_FORBID_CLOSED)
//.indicesOptions(IndicesOptions.LENIENT_EXPAND_OPEN)
//.includeDefaults(true) 是否输出包含默认配置(settings),默认为false
// .indicesOptions(IndicesOptions.STRICT_EXPAND_OPEN_FORBID_CLOSED)
.indicesOptions(IndicesOptions.STRICT_SINGLE_INDEX_NO_EXPAND_FORBID_CLOSED)
;
System.out.println(client.indices().get(request, RequestOptions.DEFAULT));
} catch (Throwable e) {
e.printStackTrace();
} finally {
EsClient.close(client);
}
}
3、伸缩与拆分索引
Split Index,拆分索引。
3.1 Shrink Index
收缩索引。收缩索引API允许您将现有索引收缩为具有较少主碎片的新索引(下文为们称之为目标索引)。伸缩后的索引主分片的个数必须是原分片的公约数,举例说明,如果原先索引的个数为15,那伸缩后的索引主分片数量可以是3、5、1。
索引收缩过程:
- 首先,它创建一个新的目标索引,其定义与源索引相同,但是主碎片的数量更少。
- 然后它将段从源索引硬链接到目标索引。如果文件系统不支持硬链接,那么所有段都会复制到新索引中,这是一个非常耗时的过程。
- 然后恢复目标索引,使其能正常工作。
收缩索引前置条件:
- 设置索引为只读。
- 将待收缩索引(Source Index)的所有主分片与副本分片重定向到一个节点上
- 集群的状态为:green。
首先使用如下API更新源索引的配置信息(settings):
PUT /my_source_index/_settings
{
"settings": {
"index.routing.allocation.require._name": "shrink_node_name", // @1
"index.blocks.write": true // @2
}
}
代码@1:index.routing.allocation.require._name:强制将索引下所有的副本转移到指定名称(node.name)。
代码@2:设置该索引数据只读,无法再添加新的索引数据,但可以改变索引元数据。
注意:此过程可能需要一段时间,可以通过(_cat recovery api)或cluster health API查看其进度。
Shrink API使用示例:
POST my_source_index/_shrink/my_target_index?copy_settings=true
{
"settings": {
"index.routing.allocation.require._name": null, // @1
"index.blocks.write": null // @2
}
}
这里要特别注意,由于在收缩之前,改变了原索引的相关配置,收缩后的索引,需要恢复这些配置。
对应的JAVA示例:
public static final void testShrinkIndex() {
RestHighLevelClient client = EsClient.getClient();
try {
Map settings = new HashMap();
settings.put("index.routing.allocation.require._name", null);
settings.put("index.blocks.write", false);
ResizeRequest resizeRequest = new ResizeRequest("targetIndex", "sourceIndex");
resizeRequest.setCopySettings(true);
resizeRequest.getTargetIndexRequest().settings(settings);
ResizeResponse result = client.indices().shrink(resizeRequest, RequestOptions.DEFAULT);
System.out.println(result);
} catch (Throwable e) {
e.printStackTrace();
} finally {
EsClient.close(client);
}
}
上面的请求,只要目标索引在集群中配置,立即胡返回,不会等到收缩完成。
收缩索引的必要条件如下:
- 目标索引必须不存在。
- 源索引必须具有比目标索引更多的主分片数量。
- 目标索引中的主分片数量必须是源索引中的主分片数量的一个公因子。
- 索引不能包含超过2,147,483,519个文档,因为这是一个碎片中可以容纳的最大文档数量。
- 处理收缩过程的节点必须有足够的空闲磁盘空间来容纳现有索引的第二个副本。
索引收缩是可以通过_cat recovery api和cluster health api来监控shrink的过程,这两个命令将在后续文章中详解。
收缩索引由于需要创建索引,故支持wait_for_active_shards参数。
3.2 Split Index
拆分索引。
注意:在elasticsearch7.0版本之前,如果将来需要使用split api拆分索引,那么需要在创建索引的时候指定number_of_routing_shards参数,方便日后进行索引的拆分。
number_of_routing_shards用来指定指定内部用于跨具有一致哈希的分片分发文档的哈希空间。例如,一个拥有5个主分片的索引,其number_of_routing_shards设置为30 (5 x 2 x 3)的5切分索引可以除以2或3的因数,其拆分方式如下:
- 5 → 10 → 30 (split by 2, then by 3)
- 5 → 15 → 30 (split by 3, then by 2)
- 5 → 30 (split by 6)
索引拆分过程
- 首先,它创建一个新的目标索引,其定义与源索引相同,但主分片数量增大。
- 然后它将段从源索引硬链接到目标索引。(如果文件系统不支持硬链接,那么所有段都会复制到新索引中,这是一个非常耗时的过程。)
- 一旦创建了底层文件,所有文档将再次散列,以删除属于不同切分的文档。
- 最后恢复目标索引,使该索引可用。
拆分索引前置条件:
- 设置索引为只读。
其对应的API:
PUT /my_source_index/_settings
{
"settings": {
"index.blocks.write": true // 设置原索引只读
}
}
然后使用Split Index拆分索引。
POST my_source_index/_split/my_target_index?copy_settings=true
{
"settings": {
"index.number_of_shards": 2
}
}
其对应的JAVA代码:
@SuppressWarnings({ "rawtypes", "unchecked" })
public static final void testSplinkIndex() {
RestHighLevelClient client = EsClient.getClient();
try {
Map settings = new HashMap();
settings.put("index.number_of_shards", 2);
ResizeRequest resizeRequest = new ResizeRequest("targetIndex", "sourceIndex");
resizeRequest.setCopySettings(true);
resizeRequest.getTargetIndexRequest().settings(settings);
ResizeResponse result = client.indices().split(resizeRequest, RequestOptions.DEFAULT);
System.out.println(result);
} catch (Throwable e) {
e.printStackTrace();
} finally {
EsClient.close(client);
}
}
拆分索引的必要条件如下:
- 目标索引必须不存在。
- 索引的主分片个数必须少于目标索引。
- 目标索引中的主分片数量必须是源索引中的主分片数量的一个因子。
- 处理拆分过程的节点必须有足够的空闲磁盘空间来容纳现有索引的第二个副本。
拆分过程的监控与收缩索引相同,不重复介绍。
4、翻转索引
rollover index API,当认为现有索引太大或太旧时,可以使用rollover index API将别名滚到新索引。该API必须接收一个索引别名和一个条件列表(用来从老的索引中过滤需要迁移的文档)。根据别名指向索引的类别,别名元数据将以不同的方式更新。两种情况如下:
- alias只指向一个单一的索引(索引可写)
在这个场景中,原始索引的rollover别名将被添加到新创建的索引中,并从原始索引中删除。 - alias指向多个索引
一个别名指向多个索引时,其中一个会通过is_write_index =true来表示写索引。
在这个场景中,将原写索引is_write_index设置为false,而新创建的索引的is_write_index=true。
支持如下条件参数:
- max_age
索引年龄,从索引创建时间开始算起。 - max_docs
索引应该包含的最大文档数量。 - max_size
索引主分片最大大小。
示例:
step1:创建索引,并指定一个别名。
PUT /logs-000001
{
"aliases": {
"logs_write": {}
}
}
step2:向该索引中添加超过1000个文档。
# Add > 1000 documents to logs-000001
step3:rollover 索引
POST /logs_write/_rollover
{
"conditions": {
"max_age": "7d", // @1
"max_docs": 1000, // @2
"max_size": "5gb" // @3
}
}
代码@1:索引是否已创建7天。
代码@2:索引中包含的文档数量。
代码@3:索引的主分片大小。
4.1 索引命名
如果现有索引的名称以-和一个数字结束,例如logs-000001。然后,新索引的名称将遵循相同的模式,增加数字(log -000002)。无论旧索引名是什么,该数字都是零,长度为6。
如果原索引的名称不符合该格式,则需要手动指定新索引的名称。
POST /my_alias/_rollover/my_new_index_name
{
"conditions": {
"max_age": "7d",
"max_docs": 1000,
"max_size": "5gb"
}
}
4.2 date mesh方式
# PUT /<logs-{now/d}-1> with URI encoding:
PUT /%3Clogs-%7Bnow%2Fd%7D-1%3E // @1
{
"aliases": {
"logs_write": {}
}
}
PUT logs_write/_doc/1
{
"message": "a dummy log"
}
POST logs_write/_refresh
# Wait for a day to pass
POST /logs_write/_rollover // @2
{
"conditions": {
"max_docs": "1"
}
}
代码@1:使用date mesh格式定义新索引的格式。
代码@2:创建一个以今天的日期(例如)命名的索引log -2016.10.31-1:,转到具有今天日期的新索引,例如如果立即运行,log -2016.10.31-000002,如果24小时后运行,log -2016.11.01-000002。
4.3 dry_run模式
rollover API支持dry_run模式,在这种模式下,无需执行实际的翻转就可以检查请求条件。
4.4 Java示例
public static final void testRolloverIndex() {
RestHighLevelClient client = EsClient.getClient();
try {
// public RolloverRequest(String alias, String newIndexName)
RolloverRequest resizeRequest = new RolloverRequest("logs_write", null);
resizeRequest.addMaxIndexAgeCondition(TimeValue.parseTimeValue("7d", "max_age"));
resizeRequest.addMaxIndexDocsCondition(50);
resizeRequest.addMaxIndexSizeCondition(ByteSizeValue.parseBytesSizeValue("5G", "max_index_size"));
resizeRequest.dryRun(true);
RolloverResponse result = client.indices().rollover(resizeRequest, RequestOptions.DEFAULT);
System.out.println(result);
} catch (Throwable e) {
e.printStackTrace();
} finally {
EsClient.close(client);
}
}
在创建RolloverRequest时,newIndexName可以指定为空,新索引的命名遵循4.1、4.2中的规则。
本节详细介绍了索引管理相关的API,主要包括Index Create、Delete Index、Get index、indices Exists Index、Open/Close Index 、Shrink Index、Split Index、Rollover Index。有关于索引的更新,包括(映射Mapping、配置Settings)的更新比较简单,就不做介绍,下一节,我们重点探讨索引模板(Index Templates)。
见文如面,我是威哥,热衷于成体系剖析JAVA主流中间件,关注公众号『中间件兴趣圈』,回复专栏可获取成体系专栏导航,回复资料可以获取笔者的学习思维导图。



















 1239
1239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











