



基于执行器数据流模型和OpenMP的多核DSP HEVC解码器
摘要
视频编码是便携式多媒体终端中计算成本最高的应用之一。近年来,新的视频编码标准(如高效视频编码(HEVC))以及视频编解码器分辨率的不断提高,已经超出了嵌入式系统中单核处理器的处理能力。因此,当前的多媒体系统普遍采用多核架构。此外,为了加快设计周期,新的方法学和框架也不断涌现。本文采用基于可重构视频编码CAL Actor语言(RVC-CAL)和OpenMP API的方法学,实现了一个基于多核DSP的HEVC解码器。以HEVC解码器的RVC-CAL描述作为起点,利用开放RVC-CAL编译器框架(Orcc)从RVC-CAL规范生成C代码。该代码结合OpenMP库被移植到多核DSP环境。对运行在1、2、3和4核上的解码器进行了测试。同时,还将基于多DSP的HEVC解码器与基于多核通用处理器(GPP)的其他实现进行了比较。
索引词
HEVC,数字信号处理器,多核,OpenMP,CAL,Orcc。
I. 引言
近年来,具有高清视频播放能力的便携设备使用量不断增加。例如,高端手机的空间分辨率目前已达到1080p。与此同时,新的视频压缩算法也已实现标准化。2013年发布的高效视频编码(HEVC)标准[1],在保持相同质量的前提下,相比之前的H.264实现了平均约50%的比特率降低[2]。不断提高的视频分辨率和新标准共同推动了处理器对计算能力的需求增长。在便携设备中,单核处理器已无法满足需求,现已被多核芯片所取代。
市场上有大量多核芯片可供选择[3][4][5][6][7]。基于这些架构的系统设计是一项复杂且具有挑战性的任务。其中一个挑战就是上市时间。设计工程师必须在短时间内使用最先进的复杂架构来实现新的复杂算法。这为新的方法学和框架打开了大门,即使设计团队对算法和架构的知识相对薄弱,也能实现更短的设计周期。
为了加快新视频编码标准的部署,ISO/IEC已经对可重构视频编码(RVC)框架[8][9]进行了标准化。在此框架内,不同视频解码器的抽象模型使用RVC-CAL参与者语言编写。这些模型是由一组通过先进先出队列互连的功能单元(FU)组成的数据流模型。此类模型以显式方式描述了算法的并行性。此外,还建立了开放RVC-CAL编译器(Orcc)[10]基础设施,能够从RVC-CAL描述自动生成多线程C代码(以及其他代码)。
一些研究小组正在使用RVC-CAL/Orcc进行研究。雷恩国立应用科学学院(INSA)致力于可重构视频解码器领域的[11]研究。洛桑联邦理工学院(EPFL)的SCI-STI-MM小组致力于通过FPGA和多核通用处理器(GPP)实现基于RVC-CAL描述的视频编解码器[12]。马德里理工大学(UPM)的GDEM小组则专注于利用数字信号处理器技术开发高效的视频解码器[13][14]。
Orcc生成的代码可直接在任何具有支持多线程管理的操作系统(OS)的多核平台中执行;例如[3][4]。但对于基于多核DSP的架构(如[5])或异构DSP-GPP平台(如[6])则不适用。这些属于共享内存架构,缺乏运行应用程序并支持多线程的集中式操作系统(OS)。此外,Orcc不支持基于图形处理器(GPU)的架构,如[7]。
开放多处理(OpenMP)API[15]是一种支持C/C++中跨平台共享内存并行编程的开源应用程序编程接口。OpenMP已在基于通用处理器(GPP)[16][17][18][19]和数字信号处理器(DSP)[20][21][22][23]多核架构的实现中得到广泛应用。
在我们之前的工作中[24],提出了一种基于RVC-CAL、Orcc和OpenMP的设计方法,并展示了使用多核DSP实现的2核心HEVC视频解码器[5]。本文详细阐述了该设计方法,同时测试了最多4个核心的解码器,并将其结果与在同一解码器上运行于两种不同的多核通用处理器(GPP)的结果进行了比较。据我们所知,这是首次在多核DSP上使用RVC-CAL/Orcc和OpenMP进行的实现。
本文的其余部分分为6个部分。第二节介绍了有助于理解本文其余部分的背景知识。第三节描述了HEVC解码器的单核实现及其性能分析结果。第四节描述了使用2、3和4个核心的多核实现,并展示了解码器随核心数量增加的速度提升。在第五节中,将第四节中显示的性能结果与在同一解码器上基于两种不同通用处理器的多核处理器实现所获得的结果进行了比较。最后,第六节对全文进行了总结。
二. 背景
本节简要汇集了理解本文所呈现工作所需的基础知识。
A. HEVC解码器
HEVC是最新的ISO/IEC视频压缩标准[1][26]。预计几年内将取代H.264/MPEG-4 (AVC)。HEVC的高层语法架构与H.264相似,包含网络抽象层(NAL)和视频编码层(VCL)。在VCL中,图像被划分为编码树单元(CTUs),这是H.264宏块的更灵活版本。CTUs被划分为亮度和色度编码树块(CTBs)。CTBs可进一步分割为编码块(CBs)。
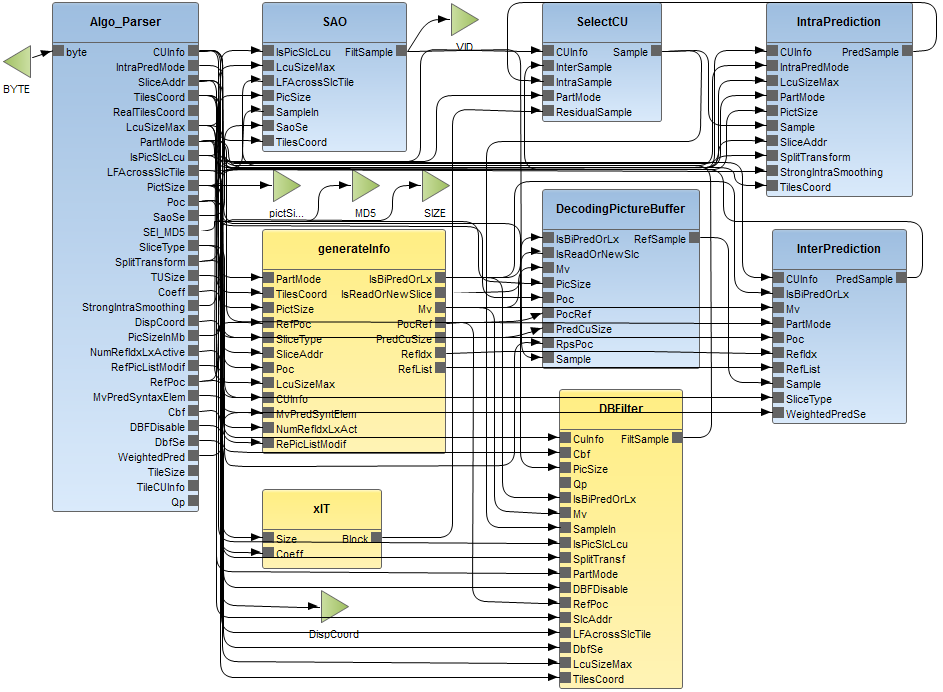
图1显示了一个简化的HEVC解码器框图。该解码器以CTU为基础进行工作。熵解码器主要基于算术编码(CABAC)。解码后的残差数据经过去量化和逆变换(逆量化和逆变换)。对于帧内编码CTU,通过基于先前已解码的相邻CBs计算预测(帧内预测)。对于帧间编码CTU,预测由运动补偿模块从存储在解码图像缓冲区中的先前解码图像中获得。对重建像素应用去块滤波器和采样自适应偏移(SAO)滤波器,以减少块效应并提高解码图像的质量。
B. RVC-CAL
接下来,将解释本工作所使用的RVC-CAL/Orcc基础设施以及HEVC解码器的模型。
1) RVC-CAL/Orcc基础设施
为了简化新视频压缩标准的部署,已建立了一套称为RVC框架的标准。其中与本工作相关的有两个标准:MPEG-B第4[8]部分对功能单元网络语言(FNL)和RVC-CAL参与者语言进行了标准化,而MPEG-C第4[9]部分对视频工具库(VTL)进行了标准化,该库包含被称为功能单元(FU)的视频编码组件。在RVC框架内,视频编解码器可以被描述为一组通过FNL互连的功能单元(FU)。每个FU可包含其他FU,或在最低层次级别上包含执行单元(actor)的RVC-CAL描述。每个执行器封装了自身的输入/输出接口和算法,并仅通过先进先出队列(FIFOs)与其他执行器交互。利用VTL,已构建了多种视频解码器的RVC-CAL模型。这些解码器可在RVC-CAL Apps开源仓库[27]中公开获取。
Orcc[10]是一套开源的工具集,能够从RVC-CAL模型自动生成多种源代码。该工具提供一个图形环境,可用于选择、绘制和互连功能单元(FU),并生成FNL代码以及编写RVC-CAL描述。Orcc具备多个后端,可从RVC-CAL描述生成C语言、C++、Java语言和VHDL语言等源代码。图2展示了使用Orcc的工作流程:RVC-CAL模型可以从开源仓库获取,通过VTL中的功能单元互连生成,或从零开始编写。Orcc编译器会生成C语言或其他语言的解决方案,包括多个Orcc库。随后,可通过本地编译器进行编译,并在目标平台执行。Orcc可以为多核生成多线程代码。在此情况下,必须在文本文件(*.xcf)中指定执行器在各个核心上的静态分配。
2) HEVC解码器的RVC-CAL模型
在本研究中,所使用的HEVC解码器是从RVC-CAL应用程序的开源仓库下载的。该模型由41个功能单元和33个执行单元(actor)组成。图3展示了HEVC解码器顶层层次结构的图形表示。表I描述了图3中显示的9个功能单元,以及用于测试解码器的Source和Display功能单元。表I的第一行列出了每个功能单元的名称,第二行列明该功能单元是否为层次化结构。对于层次化功能单元,第三行显示了下一层级中功能单元的总数。最后,第四行列出了功能单元内执行单元(actor)的总数,最后一行总结了其功能。图3中的功能单元与图1中的功能模块之间的对应关系如表II所示。
表I HEVC解码器顶层层次结构中的功能单元
| FU | 描述 | 层次 | #FUs | 参与者数量 | 功能 |
|---|---|---|---|---|---|
| 源 | no | n.a. | 1 | 1 | 待解码的比特流 |
| Algo_parser | no | n.a. | 1 | 1 | 解码视频流 |
| xIT | yes | 26 | 21 | 21 | 逆变换 |
| 帧内预测 | no | n.a. | 1 | 1 | 帧内预测 |
| 帧间预测 | no | n.a. | 1 | 1 | 帧间预测 |
| 选择CU | no | n.a. | 1 | 1 | 图像重建 |
| 生成信息 | yes | 2 | 2 | 2 | 获取帧间预测的信息(例如运动矢量) |
| DecodingPicture Buffer | no | n.a. | 1 | 1 | reference pictures buffer |
| DBFilter | yes | 2 | 2 | 2 | 去块滤波器 |
| SAO | no | n.a. | 1 | 1 | SAO滤波器 |
| 显示 | no | n.a. | 1 | 1 | 显示解码后的图像 |
表II FU与解码器功能模块的对应关系
| HEVC解码器功能块(图1) | Acronym | CAL-RVC模型功能单元(图3) |
|---|---|---|
| 熵解码器 | ED | Algo_parser |
| 逆变换和量化 | ITQ | xIT |
| 帧内预测 | IP | IntraPrediction |
| 运动补偿 | EP | InterPrediction, GenerateInfo |
| 解码图像缓冲区 | BF | 解码图像缓冲区 |
| 去块滤波器 | DF | 去块滤波器 |
| 采样自适应偏移 | SAO | SAO |
| CU管理 | CU | 选择CU |
C. 目标多核数字信号处理器的架构
在本研究中,采用了一款多核DSP[5]作为目标架构。图4展示了该处理器的主要功能模块。该处理器由8个基于超长指令字架构的核心组成。每个核心具有两级缓存存储层级。第一级包含32 KB的程序缓存和数据缓存(L1P和L1D)。第二级为512 KB的内存(L2),可配置为映射RAM或缓存。这8个核心可以共享一个内部4 MB内存(MSMC)以及外部DDR3内存。核心间的通信由多核导航器管理,其采用基于队列的通信系统。最后值得注意的是,每个核心均运行各自独立的实时操作系统(RTOS)副本。
D. OpenMP简介
OpenMP是用于共享内存多处理器并行编程的行业事实标准应用程序编程接口。本工作所使用的OpenMP运行时[29]支持OpenMP 3.0规范[15]。
OpenMP遵循分叉/合并模型来组合顺序和并行化代码段。在C/C++实现中,代码执行通过OpenMP指令进行控制。一个OpenMP应用程序始终从一个主线程开始,该主线程在整个程序运行期间执行。当主线程检测到并行区域时,它会派生出一定数量的独立线程。线程间的同步是隐式的。当所有线程完成执行后,主线程恢复。在每次派生中,线程数量可以通过指令在代码中设置,也可以在运行时选择。
III. 解码器的单核实现
本节描述了一种基于DSP多核处理器并使用单个核心的HEVC解码器实现。该实现在本工作中被用作参考。此外,III.C中所示的性能分析被用作生成基于2、3和4个核心实现中的“核心间的功能单元分布”的基础(见IV.B)。
A. 单核实现
在II.B.2中解释的RVC-CAL模型已被用于开发单核HEVC解码器实现。如II.B.1所述,使用Orcc C后端生成源代码。该源代码的main函数在图5中概述。在初始化全局变量和先进先出队列后,创建一个包含待运行执行单元(actor)列表的调度器。在此情况下,核心数量(nb_cores)设置为1。随后,在for循环中创建单个线程并将其与调度器关联。接着,通过调用orcc_set_thread_affinity将创建的线程绑定到某个核心上。之后,启动该线程。最后,调度器例程使用轮转算法运行所有执行单元(actor),并在它们就绪时(例如,其先进先出队列中有待处理数据时)执行。
主函数(){
... //全局变量和FIFOs .....
//创建包含所有执行单元(actor)的调度器 .....
//核心数量定义 nb_cores=1;
//将每个线程与对应的调度器关联
for(i=0;i<nb_cores;i++){
orcc_thread_create(..., scheduler_routine, schedulers[i], ...);
}
//将每个线程与一个核心关联
orcc_set_thread_affinity( arch_core_set, ...);
.....
} //主函数结束
//由线程执行的调度器例程
scheduler_routine (){
//局部变量 .....
while(1){
//读取下一个待执行的执行器
my_actor = get_next_schedulable();
//执行器运行
my_actor->actor_run();
}
}
图5. Orcc为单核实现生成的C代码。
Orcc生成的源代码必须先移植到DSP环境后才能进行编译。由于DSP环境不支持线程,因此需移除线程创建和线程到核心映射部分,并显式启动调度器,如图6所示。将代码移植到DSP环境还需要一些其他较小的修改,主要在[30]中说明。最后,必须确定一些内存配置。在此情况下,已配置32 KB的L1缓存和256 KB的L2缓存。程序代码以及用于互连执行单元(actor)的先进先出队列均分配在4 MB的共享内存中。其他缓冲区和数据则分配在DDR3内存中。
main(){
... //全局变量和FIFO .....
//创建包含所有执行单元(actor)的调度器 .....
//运行调度器
scheduler_routine ();
//使用单核执行调度器
scheduler_routine (){
//局部变量
while(1){
//以轮询方式读取下一个待执行的执行器
my_actor = get_next_schedulable();
//执行器运行
my_actor->actor_run();
}
} //主函数结束
}
图6. 数字信号处理器(DSP)上用于单核实现的C代码。
此实现的测试和性能结果如III.C所示。
B. 单核实现与OpenMP
为了评估OpenMP运行时对解码器性能的影响,图6中概述的代码已按图7所示进行了修改。首先,将核心数量设置为1。然后,通过一个
omp parallel
指令标记并行区域的开始。最后,使用omp section指令派生调度器例程。此外,OpenMP运行时代码应分配在位于共享内存中的不可缓存的内存区域。同时应定义并分配OpenMP堆。这些需求通过板级配置实现。
主函数(){
... //全局变量和FIFO .....
//创建包含所有执行单元(actor)的调度器 .....
//核心数量定义 omp_set_num_cores(1);
//定义并行区域
#pragma omp parallel{
//定义由主核执行的段
#pragma omp section{
调度器_routine ();
}//结束 omp段
}//结束并行区域
} //结束主函数
//在omp段中执行的例程
调度器_routine (){
//局部变量 .....
while(1){
//读取下一个待执行的执行器
my_actor = get_next_schedulable();
//执行器运行
my_actor->actor_run();
}
}
图7. 单个DSP核心实现中集成OpenMP。
C. 测试和结果
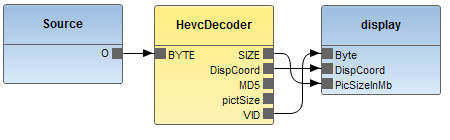
单核实现已在商用平台[24]上进行测试,该平台采用运行频率为@ 1GHz的DSP多核处理器和512MB DDR3外部内存。测试使用了图8所示的测试平台,该测试平台与HEVC解码器的RVC-CAL模型中包含的测试平台相同,仅对Source和Display功能单元进行了若干修改。Source功能单元从主机PC读取输入比特流,并将其存储在DDR3内存中分配的缓冲区中。HevcDecoder功能单元包含如图3所示的HEVC解码器。Display功能单元读取解码图像,并将其存储在DDR3内存中分配的缓冲区中。使用64位定时器获取了表IV、表V、表VI、表七和表IX中所示的性能分析数据。
从JCT-VC通用测试中选取了四个C类(832×480像素)HEVC序列进行测试:篮球训练(BD)、商场(BM)、聚会场景(PS)以及赛马(RH)。对于每个序列,均使用了低延迟(LD)和随机访问(RA)配置。仅考虑测试条件中定义的两个中间量化参数(QP)值。表III列出了这些序列的特性。
表III 测试中使用的HEVC比特流特性
| 配置 | Name (acronym) | QP | 比特率(千比特每秒) | 帧数 |
|---|---|---|---|---|
| 低延迟 (LD) | 篮钻探球(BD) | 27 | 864 500 | 32 417 |
| 低延迟 (LD) | BQMall (BM) | 27 | 779 600 | 32 382 |
| 低延迟 (LD) | 聚会场景 (PS) | 27 | 1799 500 | 32 793 |
| 低延迟 (LD) | 赛马 (RH) | 27 | 1979 300 | 32 876 |
| 随机访问 (RA) | 篮钻探球(BD) | 27 | 836 500 | 32 416 |
| 随机访问 (RA) | BQMall (BM) | 27 | 714 600 | 32 364 |
| 随机访问 (RA) | 聚会场景 (PS) | 27 | 1617 500 | 32 766 |
| 随机访问 (RA) | 赛马 (RH) | 27 | 1766 300 | 32 830 |
表IV显示了HEVC解码器在单核上运行时使用和不使用OpenMP的性能。结果以每秒帧数表示,针对低延迟配置下的4个序列和2个量化参数给出。最后两列分别给出了QP=27和QP=32的平均数据。表V显示了随机访问配置下的相同结果。这些结果表明,在解码器中集成OpenMP会使其性能降低约15%。
表IV 单核实现使用低延迟序列为每秒帧数解码
| 序列 | BD | BM | PS | RH | AVG |
|---|---|---|---|---|---|
| QP | 27 | 32 | 27 | 32 | 27 |
| 无 OpenMP | 3.8 | 4.5 | 3.7 | 4.4 | 2.9 |
| OpenMP | 3,4 | 4,0 | 3,3 | 3,9 | 2,6 |
表V 单核实现使用随机访问序列为每秒帧数解码
| 序列 | BD | BM | PS | RH | AVG |
|---|---|---|---|---|---|
| QP | 27 | 32 | 27 | 32 | 27 |
| 无 OpenMP | 3.8 | 4.5 | 3.8 | 4.3 | 3.2 |
| OpenMP | 3,4 | 3,9 | 3,3 | 3,8 | 2,8 |
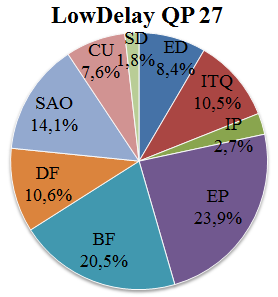
表VI显示了在量化参数为=27和=32的4个序列的LD配置下,解码器功能单元中解码时间的分布情况。该信息以总执行时间的百分比表示。功能单元的命名采用了表II中使用的缩写词。SD代表用于读取序列的源功能单元和用于将解码图像写入缓冲区的显示功能单元。在最后两列中,给出了两个QP的平均数据。表七显示了随机接入序列的相同信息。
表VI 低延迟序列中解码器功能单元的解码时间分布(总执行时间的百分比)
| Seq. | BD | BM | PS | RH | AVG. |
|---|---|---|---|---|---|
| QP | 27 | 32 | 27 | 32 | 27 |
| ED | 6,0 | 4,0 | 7,4 | 5,0 | 10,4 |
| ITQ | 11,8 | 10,3 | 9,6 | 8,8 | 9,7 |
| IP | 2,6 | 2,4 | 2,6 | 2,5 | 2,8 |
| EP | 23,2 | 25,4 | 23,9 | 25,5 | 25,1 |
| BF | 19,1 | 19,5 | 21,3 | 21,4 | 22,5 |
| DF | 11,5 | 12,5 | 11,3 | 12,3 | 9,8 |
| SAO | 15,3 | 13,8 | 13,6 | 12,5 | 11,2 |
| CU | 8,5 | 9,8 | 8,4 | 9,6 | 6,9 |
| SD | 2,0 | 2,2 | 2,0 | 2,2 | 1,6 |
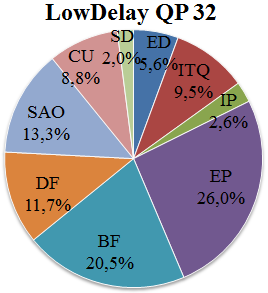
表七 随机访问序列中解码器功能单元的解码时间分布(总执行时间的百分比)
| Seq | BD | BM | PS | RH | AVG. |
|---|---|---|---|---|---|
| QP | 27 | 32 | 27 | 32 | 27 |
| ED | 6,2 | 4,2 | 6,8 | 4,7 | 10,2 |
| ITQ | 10,0 | 8,8 | 8,4 | 7,5 | 9,0 |
| IP | 3,5 | 3,1 | 3,1 | 2,9 | 3,8 |
| EP | 23,8 | 25,6 | 24,5 | 26,0 | 24,7 |
| BF | 20,1 | 20,4 | 23,5 | 23,7 | 21,3 |
| DF | 11,7 | 12,5 | 11,3 | 12,0 | 10,5 |
| SAO | 13,8 | 13,2 | 11,8 | 11,5 | 10,9 |
| CU | 8,8 | 9,9 | 8,6 | 9,5 | 7,7 |
| SD | 2,0 | 2,3 | 2,0 | 2,2 | 1,8 |
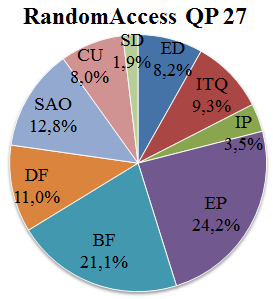
根据表VI中的信息绘制了图9所示的图表。这些图表展示了在LD配置下,针对QP=27和QP=32两种情况,不同功能单元之间的平均解码时间分布。图10则基于表七,显示了RA配置下的相同信息。
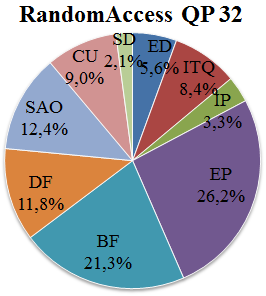
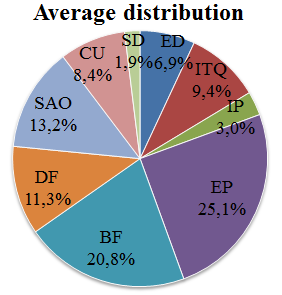
图11显示了在不同功能单元之间的解码时间分布,该数据是针对两种配置和量化参数取平均值的结果。该信息指导了在IV.B中描述的2、3和4核心测试中功能单元与核心之间的静态映射。
IV. 解码器的多核实现
A. 使用OpenMP的实现
对于多核实现,主核开始执行图12中概述的代码。在初始化全局变量和先进先出队列后,根据xcf文件中描述的集群数量创建多个调度器。num_cores变量被设置为调度器的数量。随后,通过omp parallel指令标记一个并行区域。在图12中概述的代码中,使用omp section指令定义了四个部分,每个部分分配一个调度器。OpenMP运行时在不同的核心上启动每个调度器的执行。
main(){
//全局变量和FIFO由所有核心共享
//创建调度器并为其分配映射的执行单元
.....
//num_cores变量根据XCF文件设置
.....
//核心数量定义
omp_set_num_cores(num_cores);
//定义一个并行区域
#pragma omp parallel{
//定义一个由主核执行的段
#pragma omp section{
scheduler_routine_0 (&scheduler_0);
}//结束omp段和主核代码
//定义一个由核心1执行的段
#pragma omp section{
scheduler_routine_1 (&scheduler_1);
}//结束omp段和核心1代码
//定义一个由核心2执行的段
#pragma omp section{
scheduler_routine_2 (&scheduler_2);
}//结束omp段和核心2代码
//定义一个由核心3执行的段
#pragma omp section{
scheduler_routine_3 (&scheduler_3);
}//结束omp段和核心3代码
}//结束并行区域
}//结束main
//在omp段中执行的例程
scheduler_routine (Tscheduler *scheduler){
//局部变量
while(1){
//读取下一个要执行的执行单元
my_actor = get_next_schedulable(scheduler);
//执行单元运行
my_actor->actor_run();
}
}
图12. 在多核DSP实现中集成OpenMP。
B. 功能单元在核心间的分布
根据图11中综合的信息,已为最多4个核心选择了功能单元与核心之间的静态分布。分配准则是使各核心之间的计算负载分布均衡。如果有多种可选方案,则根据性能测试结果和设计人员经验选择最合适的方案。最终选定的映射关系如表VIII所示。
表VIII 核心间的功能单元分布
| 核心1 | 核心2 | 核心3 | 核心4 |
|---|---|---|---|
| 1 核心 | All | ------ | ------ |
| 2 核心 | SD,ED,ITQ,IP,DF,CU | EP, BF, SAO | ---- |
| 3 核心 | SD、ED、ITQ、IP、SAO | BF, DF, CU | EP |
| 4个核心 | SD, ED, IP, DF | ITQ, SAO | EP |
| ## C. 测试与结果 |
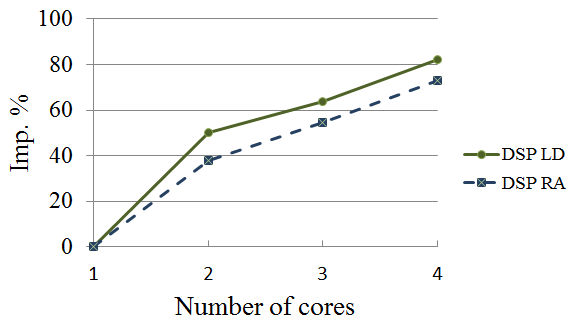
在III.C中描述的相同测试平台、序列和平台被用于分析多核HEVC解码器。结果如表IX所示。单核(使用OpenMP)的结果如表IV和表V所示,已包含相关内容。使用两个核心时,每秒帧数增加约40–50%。使用3个和4个核心时,提升率分别缩短至10%和20%。这些结果总结于图13。
表IX HEVC解码器根据核心数量解码的每秒帧数(基于DSP的实现)
| Num. 核心 | QP | BD | BM | PS | RH |
|---|---|---|---|---|---|
| QP 27 | QP 32 | QP 27 | QP 32 | ||
| LD | 1 | 3,4 | 4,0 | 3,3 | 3,9 |
| LD | 2 | 5,1 | 6,0 | 5,1 | 5,8 |
| LD | 3 | 5,5 | 6,5 | 5,4 | 6,3 |
| LD | 4 | 6,2 | 7,2 | 6,1 | 7,0 |
| RA | 1 | 3,4 | 3,9 | 3,3 | 3,8 |
| RA | 2 | 4,6 | 5,5 | 4,6 | 5,1 |
| RA | 3 | 5,2 | 6,0 | 5,1 | 5,7 |
| RA | 4 | 5,8 | 6,8 | 5,7 | 6,4 |
V. 与其他实现的比较
相同的RVC-CAL HEVC解码器已被用于在两种不同的多核处理器GPP#1[3]和GPP#2[4]上实现HEVC解码器。GPP#1运行频率为3.076吉赫,GPP#2运行频率为1.76吉赫,两者均在Linux操作系统下运行。在这两种情况下,Orcc生成可直接编译并在目标架构上执行的C源代码。表VIII中所示的相同映射已用于2、3和4个核心。通过使用表III中描述的相同测试序列执行解码器来进行测试。使用RVC性能分析器收集了性能分析结果。对于4个序列在LD和RA配置下,以及QP=27和QP=32的情况,每秒解码帧数分别在表X和表XI中显示。
表X. HEVC解码器根据核心数量解码的每秒帧数(基于GPP#1的实现)
| Num. 核心 | QP | BD | BM | PS | RH |
|---|---|---|---|---|---|
| QP 27 | QP 32 | QP 27 | QP 32 | ||
| LD | 1 | 26.4 | 30.8 | 26.9 | 30.8 |
| LD | 2 | 39.4 | 45.1 | 39.9 | 44.2 |
| LD | 3 | 42.0 | 49.2 | 41.6 | 44.4 |
| LD | 4 | 46.9 | 53.1 | 46.8 | 54.2 |
| RA | 1 | 27.7 | 30.8 | 28.1 | 31.2 |
| RA | 2 | 37.0 | 42.7 | 37.4 | 41.4 |
| RA | 3 | 40.3 | 45.7 | 41.4 | 45.5 |
| RA | 4 | 44.3 | 51.1 | 45.2 | 51.4 |
表XI HEVC解码器根据核心数量解码的每秒帧数(基于GPP#2的实现)
| Num. 核心 | QP | BD | BM | PS | RH |
|---|---|---|---|---|---|
| QP 27 | QP 32 | QP 27 | QP 32 | ||
| LD | 1 | 7.1 | 8.3 | 7.2 | 8.3 |
| LD | 2 | 11.4 | 13.1 | 11.5 | 13.2 |
| LD | 3 | 13.5 | 15.8 | 13.9 | 16.0 |
| LD | 4 | 15.1 | 17.4 | 16.0 | 18.1 |
| RA | 1 | 7.1 | 8.1 | 7.1 | 8.0 |
| RA | 2 | 10.6 | 12.0 | 10.7 | 11.7 |
| RA | 3 | 12.7 | 14.5 | 13.1 | 14.5 |
| RA | 4 | 14.6 | 16.5 | 14.9 | 15.9 |
A. 讨论
为了公平地比较基于DSP、GPP#1和GPP#2的实现,表十二列出了三种目标架构的相关特性。基于GPP#1的架构明显优于其他两种。该分析与基于GPP#1的实现性能高度相关,其解码速度比基于GPP#2的架构快约3倍,比基于DSP的架构快约7.6倍。值得注意的是,本文所使用的GPP#1架构由于成本高和功耗大,不适合嵌入式实现。
表十二 架构资源比较
| 核心频率 (千兆赫) | L1 缓存 (KB) | L2 缓存 (KB) | 其他 Mem. (MB) | 外部内存 | |
|---|---|---|---|---|---|
| DSP | 8 | 1.00 | 32 | 512 | 4 (共享) |
| GPP#1 | 4 | 3.07 | 32 | 256 | 8 (三级缓存) |
| GPP#2 | 4 | 1.76 | 32 | 1024 | – |
表IX和表XI所示的结果表明,基于GPP#2的解码器性能大约是基于DSP的解码器性能的2.5倍。DSP和GPP#2架构的特性彼此较为接近,但后者在三个关键特性上表现更优:系统时钟频率、SDRAM时钟频率和L2缓存大小。此外,由于DSP核心采用超长指令字架构,DSP编译器更难生成优化代码。最后,基于DSP的解码器需要OpenMP运行时,这会引入约10–15%的速度损失。如果将DSP解码器的系统时钟频率提升至1.76吉赫,则考虑到SDRAM时钟速度、L2缓存大小以及OpenMP速度损失的差异,其性能将相对于GPP#2解码器表现得相当不错。

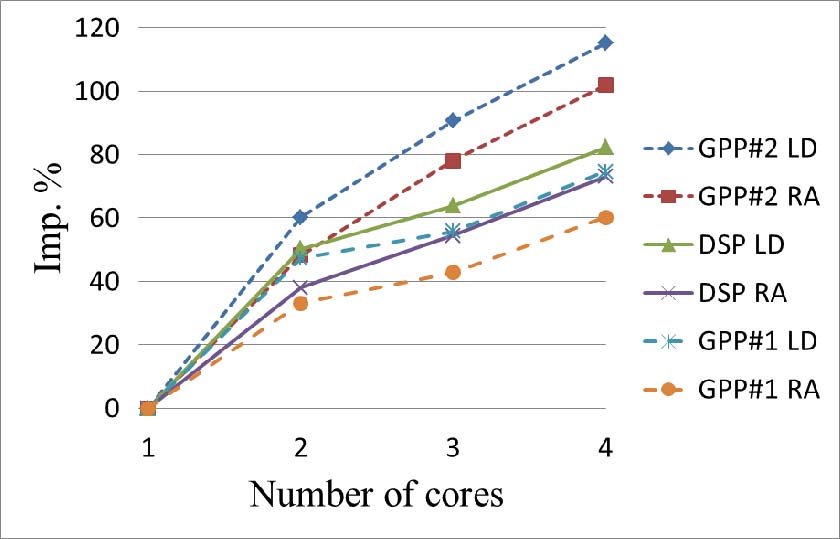
此外,图14比较了三种实现方式在不同核心数量下的性能提升。结果分别给出了低延迟和随机访问配置的情况。可以看出,随着核心数量的增加,三种架构的性能提升趋势相似,尽管基于GPP#2的架构在3个和4个核心时的提升速率优于其他两种架构。
VI. 结论
本文提出了一种基于多核DSP处理器的HEVC解码器。据我们所知,这是首个基于DSP的多核HEVC解码器实现。本工作以RVC-CAL模型为基础,采用Orcc编译器从RVC-CAL模型生成C源代码,并将该C源代码移植到DSP环境,同时利用OpenMP在多个核心之间实现执行并行化。该方法可加快设计周期,并便于未来进行修改。
该解码器已使用JCT-VC通用测试中的序列进行了测试。性能结果与另外两种基于不同多核通用处理器(GPP)的实现方案进行了比较。正如预期,基于GPP#1[3]的实现方案在速度上远超其他两种方案。基于GPP#2[4]的实现方案也比基于DSP的方案快2.5倍。这种差异大部分源于GPP#2架构更高的系统时钟频率、更高的SDRAM时钟频率以及更大的L2缓存大小。此外,部分差距可能归因于使用OpenMP运行时所带来的开销。
此外,GPP#2和基于DSP的实现所使用的代码均未针对各自架构的特殊功能进行优化。这可能被视为基于DSP实现的一个劣势,因为与DSP编译器相比,GPP编译器效率非常高;但这也可能被视为一个机遇,因为如果充分利用DSP架构的特定功能,其实现有很大的性能提升潜力。
总之,RVC-CAL方法结合OpenMP已被证明适用于基于多核DSP架构的视频解码器实现。然而,为了使这些架构在速度上具有竞争力,必须充分利用DSP架构的特性。同时,还需提升OpenMP运行时的性能。
在撰写本文期间,已发布了一个新的、更具并行性的RVC-CAL HEVC解码器版本。在未来的工作中,我们将使用这个新版本测试超过4个DSP核心时的性能,以充分挖掘HEVC解码器的并行性。此外,还将开发用于实现算法关键部分的优化代码,并将其集成到设计中,同时保持基于RVC-CAL/Orcc的方法论。最后,我们计划修改Orcc C后端,以自动包含OpenMP支持以及针对DSP架构的优化机制。

















 6689
6689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









