




 本文通过Python探讨Anscombe's quartet四个数据集,涉及数据读取、统计分析(均值、方差、相关系数)及线性回归。使用pandas、statsmodels和seaborn进行数据处理和可视化,揭示数据背后的有趣现象。
本文通过Python探讨Anscombe's quartet四个数据集,涉及数据读取、统计分析(均值、方差、相关系数)及线性回归。使用pandas、statsmodels和seaborn进行数据处理和可视化,揭示数据背后的有趣现象。
提要:配置jupyter notebook可以参考
https://blog.youkuaiyun.com/red_stone1/article/details/72858962
下载的csv文件如果出现问题,可以参考:
https://jingyan.baidu.com/album/c843ea0b9a641477931e4a89.html?picindex=2
%matplotlib inline
import random
import numpy as np
import scipy as sp
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels.api as sm
import statsmodels.formula.api as smf
sns.set_context("talk")Anscombe’s quartet
Anscombe’s quartet comprises of four datasets, and is rather famous. Why? You’ll find out in this exercise.
anascombe = pd.read_csv('data/anscombe.csv')
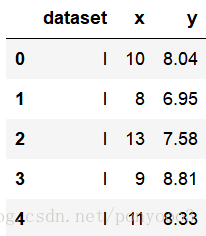
anascombe.head()解释:
pandas.read_csv
读取CSV(逗号分割)文件到DataFrame,也支持文件的部分导入和选择迭代。
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_csv.html
参数整理:(很详细)
https://www.cnblogs.com/datablog/p/6127000.htmlanscombe.head()
使用函数head( m )来读取查看前m条数据,如果没有参数m,默认读取前五条数据。
Output:
Part 1
For each of the four datasets…
Compute the mean and variance of both x and y
Compute the correlation coefficient between x and y
Compute the linear regression line: y=β0+β1x+ϵy=β0+β1x+ϵ (hint: use statsmodels and look at the Statsmodels notebook)
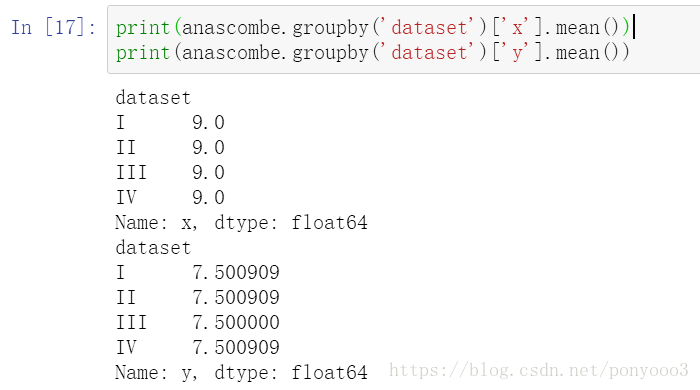
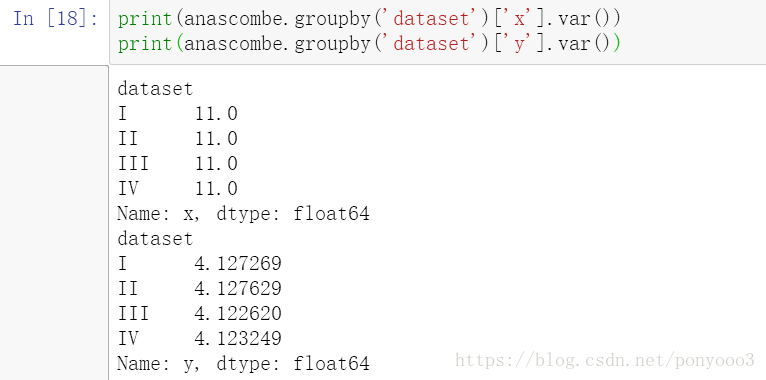
计算均值mean和方差variance:
print(anascombe.groupby('dataset')['x'].mean())
print(anascombe.groupby('dataset')['y'].mean())解释:
grouby可以对传入的参数进行分组
https://blog.youkuaiyun.com/leonis_v/article/details/51832916pandas.DataFrame.mean()
返回数据的平均值
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.mean.htmlpandas.DataFrame.var()
返回数据的方差
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.var.html
Output:
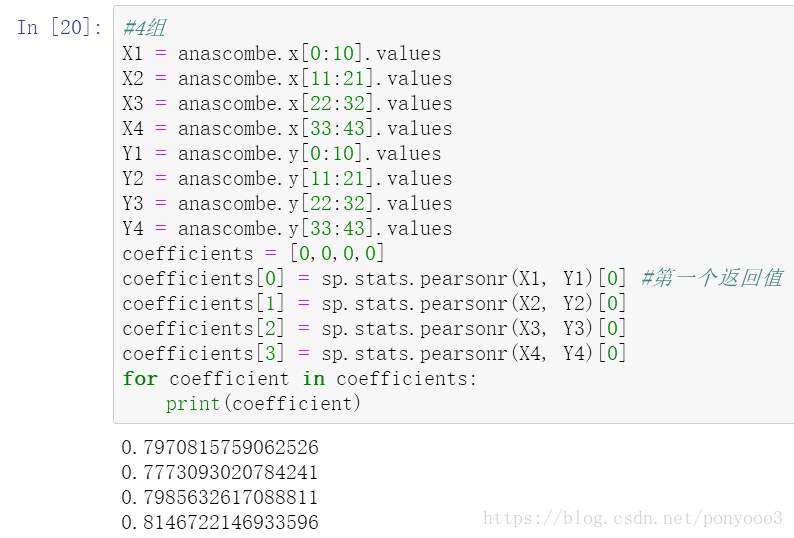
计算x和y的相关系数:
#4组
X1 = anascombe.x[0:10].values
X2 = anascombe.x[11:21].values
X3 = anascombe.x[22:32].values
X4 = anascombe.x[33:43].values
Y1 = anascombe.y[0:10].values
Y2 = anascombe.y[11:21].values
Y3 = anascombe.y[22:32].values
Y4 = anascombe.y[33:43].values
coefficients = [0,0,0,0]
coefficients[0] = sp.stats.pearsonr(X1, Y1)[0] #第一个返回值
coefficients[1] = sp.stats.pearsonr(X2, Y2)[0]
coefficients[2] = sp.stats.pearsonr(X3, Y3)[0]
coefficients[3] = sp.stats.pearsonr(X4, Y4)[0]
for coefficient in coefficients:
print(coefficient)解释:
- 先手动获取每组数据的x和y
pandas.DataFrame.values()
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.values.htmlscipy.stats.pearsonr(x, y)
计算相关系数
https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.pearsonr.html#scipy.stats.pearsonr
Output:
计算线性回归方程
#1
X_I = sm.add_constant(X1)
model_I = sm.OLS(Y1, X_I)
result_I = model_I.fit()
params_I = result_I.params
print("I: y =", params_I[0], "+", params_I[1], "x")
#2
X_II = sm.add_constant(X2)
model_II = sm.OLS(Y2, X_II)
result_II = model_II.fit()
params_II = result_II.params
print("II: y =", params_II[0], "+", params_II[1], "x")
#3
X_III = sm.add_constant(X3)
model_III = sm.OLS(Y3, X_III)
result_III = model_III.fit()
params_III = result_III.params
print("III: y =", params_III[0], "+", params_III[1], "x")
#4
X_IV = sm.add_constant(X4)
model_IV = sm.OLS(Y4, X_IV)
result_IV = model_IV.fit()
params_IV = result_IV.params
print("IV: y =", params_IV[0], "+", params_IV[1], "x") 解释:
参考:https://blog.youkuaiyun.com/cymy001/article/details/78364652
Output:

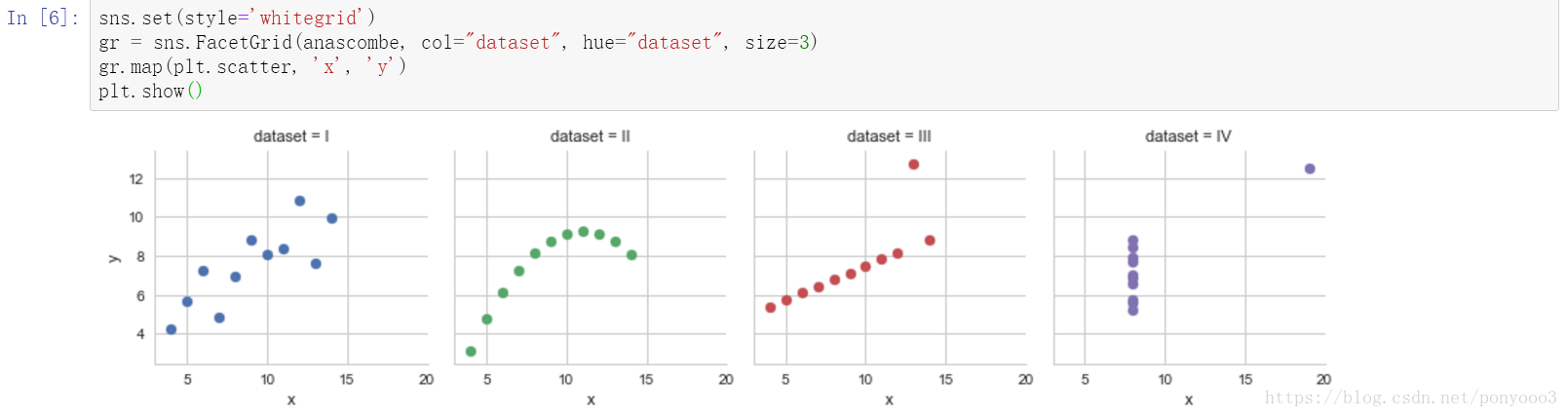
Part 2
Using Seaborn, visualize all four datasets.
hint: use sns.FacetGrid combined with plt.scatter
sns.set(style='whitegrid')
gr = sns.FacetGrid(anascombe, col="dataset", hue="dataset", size=3)
gr.map(plt.scatter, 'x', 'y')
plt.show()参考:官网及https://blog.youkuaiyun.com/yutao03081/article/details/79064669
Output:

















 9603
9603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









