




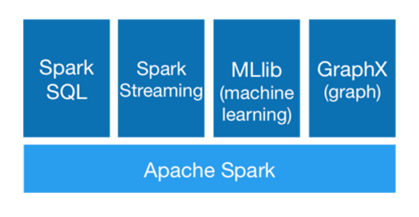
 Apache Spark是一个快速、通用的大规模数据处理引擎,它扩展了MapReduce模型,提供了DAG编程模型,支持离线、流式和迭代计算。Spark Core是基础,包含任务调度和错误恢复,RDD是核心抽象。Spark SQL用于结构化数据处理,兼容Hive SQL和多种数据源。Spark Streaming处理实时数据,而MLlib提供机器学习功能,GraphX则专注于图计算。Spark与Hadoop相辅相成,但也面临Flink、Storm等竞争者。
Apache Spark是一个快速、通用的大规模数据处理引擎,它扩展了MapReduce模型,提供了DAG编程模型,支持离线、流式和迭代计算。Spark Core是基础,包含任务调度和错误恢复,RDD是核心抽象。Spark SQL用于结构化数据处理,兼容Hive SQL和多种数据源。Spark Streaming处理实时数据,而MLlib提供机器学习功能,GraphX则专注于图计算。Spark与Hadoop相辅相成,但也面临Flink、Storm等竞争者。
Spark 是什么?
● 官方文档解释:Apache Spark™ is a fast and general engine for large-scale data processing.
通俗的理解:Spark是基于内存计算的大数据并行计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark 部署在大量廉价硬件之上,形成集群。
● 扩展了MapReduce计算模型;相比与MapReduce编程模型,Spark提供了更加灵活的DAG(Directed Acyclic Graph) 编程模型, 不仅包含传统的map、reduce接口, 还增加了filter、flatMap、union等操作接口,使得编写Spark程序更加灵活方便。
● 高效支持多种计算模式;Spark 不仅可以做离线运算,还可以做流式运算以及迭代式运算。
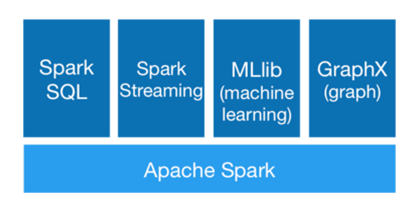
Spark 组成---大一统软件栈
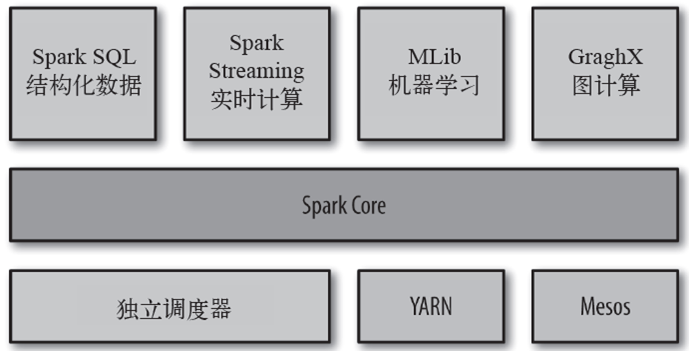
Spark Core
● Spark Core 实现了Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。
● RDD(resilient distributed dataset,弹性分布式数据集)的API 定义。RDD是一个抽象的数据集,提供对数据并行和容错的处理。初次使用RDD时,其接口有点类似Scala的Array,提供map,filter,reduce等操作。但是,不支持随机访问。刚开始不太习惯,但是逐渐熟悉函数编程和RDD 的原理后,发现随机访问数据的场景并不常见。
Spark SQL
● Spark SQL 是Spark 用来操作结构化数据的程序包。
● Spark SQL 直接兼容Hive SQL。
● 多数据源(Hive表、Parquet、JSON等);Spark SQL 可以操作Hive表,可以读取Parquet文件(列式存储结构),可以读取JSON文件,还可以处理hdfs上面的文件。
● SQL与RDD编程结合使用。
● 从Shark演变到Spark SQL。
Spark Streaming
● Spark 提供的对实时数据进行流式计算的组件。
● 微批处理(Storm、Flink)—从批处理到流处理
Spark MLlib
● Spark 提供的包含常见机器学习(ML)功能的库。
● 分类、回归、聚类、协同过滤等
● 模型评估、数据导入等额外的支持功能
● Mahout(Runs on distributed Spark, H2O, and Flink)
GraphX
● GraphX是Spark 提供的图计算和图挖掘的库。
● 与Spark Streaming 和Spark SQL 类似,GraphX 也扩展了Spark 的RDD API,能用来创建一个顶点和边都包含任意属性的有向图
● GraphX还支持针对图的各种计算和常见的图算法。
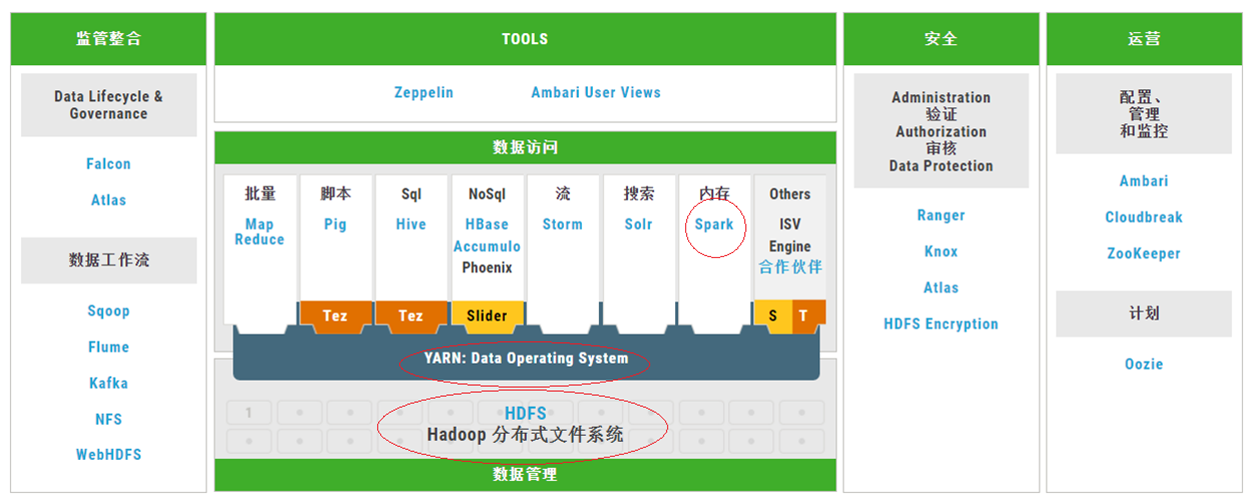
Spark与Hadoop的关系
Spark与Hadoop的关系---青于于蓝
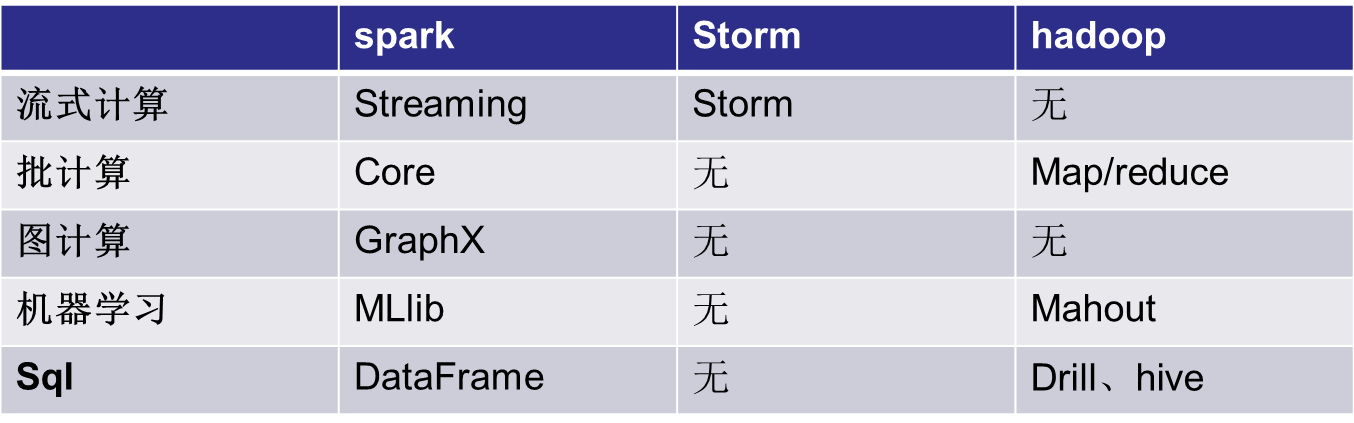
Spark与Hadoop的关系---相辅相成
Spark的竞争对手---Flink
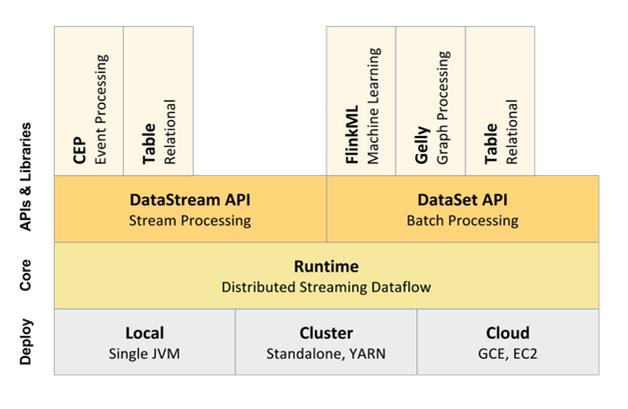
● Flink是先有流处理后有批处理
Spark的竞争对手---Storm/JStorm

● Storm仅限于流计算(topology)
● JStorm参照Flink改进了Storm
Spark的竞争对手---Hadoop3.x


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









