



 本文深入解析MySQL的架构组成,包括客户端和服务端模块,详细介绍连接层、SQL层和存储引擎的功能及工作流程,帮助读者理解MySQL如何高效处理数据。
本文深入解析MySQL的架构组成,包括客户端和服务端模块,详细介绍连接层、SQL层和存储引擎的功能及工作流程,帮助读者理解MySQL如何高效处理数据。
本篇主要介绍mysql有哪些部件组成,及部件的作用,mysql是如果完成对数据的操作的
MySQL大体结构
mysql分为客户端(不属于mysql的一个模块)、服务端两大模块
- 客户端:PHP、Navicat等其他
- 服务端:
1. 连接层(线程连接的处理,对程序连接的管理,用户密码的校验)
2. sql层(sql执行的部件):解析器、优化器等,对SQL的语法及重构、优化、加载索引信息、解析SQL、优化SQL语句等
3. 存储引擎:innodb 、myisam等,优化器得到最优的SQL语句之后,会通过存储引擎的api的接口从磁盘中查取数据,通过存储引擎返回结果,在通过线程返回给客户端。
MySQL的连接层
客户端或者应用程序通过接口(如:ODBC,JDBC)来连接MySQL,最先连接处理的就是连接层,连接层 包括通信协议,线程处理,用户名密码认证三个部分,通信协议负责检测客户端版本是否与服务端 兼容,线程处理是指每一个连接请求都会分配一个对应独立的线程,用户名密码认证创建的账号和 密码,以及host主机授权是否可以连接到mysql服务器
作用:与客户端(用户)进行交互
流程:
-
通信协议,通信协议负责检测客户端版本是否与服务端 兼容
-
连接之后,首先对用户密码进行校验,失败会抛出异常
-
对于检验之后的连接进行线程分配管理。 对于这些连接,mysql会分配一些线程进行管理。
show VARIABLES like "%MAX_CONNECTIONS%" #查询最大连接 show PROCESSLIST #查询当前连接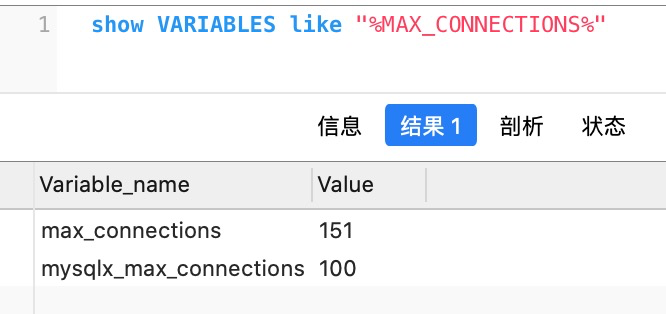
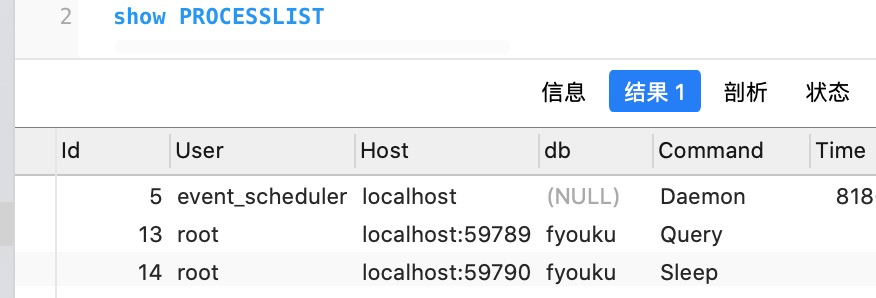
注意:当执行完一次查询之后,再次执行show PROCESSLIST,发现上次的查询看不到,这是因为mysql默认是短连接。
对于连接也分长短之分,短连接是mysql默认的一种方式,查询之后,短连接就会进入睡眠状态,也就是关闭连接,而长连接在完成一次sql的查询之后而不会立马关闭,它会有一个时长,默认为8小时,这可以时间段内,可以不停的复用这个连接。为什么用户多了,查询就慢了?
原因是连接太多,假设默认连接是100,实际有1000个访问量,mysql会有个短暂的延迟,会等前面的短连接结束了之后,后面的一些连接才能继续的处理,但是不会阻塞,默认的连接完全可以满足需求。 -
然后对用户进行变的权限的验证,mysql对于权限的验证卡的严格,host字段可以指定连接mysql连接的ip。
比如:当我们在虚拟机上面安装好mysql之后,在本机的Navicat去连接,发现连接不上,就是因为权限问题。需要对root用户的host修改为’%’,表示全部的IP都可以连接,然后在刷新权限。select user,host,plugin from mysql.user;
mysql8.0之后mysql的加密规则进行了一次更改。
plugin表示mysql用户密码的加密规则会有mysql_native_password和caching_sha2_password(mysql8新出的加密规则),目前两种规则都支持,低版本的navicat是不支持caching_sha2_password的加密规则的,所以也会连接不上。
4.返回连接的id
SQL层解析器
sql层的sql语句接口:接收到由连接层传递过来的SQL语句
sql层包含权限判断,查询缓存,解析器,预处理,查询优化器,缓存和执行计划;
- 权限判断可以通过审核用户有没有访问某个库,某个表,或者表里某行的权限。
- 查询缓存通过query cache进行操作,如果数据在query cache中,则直接返回结果给客户端
- 查询解析器针对sql语句进行解析,判断语法是否正确,并生成解析器
- 预处理器解决解析器无法解析的语义
- 优化器对sql语句进行改写和相应的优化,例如:对连接表重排序,对外连接转内连接,代数等价 法则,计算和减少常量表达式,自查询优化,早期终结,相等传递等,并生成最优的执行计划,然 后就可以调用程序的API接口,通过存储引擎层访问数据;
- 先判断SQL语句的类型(query(select)、dml(insert、update、delect)、ddl、status(状态的查询、show status)等)
- 假设是query(本篇以查询语句为例),先走查询缓存
8.0之后移除了查询缓存,先判断查询缓存是否开启,如果开启查询缓存,如果命中,直接返回结果,反之,则是继续执行到解析器。
在解析一个查询语句前,如果查询缓存是打开的,那么 MySQL 会检查这个查询语句是否命中查询缓存中的 数据。如果当前查询恰好命中查询缓存,在检查一次用户权限后直接返回缓存中的结果。这种情况下,查 询不会被解析,也不会生成执行计划,更不会执行。MySQL将缓存存放在一个引用表 (不要理解成table,可 以认为是类似于 HashMap 的数据结构),通过一个哈希值索引,这个哈希值通过查询本身、当前要查询的 数据库、客户端协议版本号等一些可能影响结果的信息计算得来。所以两个查询在任何字符上的不同 (例如 : 空格、注释),都会导致缓存不会命中
- 解析器分为SQL解析器、语法解析器
- SQL解析器:根据查询的SQL语句将SQL划分为小token,将SQL语句把每一个符号分解为一个一个的token,比如select, *, from, user, where ,id , > ,10 , and ,( , age , > ,21 ,or , sex , = , 0,) ,会以这样的方式将SQL语句进行划分并交给语法解析器。
- 语法解析器:分析语法,如果有问题会抛出异常,语法解析器得到前面分解的token,根据token去进行排列组合,比如对关键字and or 重新排序成解析数,根据where条件中的关键词来进行组合,排列成这种解析数方便查询,然后在传递到优化器,根据条件、索引、数据等进行重组、优化 排列组合成解析数。
优化器的执行
优化器得到解析数,根据解析数去选择最优的执行计划,(这个计划并不一定是最优的)
- 获取表的结构信息(字段信息、字段的类型、数据存储的位置、索引信息) 查询表的信息,如果是join,同时获取两种表的信息
- 根据解析数进行条件过滤,过滤掉一些没有意义的查询 比如:where 1 = 1
- 根据索引信息来判断执行计划,根据不同的索引信息组成执行计划并做出对比,选择mysql认为最优的执行计划
- 执行这个计划 根据最优的计划(上面提到的索引及条件等来过滤)
SQL执行流程
优化器得到最优的sql语句之后,会通过存储引擎的api的接口从磁盘中查取数据,通过存储引擎返回结果, 在通过线程返回给客户端,返回结果是在连接层创建的那一天连接去返回,如果开启查询缓存,同时也会缓存查询结果。
MySQL 整个查询执行过程,总的来说分为 5 个步骤 :
- 客户端向 MySQL 服务器发送一条查询请求
- 服务器首先检查查询缓存,如果命中缓存,则立刻返回存储在缓存中的结果,否则进入下一阶段
- 服务器进行 SQL解析、预处理、再由优化器生成对应的执行计划
- MySQL 根据执行计划,调用存储引擎的 API来执行查询
- 将结果返回给客户端,同时缓存查询结果


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









