import requests
from bs4 import BeautifulSoup
import re
import json
import pymongo
from fake_useragent import UserAgent
import logging
# ===== 配置区域(需自定义)=====
# 1. 目标网站配置
CINEMA_URL = "https://www.maoyan.com/cinemas" # 影院列表页URL
MOVIE_URL = "https://www.maoyan.com/films" # 电影列表页URL
# 2. 请求头配置(需定期更新)
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.5845.97 Safari/537.36 Core/1.116.561.400 QQBrowser/19.6.6720.400', # 自动生成随机UA
'Accept-Language': 'zh-CN,zh;q=0.9',
'Referer': 'https://www.maoyan.com/',
'Cookie': 'uuid_n_v=v1; uuid=BDB3B1E0B16C11F0AED3E77F85110EC565127470B41941D5A1E4C496D6BDC1B4; _ga=GA1.1.2021055819.1761374157; _lxsdk_cuid=19a1a14b973c8-0a675a3b0d8f2d-7c1c7d75-1bcab9-19a1a14b974c8; _lxsdk=BDB3B1E0B16C11F0AED3E77F85110EC565127470B41941D5A1E4C496D6BDC1B4; recentCis=96; _csrf=c65461ba7598380e653efa3bb95396de51c75a6d278c59aa353aa73ebe2f48b8; Hm_lvt_e0bacf12e04a7bd88ddbd9c74ef2b533=1761374157,1761394826; HMACCOUNT=4D0C82DEA7045FB0; ci=96; hotMovieIds=1489329,1416590,1500265,1547296,1535808,1515448,1519878,1207331,1518527,1526767,1499675,1228042,1505776,336673,1523868,1523743,1519992,257609,484024,1505571,1529761,1457158,1298226,1454962,1573266,1515498,1531082,1522657,1309038,1528519,3232,1531012,1528598,1568020,7284,120028,339532,2265,32124,1509529,1378846,1500340,1523963,4476,1295,1340,1464734,1297975,1446508,59452,285540,233631,20394,1221032,1461072,1498162,1499719,1414991,1520846; old-moviepage-ci=96; _ga_WN80P4PSY7=GS2.1.s1761394825$o4$g1$t1761397715$j60$l0$h0; Hm_lpvt_e0bacf12e04a7bd88ddbd9c74ef2b533=1761397734; __mta=248429112.1761374157494.1761397186704.1761397734333.7; _lxsdk_s=19a1b501b48-003-15c-f73%7C%7C26' # 如需登录则配置
}
# 3. 数据库配置(MongoDB示例)
MONGO_URI = "mongodb://localhost:27017/"
DB_NAME = "movie_ticket_system"
# =============================
# 初始化日志和数据库
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def get_html(url):
"""通用网页获取函数"""
try:
response = requests.get(url, headers=HEADERS, timeout=10)
response.raise_for_status()
# 动态编码检测(重要!)
response.encoding = response.apparent_encoding
return response.text
except Exception as e:
logger.error(f"请求失败: {url} | 错误: {str(e)}")
return None
def parse_cinemas(html):
"""
解析影院信息(需根据目标网站结构调整CSS选择器)
返回影院字典列表
"""
cinemas = []
try:
soup = BeautifulSoup(html, 'lxml')
# === 需自定义的选择器区域 ===
items = soup.select('div.cinema-item') # 示例选择器
for item in items:
cinema = {
"name": item.select_one('h3.name').text.strip(),
"address": item.select_one('p.address').text.strip(),
# 提取电话(正则示例)
"phone": re.search(r'\d{3,4}-\d{7,8}', item.text).group(0) if re.search(r'\d{3,4}-\d{7,8}',
item.text) else None,
"services": [service.text for service in item.select('span.service-tag')]
}
cinemas.append(cinema)
# ========================
return cinemas
except Exception as e:
logger.error(f"影院解析失败: {str(e)}")
return []
def parse_movies(html):
"""
解析电影信息(需自定义选择器)
返回电影字典(ID为键)
"""
movies = {}
try:
soup = BeautifulSoup(html, 'lxml')
# === 需自定义的选择器区域 ===
items = soup.select('div.movie-item') # 示例选择器
for item in items:
movie_id = item['data-id'] # 假设有data-id属性
movie = {
"title": item.select_one('h2.title').text.strip(),
"rating": float(item.select_one('span.score').text),
"duration": item.select_one('span.duration').text,
"genres": [genre.text for genre in item.select('span.genre')]
}
movies[movie_id] = movie
# ========================
return movies
except Exception as e:
logger.error(f"电影解析失败: {str(e)}")
return {}
def save_to_mongodb(data, collection_name):
"""数据存储到MongoDB(含空数据检查)"""
try:
if not data or (isinstance(data, list) and len(data) == 0):
raise ValueError("空数据禁止入库")
client = pymongo.MongoClient(MONGO_URI)
db = client[DB_NAME]
collection = db[collection_name]
if isinstance(data, list):
result = collection.insert_many(data)
else: # 字典类型
result = collection.insert_one(data)
logger.info(f"成功插入{len(result.inserted_ids) if isinstance(data, list) else 1}条数据")
return True
except Exception as e:
logger.error(f"数据库操作失败: {str(e)}")
return False
def main():
"""主执行函数"""
# 爬取影院
cinema_html = get_html(CINEMA_URL)
if cinema_html:
cinemas = parse_cinemas(cinema_html)
if cinemas:
save_to_mongodb(cinemas, "cinemas")
# 爬取电影
movie_html = get_html(MOVIE_URL)
if movie_html:
movies = parse_movies(movie_html)
if movies: # 确保movies是字典而非集合
save_to_mongodb(movies, "movies")
if __name__ == "__main__":
main()
这是我的源码,报上面我发你的错误,我应该怎么修改





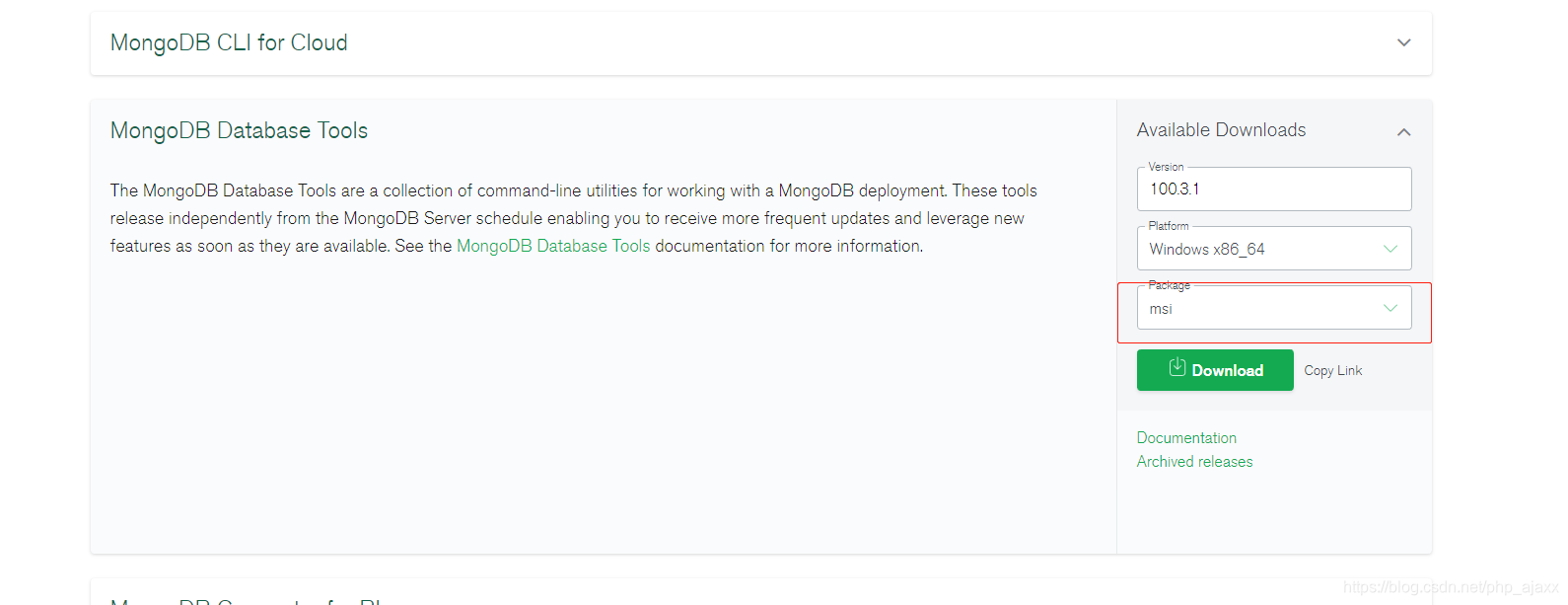
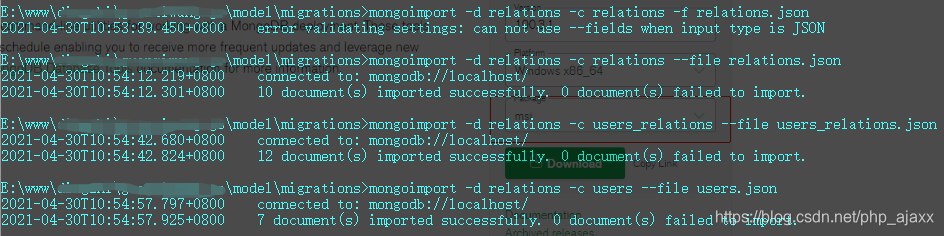
 本文指导如何在Win10上安装MongoDB工具包,包括从官网下载、指定安装路径及设置环境变量,确保mongoimport工具可用。
本文指导如何在Win10上安装MongoDB工具包,包括从官网下载、指定安装路径及设置环境变量,确保mongoimport工具可用。
 5100
5100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























