




 本文探讨了三种资源下载方法的优缺点:直接路径可能导致浏览器误解析,通过控制器操作同步或异步请求以返回下载资源,强调了如何创建流、处理字节数组并设置下载响应头。
本文探讨了三种资源下载方法的优缺点:直接路径可能导致浏览器误解析,通过控制器操作同步或异步请求以返回下载资源,强调了如何创建流、处理字节数组并设置下载响应头。
1,直接给一个资源路径
弊端:1.如果浏览器能解析会打开资源而不是下载,需要用户手动下载
2,不方便统计下载数量
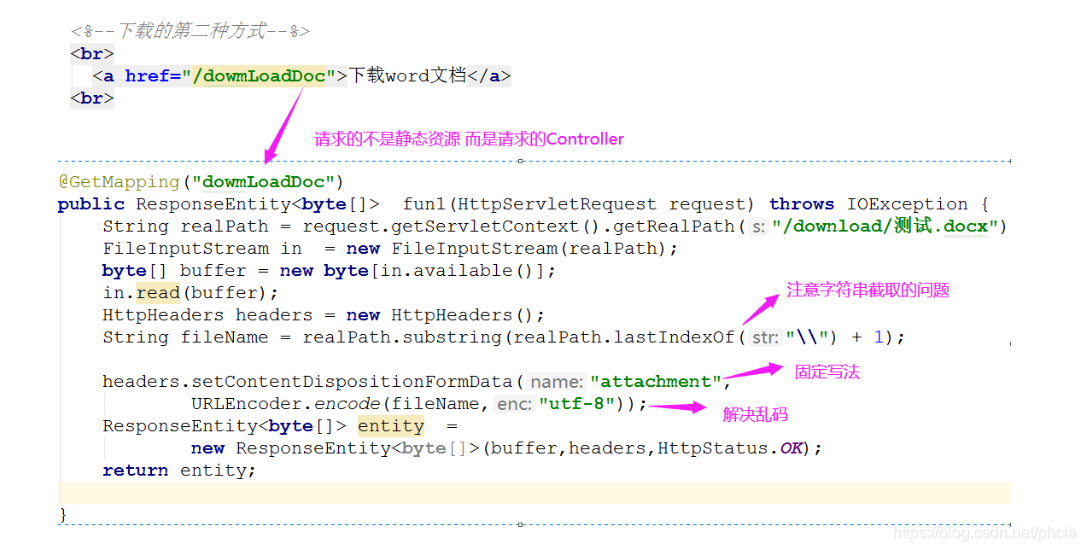
2,发送请求给contorller(只适用于同步请求,异步请求无法下载,只能拿到数组)
1,获取资源路径
2,创建流FileInputStream
3,创建byte[] 数组
4,写入数组返回前端
5,设置相应头
6,调用前端下载
3,与方法2大致相同,但是可以适用于异步请求
请求的方法无返回值,储存流的byte[]数组以响应的方式写出去
response.getOutputStream().write(byte[]数组),前端再调用浏览器下载即可

















 706
706

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









