



2010年9月23日,Facebook遭遇了迄今为止最严重的宕机事件之一,网站关闭了4个小时。为恢复工作,不得不让FB下线,影响了10亿用户。
在事后的故障报告中提到:
今天,我们修改了一个错误的配置,每个客户端都看到这个错误的配置,然后试图更新它。因为更新数据需要查询数据库集群,集群很快就被每秒数十万次的查询拖垮。
简单来说,是某个缓存配置失效,大量请求回源到数据库,导致DB压力过大,整体服务不可用,上游重试,整体雪崩。
在高并发系统中,我们或多或少都遇到过类似的缓存穿透到DB,导致压力过大雪崩的问题。
一般是由于多个线程试图并行访问缓存,如果缓存值不存在,那么线程将会同时尝试从数据库获取数据。导致数据库CPU飙升,发生崩溃,对上游表现为超时。上游服务收到超时这种网络错误后,会进行重试,从而放大问题,恶性循环继续。
那怎么解决这种缓存穿透导致的雪崩问题呢?
在止损角度来说有两种方式:防止和减轻。
防止雪崩
防止雪崩最简单的方法,就是增加多级的缓存。
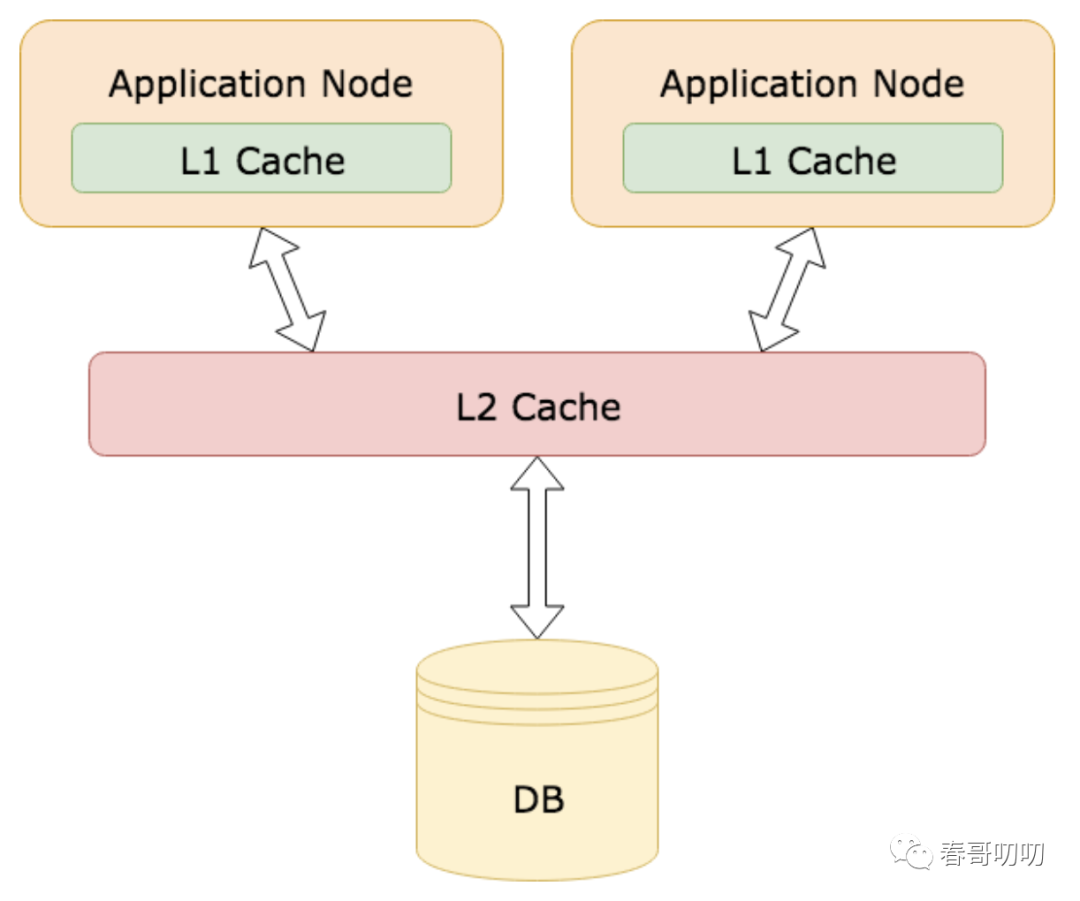
L1 Cache是内存缓存,L2 Cache是远程缓存。
这样好的方式是可以将缓存不存在与失效情况做两种独立的控制,不至于所有流量同时大量涌入DB层。
有一点需要注意,内存缓存需要控制大小,做好淘汰,不然会引起频繁GC问题。
第二种方式是加锁。
缓存并发的本质在于并发,也就是同一时刻对于某个竞态资源的争抢,多线程抢夺共享资源。
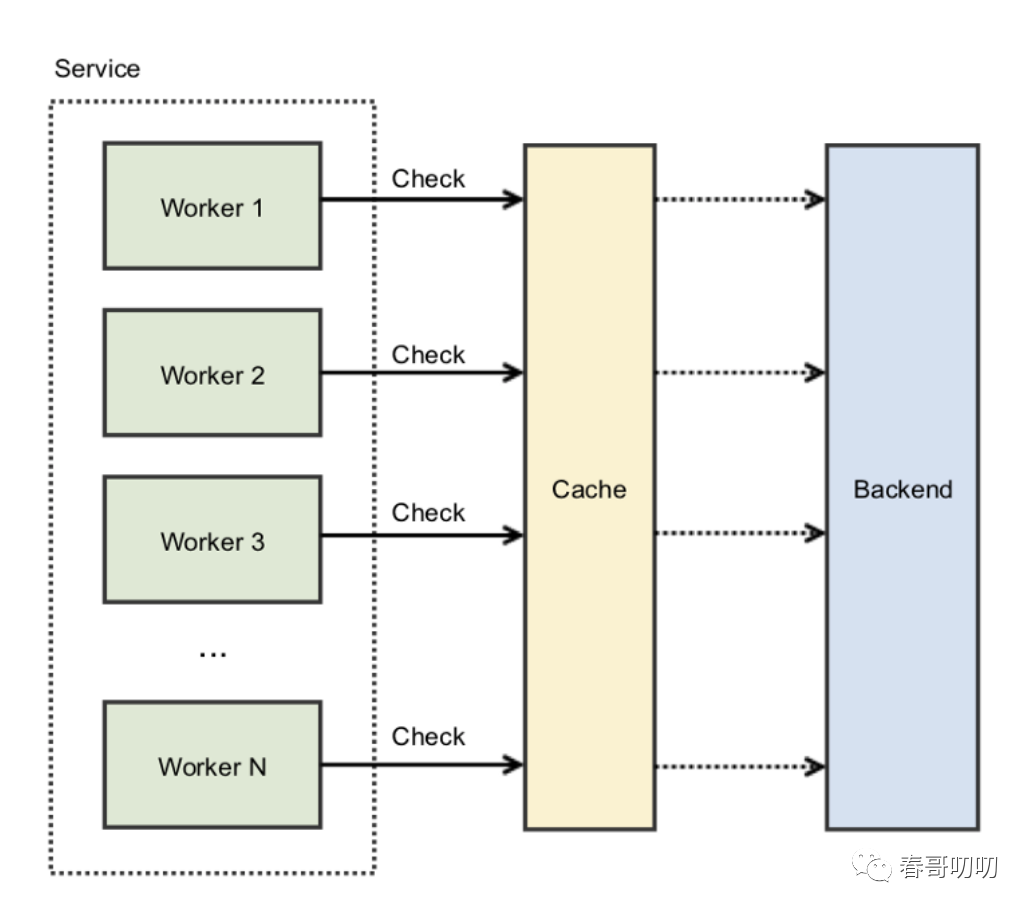
在高并发场景下,为解决这种资源被争抢的方式一般是加锁。进程内锁解决的是线程的并发资源争抢;分布式锁解决的是分布式进程对资源的争抢。
为具备更高的并发吞吐能力,控制锁粒度是我们需要关注的,通过对某个缓存键加锁,每次只有一个调用者可以访问这个缓存键。其他并发争抢资源的进程必须等到锁的释放。
这里也会有个问题,那些来争抢锁,但是没有获得锁的线程应该怎么处理呢?
一种方式是让线程轮询获取锁,但会造成繁忙的等待。
另一种方式是让线程sleep一段时间,锁释放后发起notify,需要注意惊群问题。
还有一种方式是缓存一个空值,不需要上层进行自动的重试,并发线程里面放一个线程穿透去db获取新值。
我一般的做法是采用双key+防御限流的方案。将多个key失效分散开,极端情况兜底保护db。
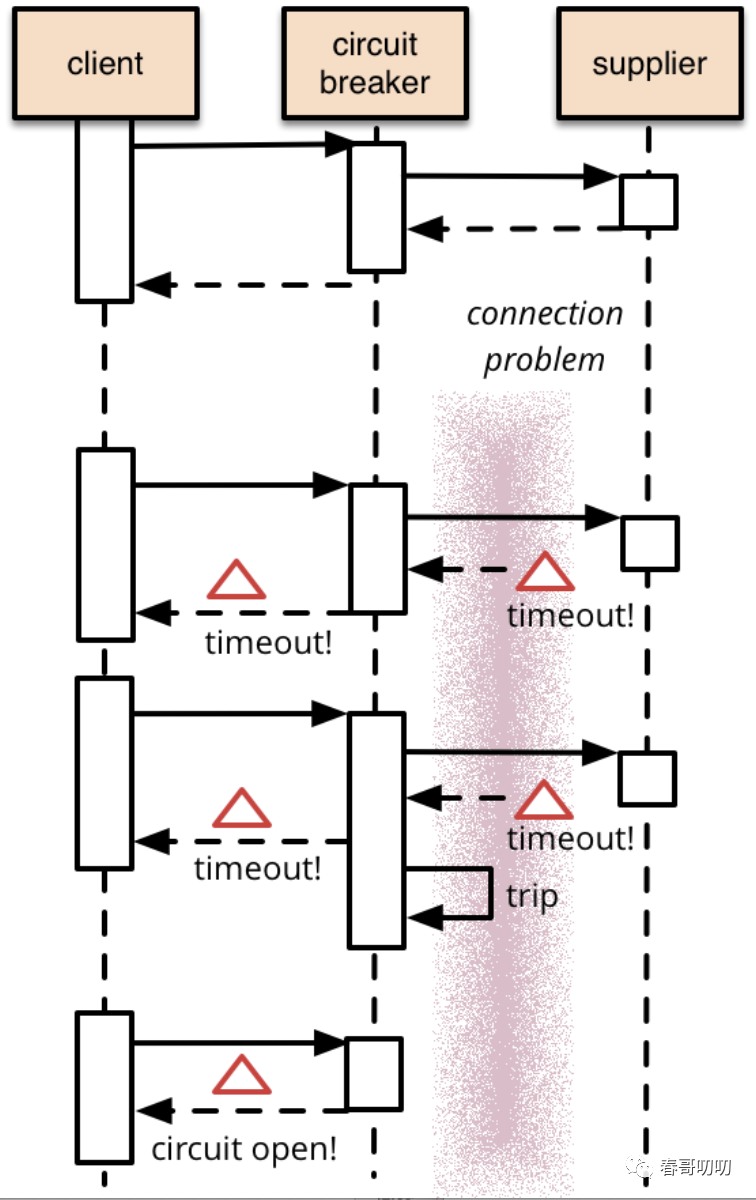
防御限流就是采用断路器,断路器是反应式的,所以它们无法防止宕机,不过它们可以防止连锁故障的发生。当事态失控时,它们提供了一个终止开关。如果 Facebook 使用了熔断机制,就可以避免让整个网站瘫痪下线。

















 328
328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









