




 本文深入探讨MapReduce的三大核心思考:数据读取机制、输出结果解析与分区排序原理。详细解析不同数据格式的处理方式,揭示MapReduce如何将数据从Map阶段高效传输至Reduce阶段,并阐述数据分区、排序及归并排序的全过程。
本文深入探讨MapReduce的三大核心思考:数据读取机制、输出结果解析与分区排序原理。详细解析不同数据格式的处理方式,揭示MapReduce如何将数据从Map阶段高效传输至Reduce阶段,并阐述数据分区、排序及归并排序的全过程。
mapreduce先进行3大思考
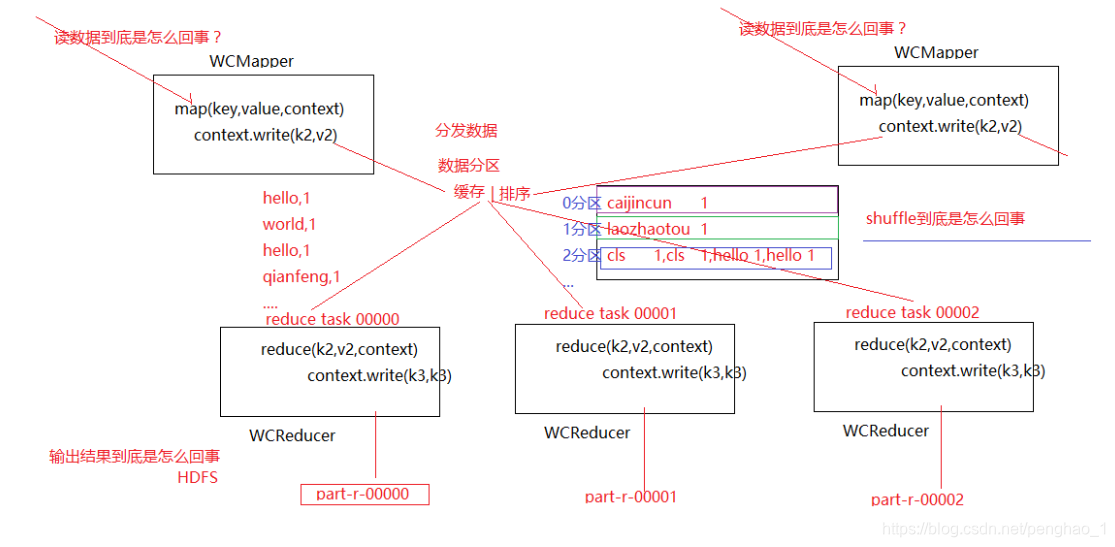
读数据到底是怎么读的?
map阶段:怎么读的数据,现在是text文件,如果xml文件(一个个节点),或者其他文件呢,则处理方式和文本文件不一吧,或者流式的数据呢,压缩的文件呢,转过码的文件呢,文件的格式肯定有很多种,不可能只有文本文件一种,那到底是如何处理的呢?
----------------------------------
输出结果到底是怎么回事?
reduce阶段:reduce可以有多个,多个reduce最终输出的数据对应的就是有顺序的编号文件,part-r-0000...part-r-000*,reduce设置为1的时候只有一个输出,但是设置多个的时候其文件好像是有规律的,为什么会输出这些文件呢?文件输出为什么会这么规律?输出的文件能不能输出到其他的存储介质呢?
累计每一个单词的数量,累计完后直接写context.write那么数据是怎么跑到里面的呢,而且设置了reduce数量后,还被拆成几个文件?为什么拆成几个文件呢?被拆的文件其内部是如何处理的呢?还有为什么被拆成的东西都不一样呢?而且其内部还是排序的呢,是有序的呢?
-----------------------------
分区怎么排序呢?
map类和reduce类好像没有任何联系,为什么程序在集群上,数据能从map跑到reduce呢?输出那么多文件,map输出的数据怎么能够分给reduce呢?分的规律是什么?还有一个排序的问题,中间什么时候做的排序?
MapReduce的执行流程,数据收集到缓存里面,问题是在缓存里面做了什么?要做分区,做排序,按什么原则做的分区,做的排序呢?为什么相同k的作为一组,调用一次呢?数据放在缓存里面,而且做了分发数据(每一部分数据到每一个reduce中,如果不是分发,不可能各个reduce都有数据的,肯定是按照某种规律做分发数据,使得每个reduce都有数据,也就是数据的分区,分成不同的区,reduce拿不同分区的数据,1号任务选1号文件,2号任务选2号文件...)
还有一个就是文件内部的内容按着字典顺序输出,肯定是排序了,数据在缓存里进行了排序,速度也是很快的,分区加排序后,就分发给不同的reduce,每一个reduce接到的任务对应的分区中,每一个map最后都会变成一个文件,顺序是按照偏移量的顺序,往外输出,中间的过程间这个过程就是洗牌的过程,
分块是物理上的分开,分成不同的小块存储在不同的地方
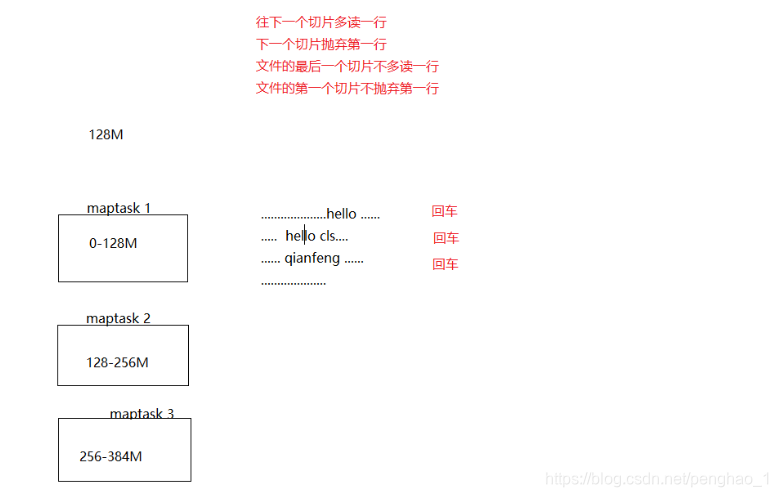
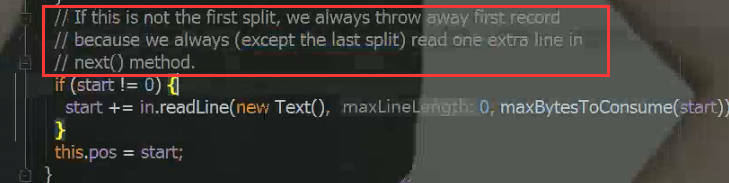
分片就是一个数据的范围,数据还是一个完整的文件,只是读的时候去做定位,片的数据都是maptask在处理,虽然每一个位置都不一样。但是如果刚刚好128M在一个单词中间split的,是怎么处理的呢?怎么读取的呢?是一行一行的读,每一个行一个回车符。
分片细节
map的输出的时候是:最终得到的文件是一整个大的文件,包含所有的数据,但是文件内部,分成一个一个的分区
1、用一个输出的收集器(输出集合outputcolletor),但是它只是负责收集而已,收集到环形缓冲区。数据是压弹式的。
2、如果放满了,就表示内存不够,就要用磁盘来装,此时,用到一个溢出器(spiller),其实溢出器也是一个线程,归maptask生成的一个线程,将溢出的数据溢出到磁盘。(在溢出器里面要对数据进行分区,分区默认采用的是hashPartioner散列。排序呢是在缓冲区里面排,默认采用快排算法)
3、数据区存满了,还有源源不断的数据进行存,输出一直在进行,那么此刻数据将会暂时切换到保留区进行存储数据。而数据区的数据写到磁盘
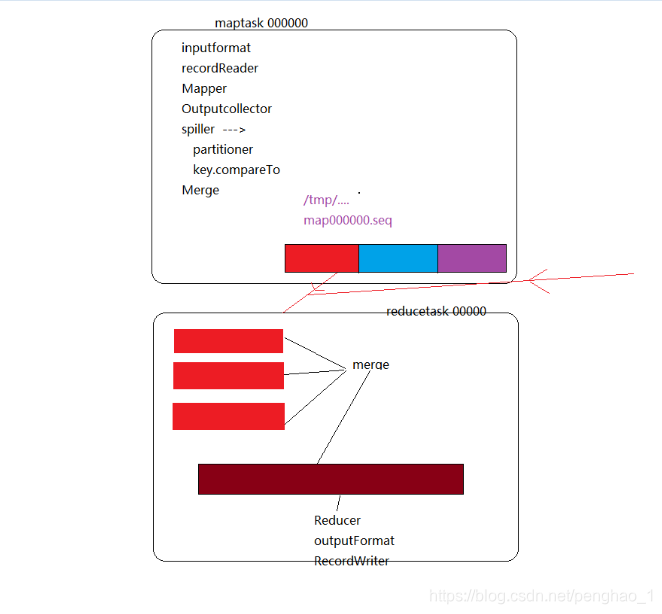
4、分区和快排后,输出文件到磁盘,同样会有一个Index的索引文件,记录分区的偏移量,这是一个文件的时候,如果是多个文件,就会多次溢出,文件内是有序的,但是文件与文件之间是无序的,所以呢需要归并排序(merge),合并成一个大文件,文件的内部是有分区的,有序的 (归并排序是局部使用内存,一部分一部分排序,最后还是落地在磁盘,两两之间合并成一个中型的,最后合并成大型的文件。也就是map端最后的输出)
运行全流程
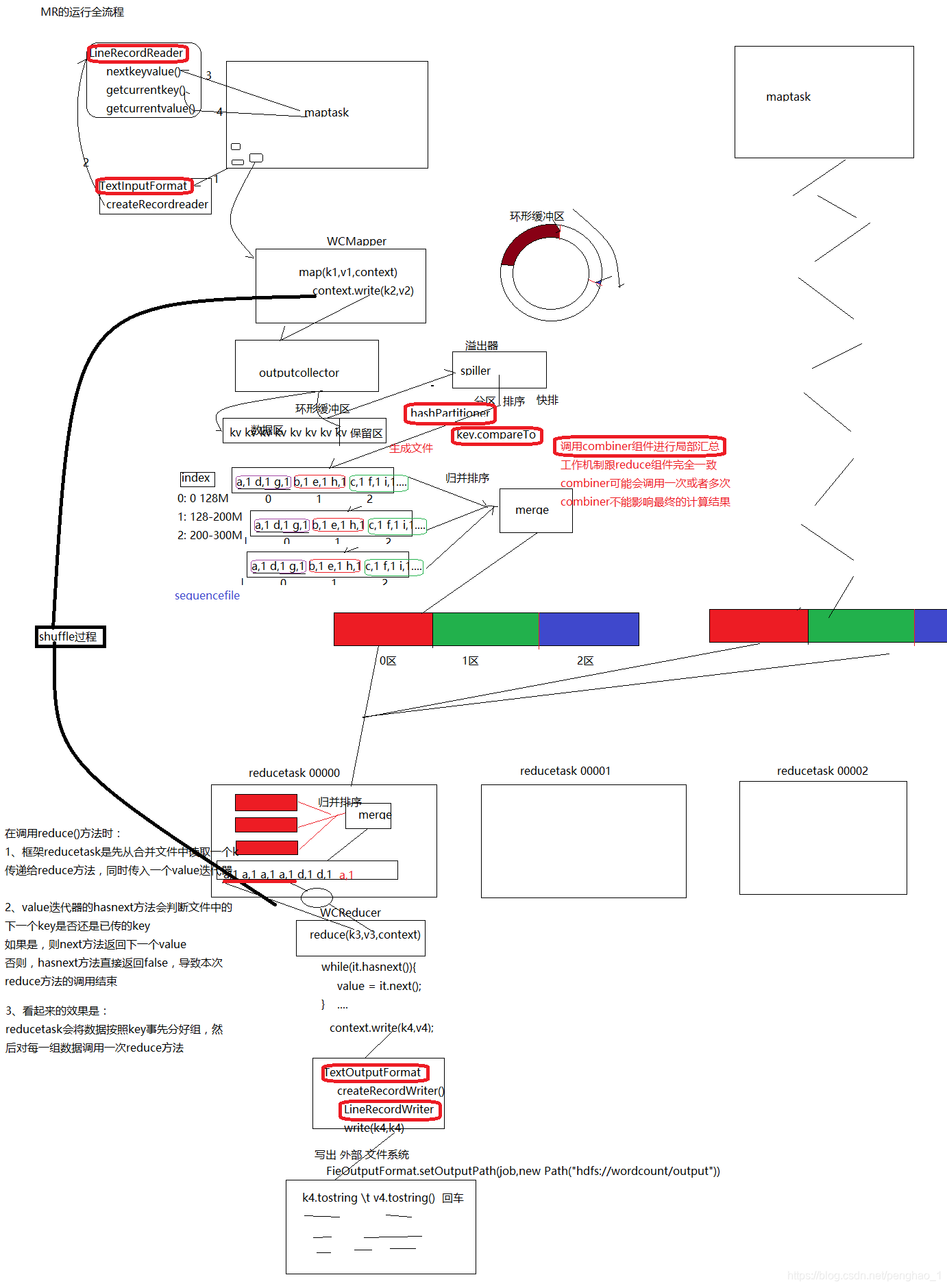
Reduce拉去后,数据内部是有序的,外部是无序的,而且不存在分区。
调用Reduce方法的条件是,相同key的(key,value)组成一组,所以要做一个归并排序,合并成一组,组内是有序的大文件
分区的主要目的就是将数据发送到不同的Reduce端
combiner也是用户可干预组件,可以自定义,是早于map输出执行的,combiner其实也是继承Reduce的,它的输入接着的是map的输出
个人理解的读书写字场景:首先要有一本书(就是文件),需要人来读,就要去找一个人来读(就是CreateRecordReader),人来读书了,是一行行的方式去看下去的(就是LineRecodeReader),准备开始读第一行的文字了(就是nextkeyvalue),当读取第一个字的时候(就是getcurrentKey,getcurrentValue) 。读取的文字就会进入到大脑(就是context.write(k2,v2)),大脑就会不断的记录读取的信息,比如进入左脑(是数据区)右脑(是保留区),当读取很多数据的时候,大脑会有种累的感觉(就当做是溢出了),这时候读者的大脑要快速对刚度过的信息进行分析归并排序(就是归并排序),排完序后,(就是map阶段结束),读者再次对整理完的信息再次理解与整理,方便记忆(就是reduce的归并排序),这个时候就开始累积刚刚读的那个字和那个字是相同的,整合为一组,知道将不同的键值对统计出来(就是reduce过程),知道结果了,要准备写到纸上吧的动作吧(就是TextOutputFormat),写当然要读者写了(createRecordWriter),是一行一行的方法写出来的(LineRecordWriter) 最后写到纸上呈现了出来。
mr的运行概略
groupingcomparator的过程

map端的输出:首先要考虑key用什么,value用什么,key相同的才能调用同一个Reduce方法
Reduce端:
随着业务的复杂度,字段很多,则将他们包含起来整成一个类,框架的功能是分区+排序,这里可以利用框架排序法,进行倒叙排金额,如果在调用Reduce方法前,相同订单已经按照金额的倒叙已经排好了,迭代器是如何做的,如何调用Reduce:Reducetask读取文件中的第一个key,传给Reduce方法的一个key,是一个迭代器,直接一个key就搞定了,就是最大值,完全利用了框架的特性,Reduce里面不用再比较。排序是针对key,也就是对自定义的类orderBean进行排序,然后中间经过shuffle过程
1、排序之前按订单号进行分区,hashpatitioner要自定义,要实现一个getPartition(),按照OrderId进行分区才可以保证同一个订单分到一个分区中
2、排序时,key.compareTo()方法进行排序,排序是对分区内的所有数据进行排序,首先先对订单号orderId排序,再对金额倒叙
3、现在这些都是类,都是orderBean,迭代器对类比较是不一样的,因为类比较的是内存地址,内存地址肯定不一样,所以改用分组比较器groupingcomparator,用于比较分组的,判断是否能分为一组,实现的是compare方法(如o1.orderId.equals(o2.orderId))只要订单号相同,将他们强制分为一组,也就是人为干预的过程groupingcomparator的作用是欺骗Reducetask的迭代器,让它认为只要orderId,则两个对象就相同就能分到同一个Reduce里面
分片的细节--冗余

最后一个切片可以是最大切片的1.1倍,10%的冗余


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









