




 本文详细介绍了Hadoop Yarn和MapReduce集群的配置,包括时间同步的重要性及步骤,如何处理Namenode的安全模式问题,以及动态增删节点的操作。在时间同步中,强调了ntpd服务的配置和批量同步的实现。在安全模式方面,讲解了如何解决和避免该问题。最后,文章阐述了动态增删节点的静态和动态方法,确保集群稳定运行。
本文详细介绍了Hadoop Yarn和MapReduce集群的配置,包括时间同步的重要性及步骤,如何处理Namenode的安全模式问题,以及动态增删节点的操作。在时间同步中,强调了ntpd服务的配置和批量同步的实现。在安全模式方面,讲解了如何解决和避免该问题。最后,文章阐述了动态增删节点的静态和动态方法,确保集群稳定运行。

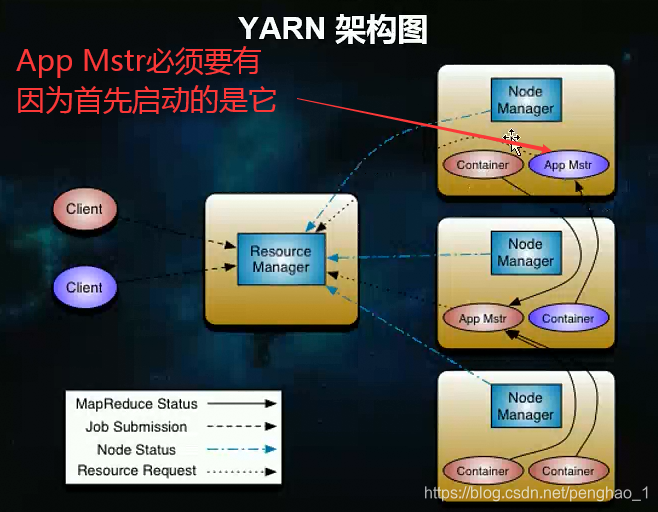


yarn集群配置与任务调度
yarn集群的安装配置
vi $HADOOP_HOME/etc/hadoop/yarn-site.xml
<!--指定yarn的rm所在的主机名-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop0001</value>
</property>
<!--指定mapreduce使用shuffle过程-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定rm的内部通讯端口-->
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop0001:8032</value>
</property>
<!--指定调度队列的访问端口-->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop0001:8030</value>
</property>
<!--指定rm的资源调度的端口-->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop0001:8031</value>
</property>
<!--指定rm的超级管理员的访问端口-->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop0001:8033</value>
</property>
<!--指定rm的web ui的访问端口-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop0001:8088</value>
</property>
/mapred-site.xml 是指定跑的模式
vi $HADOOP_HOME/etc/hadoop/mapred-site.xml
<!--指定mapreduce的运行框架平台-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>The runtime framework for executing MapReduce jobs.
Can be one of local, classic or yarn.
</description>
</property>
<!--指定历史作业的内部通信端口(配置这个才能有操作日记写进来,否则找到不到操作日记的)-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop0001:10020</value>
</property>
<!--历史作业的web ui的监控端口-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoo 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 303
303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









