




 本文介绍了一个使用MapReduce实现的依赖执行案例,包括两个Job的设置与执行过程。首先通过GrepMyMapper过滤特定词汇,然后CountMapper统计剩余词汇出现次数,最后由CountReducer汇总结果。文章详细展示了如何使用Hadoop的JobControl进行Job之间的依赖控制。
本文介绍了一个使用MapReduce实现的依赖执行案例,包括两个Job的设置与执行过程。首先通过GrepMyMapper过滤特定词汇,然后CountMapper统计剩余词汇出现次数,最后由CountReducer汇总结果。文章详细展示了如何使用Hadoop的JobControl进行Job之间的依赖控制。
MapReduced的多个job依赖执行案例(这里是两个job)

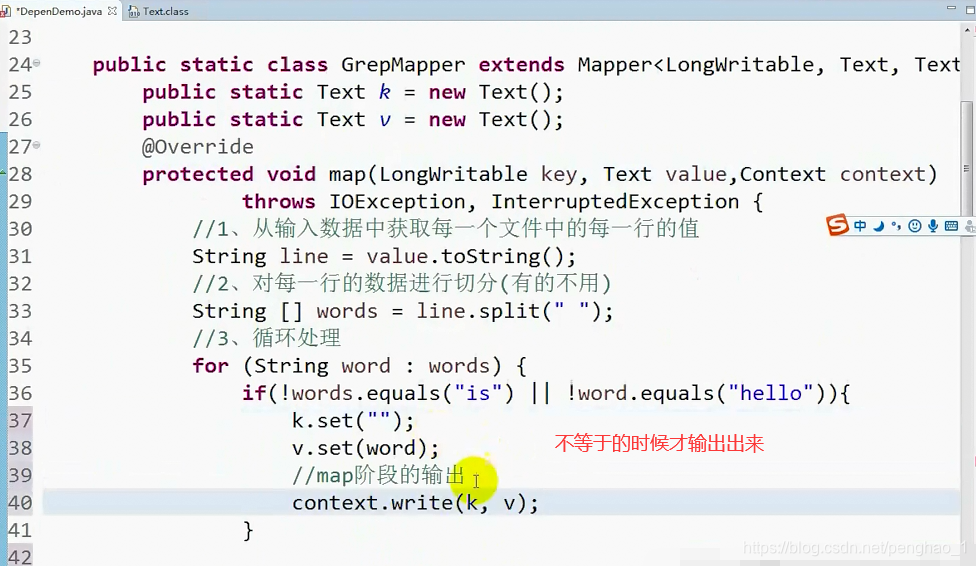
改了条件

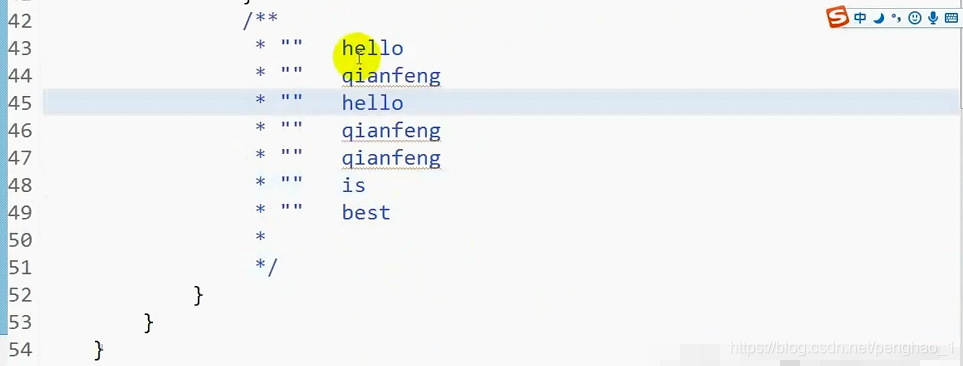

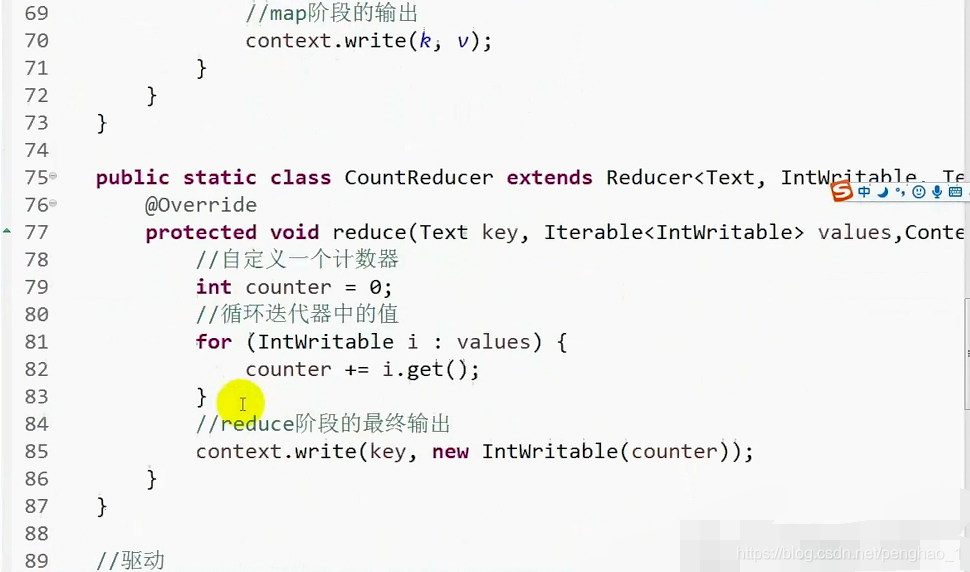
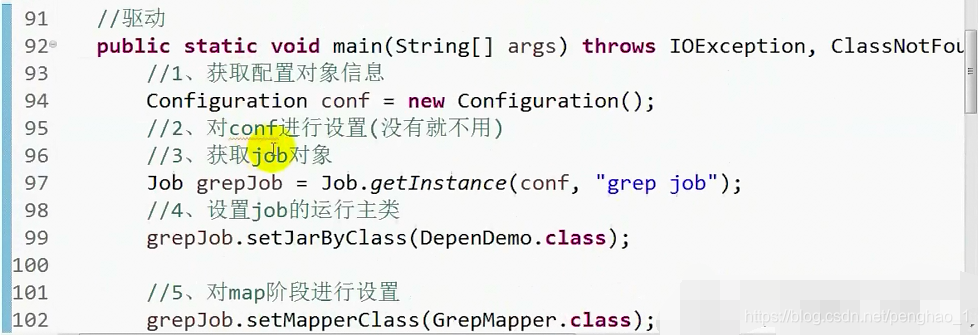


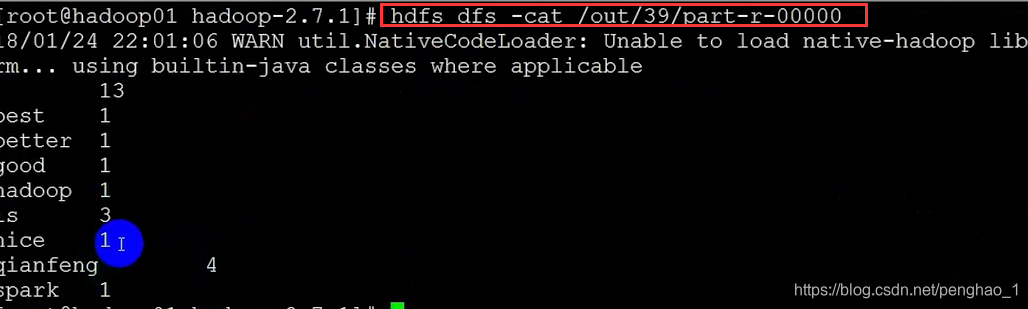
到此,依赖执行就已经OK了。
![]()

![]()
![]()
package qf.com.mr;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.jobcontrol.ControlledJob;
import org.apache.hadoop.mapreduce.lib.jobcontrol.JobControl;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 依赖执行
*
*/
public class DepenDemo {
public static class GrepMyMapper extends Mapper<LongWritable, Text, Text, Text> {
public static Text k = new Text();
public static Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1.从输入数据中获取每一个文件中的每一行的值
String line = value.toString();
// 2.对每一行的数据进行切分(有的不用)
String[] words = line.split(" ");
// 3.循环处理
for (String word : words) {
if (!word.equals("is") && !word.equals("hello")) {
k.set("");
v.set(word);
// map阶段的输出 context上下文环境变量
context.write(k, v);// 这个输出在循环里面 有一个输出一个
}
}
}
}
public static class CountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
public static Text k = new Text();
public static IntWritable v = new IntWritable();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
System.out.println("我能进来 ");
// 1.从输入数据中获取每一个文件中的每一行的值
String line = value.toString();
// 2.对每一行的数据进行切分(有的不用)
String[] words = line.split("\t");
// 3.循环处理
System.out.println("我能拆分 ");
for (String word : words) {
k.set(word);
v.set(1);
System.out.println(word);
// map阶段的输出 context上下文环境变量
context.write(k, v);// 这个输出在循环里面 有一个输出一个
}
System.out.println("我运行完了 ");
}
}
public static class CountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
// 1.自定义一个计数器
int counter = 0;
for (IntWritable i : values) {
counter += i.get();
}
// 2.reduce阶段的最终输出
context.write(key, new IntWritable(counter));
// 这个输出在循环外面 等统计完了这一个容器再输出
}
}
// 驱动
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1.获取配置对象信息
Configuration conf = new Configuration();
// 2.对conf进行设置(没有就不用)
conf.set("mapred.jar", "wc.jar");
// grepjob
// 3.获取job对象 (注意导入的包)
Job grepjob = Job.getInstance(conf, "grep job");
// 4.设置job的运行主类
grepjob.setJarByClass(DepenDemo.class);
// 5.对map阶段进行设置
grepjob.setMapperClass(GrepMyMapper.class);
grepjob.setMapOutputKeyClass(Text.class);
grepjob.setMapOutputValueClass(Text.class);
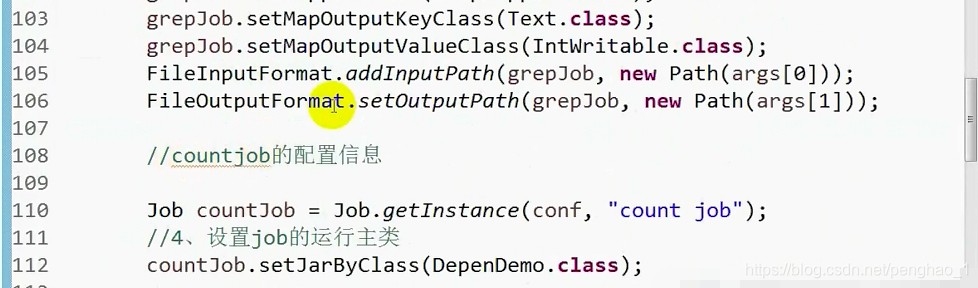
FileInputFormat.addInputPath(grepjob, new Path(args[0]));// 具体路径从控制台输入
FileOutputFormat.setOutputPath(grepjob, new Path(args[1]));
// =========
// countjob
Job countjob = Job.getInstance(conf, "count job");
countjob.setMapperClass(CountMapper.class);
countjob.setMapOutputKeyClass(Text.class);
countjob.setMapOutputValueClass(IntWritable.class);
System.out.println("我在运行");
FileInputFormat.addInputPath(countjob, new Path(args[1]));// 具体路径从控制台输入
System.out.println(new Path(args[1]+"/part-r-00000"));
System.out.println(new Path(args[2]+"/part-r-00000"));
countjob.setReducerClass(CountReducer.class);
countjob.setOutputKeyClass(Text.class);
countjob.setOutputValueClass(IntWritable.class);
FileOutputFormat.setOutputPath(countjob, new Path(args[2]));
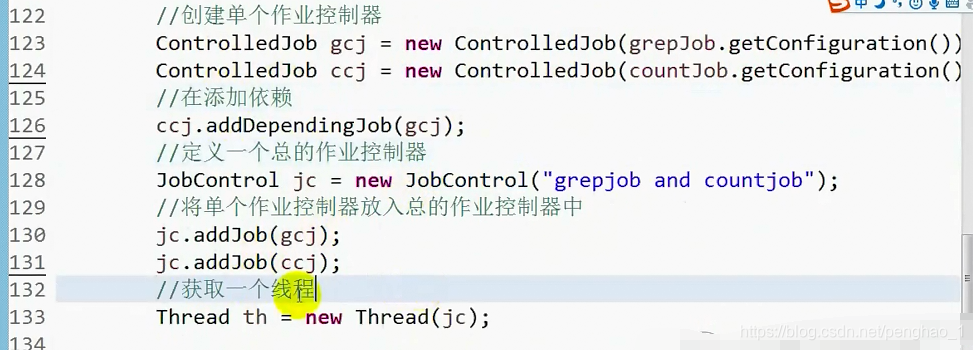
// 创建单个作业控制器
ControlledJob gcj = new ControlledJob(grepjob.getConfiguration());
ControlledJob ccj = new ControlledJob(countjob.getConfiguration());
// 再添加依赖
ccj.addDependingJob(gcj);
// 定义一个总的作业控制器
JobControl jc = new JobControl("grebjob and countjob");
// 将单个作业控制器放入总的作业控制器中
jc.addJob(gcj);
jc.addJob(ccj);
// 获取一个线程
Thread th = new Thread(jc);
// 启动线程
th.start();
// 判断job是否完全运行完成
if (jc.allFinished()) {
th.sleep(2000);
th.stop();
jc.stop();
System.exit(0);
}
}
}
MapReduce中的老版本API案例
老版本导入的包都是短包

有三四处不相同,右键导出jar包, 上传文件到home目录下面
![]()

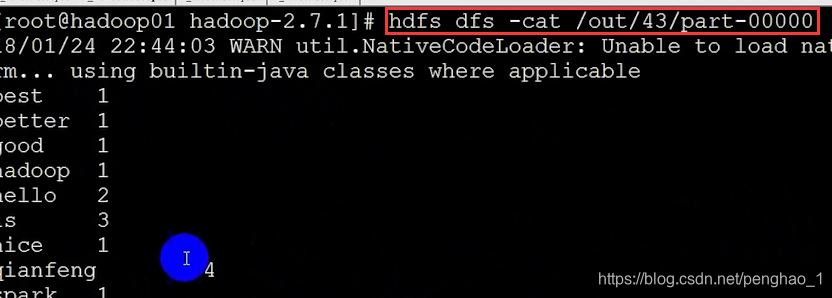
到此也就OK了。
package qf.com.mr;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.RunningJob;
/*
*类说明:hadoop 1.X的写法
*老版本
*/
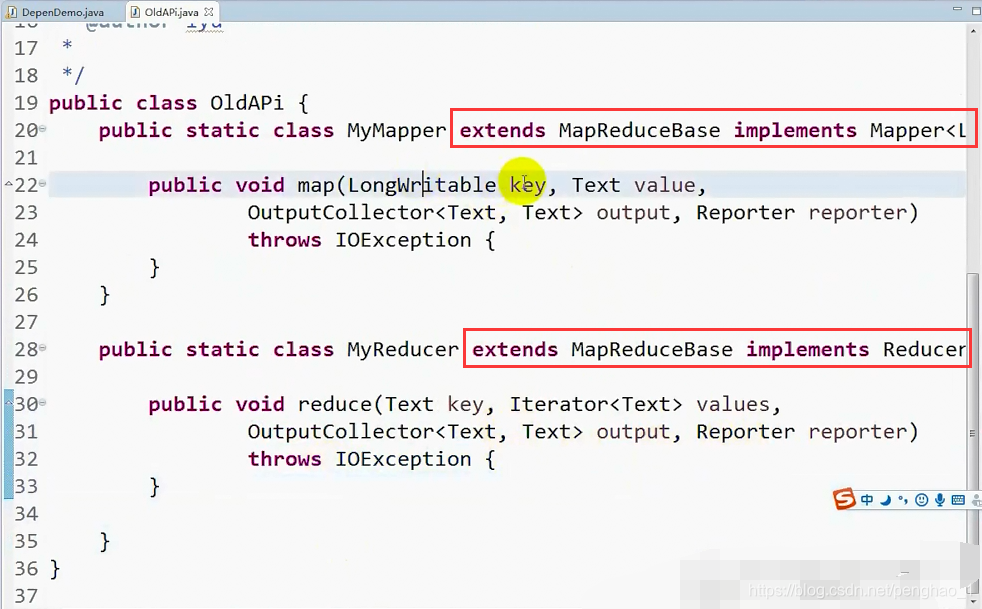
public class OldApi {
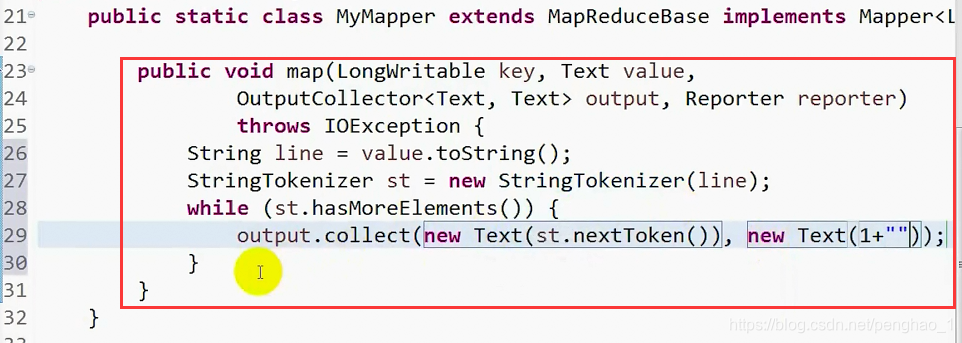
public static class MyMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, Text>{
public void map(LongWritable key, Text value, OutputCollector<Text, Text> output, Reporter reporter)
throws IOException {
String line = value.toString();
//StringTokenizer 这个类默认用空格或者\t来切分
StringTokenizer st = new StringTokenizer(line);
while(st.hasMoreTokens()) {
output.collect(new Text(st.nextToken()), new Text(1+""));
}
}
}
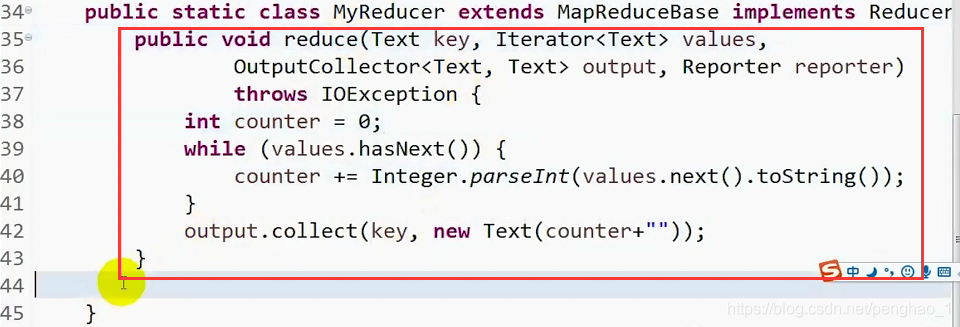
public static class MyReducer extends MapReduceBase implements Reducer<Text, Text, Text, Text>{
public void reduce(Text key, Iterator<Text> values, OutputCollector<Text, Text> output, Reporter reporter)
throws IOException {
int counter = 0;
while(values.hasNext()) {
counter += Integer.parseInt(values.next().toString());
}
output.collect(key, new Text(counter+""));
}
}
public static void main(String[] args) {
Configuration conf = new Configuration();
try {
JobConf job = new JobConf(conf);
job.setJarByClass(OldApi.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
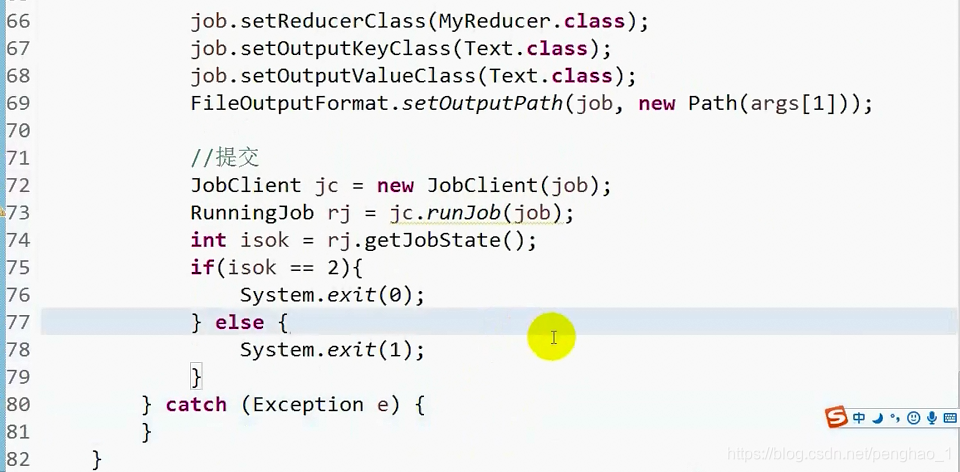
//提交
JobClient jc = new JobClient(job);
RunningJob rj = jc.runJob(job);
int isok = rj.getJobState();
if(isok == 2) {
System.exit(0);
}else {
System.exit(1);
}
} catch (Exception e) {
}
}
}

















 4095
4095

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









